作者 | 於相洋
在早期階段,vivo AI 計算平台使用 GlusterFS 作為底層存儲基座。隨著數據規模的擴大和多種業務場景的接入,開始出現性能、維護等問題。為此,vivo 轉而採用了自研的軒轅文件系統,該系統是基於 JuiceFS 開源版本開發的一款分布式文件存儲方案。
本文將介紹 vivo 軒轅文件系統在 JuiceFS 基礎之上開發的新特性。以及 vivo 針對一些關鍵場景,如樣本數據讀取速度慢和檢查點寫入環節的優化措施。此外,文章還將介紹 vivo 的技術規劃包括 FUSE、 元數據引擎及 RDMA 通信等方面,希望能為在大規模 AI 場景使用 JuiceFS 的用戶提供參考與啟發。
計算平台引入軒轅文件存儲的背景
最初,vivo 的 AI 計算平台 使用 GlusterFS ,並由該團隊自行維護。在使用過程中,團隊遇到了一些問題。一是處理小文件時速度變得非常緩慢;二是當需要對 GlusterFS 進行機器擴容和數據平衡時,對業務產生了較大的影響。
隨後,由於早期集群容量已滿且未進行擴容,計算團隊選擇搭建了新的集群。然而,這導致了多個集群需要維護,從而增加了管理的複雜度。此外,作為平台方,他們在存儲方面的投入人力有限,因此難以進行新特性開發。
他們了解到我們網際網路部門正在研發文件存儲解決方案,經過深入交流和測試。最終,他們決定將其數據存儲遷移至我們的軒轅文件存儲系統。
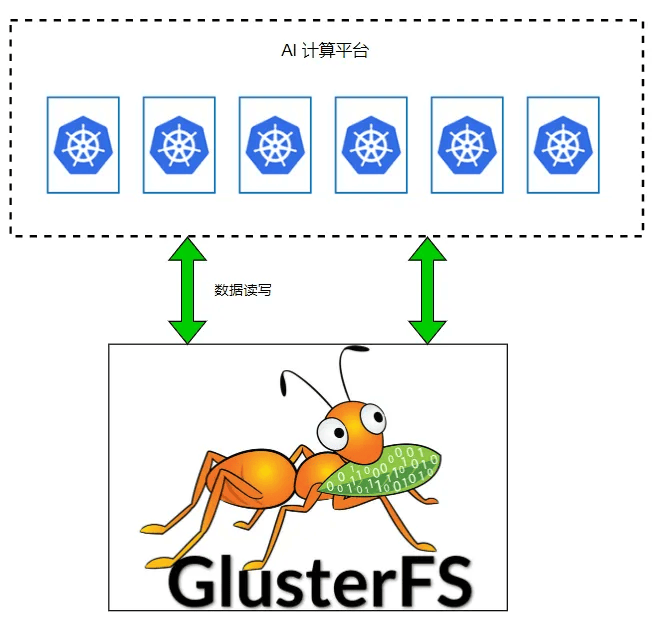
vivo 早期 AI 計算平台架構
軒轅文件系統基於 JuiceFS 開源版,進行了二次開發,支持多種標準訪問協議,包括 POSIX、HDFS 以及 Windows 上的 CIFS 協議。此外,我們還提供了文件恢復功能,該功能參考了商用解決方案,能夠按照原路徑進行數據恢復。
同時,我們的系統支持客戶端熱升級,這一功能在開源版本中也已經實現。另外,我們還支持用戶名權限管理,默認使用本地 uid/gid 進行鑒權。在此基礎上,我們還參考 JuiceFS 企業版實現了用戶名鑒權功能。
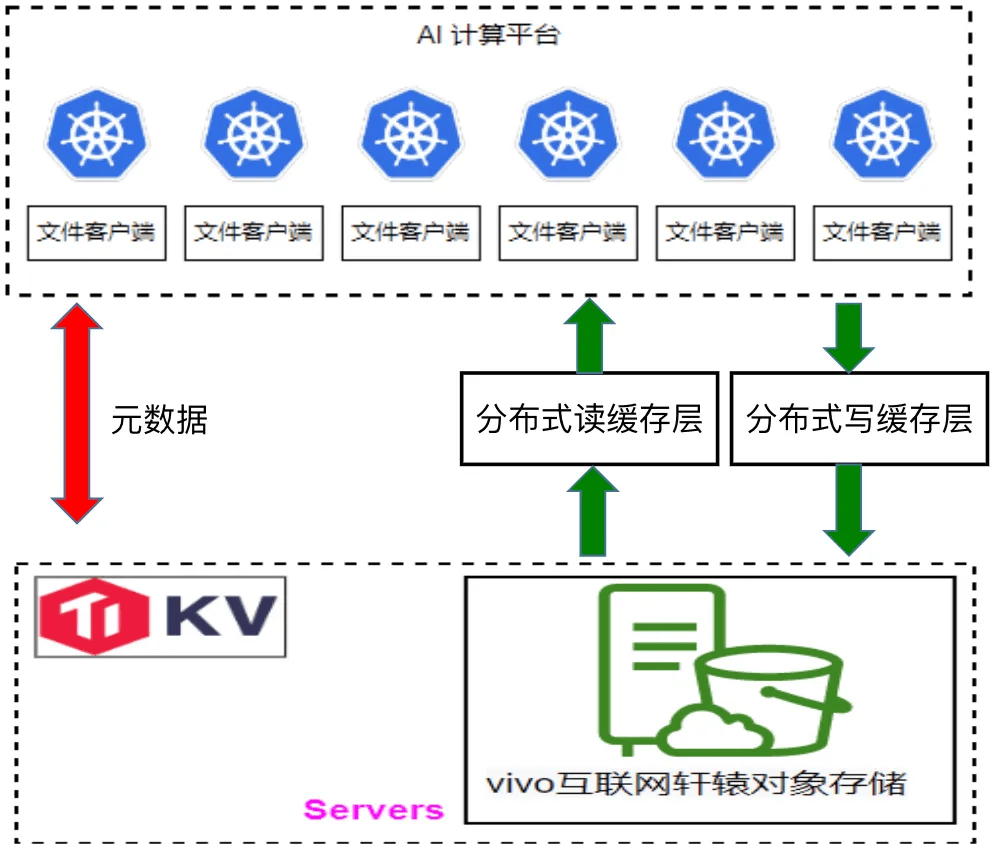
下圖是軒轅文件系統的架構圖,與 JuiceFS 類似。在底層基座方面,我們使用 TikV 存儲元數據,而數據則存儲在我們自研的對象存儲系統中。 特別值得一提的是,在 Windows 場景下,我們在 Samba 中開發了一個插件,該插件直接調用 JuiceFS API,從而為用戶提供了一個在 Windows 上訪問我們文件存儲的通道。
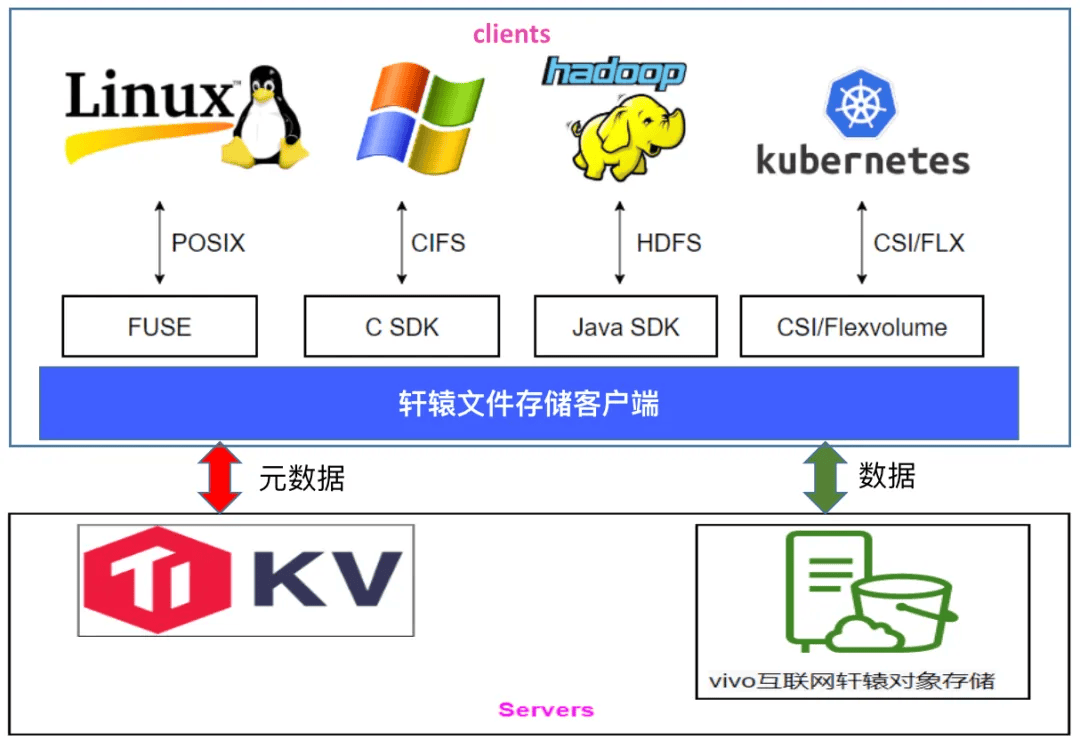
vivo 軒轅文件系統的架構圖
目前的 AI 計算平台存儲流程如下:首先獲取原始數據並通過一個包含 4 萬個批處理任務的系統進行處理,生成樣本庫。這些樣本庫隨後在 GPU 上訓練,產生模型文件,這些模型文件被傳輸至在線系統用於推理。原始數據及處理後的樣本庫直接存儲在軒轅文件系統中,由於其兼容 HDFS API,Spark 可以直接處理這些數據。模型文件也保存在軒轅中,並通過其提供的 CSI 插件,使在線推理系統能直接掛載並讀取這些文件。
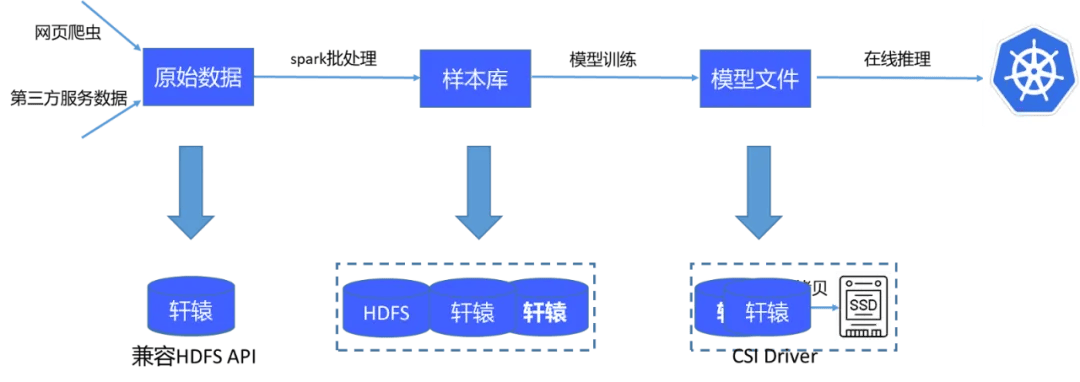
vivo AI 計算平台存儲方案
存儲性能優化
訓練階段涉及存儲的主要有兩個重要方面:樣本讀和訓練過程中的檢查點( checkpoint) 保存。
環節 1:加速樣本讀
為了提升樣本加載的速度,我們開發了一個分布式讀緩存層。在訓練模型前,我們藉助 JuiceFS 提供的 warm up 功能,優先將本次訓練所需的數據預加載至讀緩存層。通過這種方式,訓練數據可以直接從讀緩存層獲取,而無需從對象存儲系統中拉取。通常情況下,直接從對象存儲中讀取數據需要花費十幾至幾十毫秒,但通過讀緩存層則可將讀取時間縮短至 10 毫秒以內,從而進顯著提高了數據加載到 GPU 的 速度。
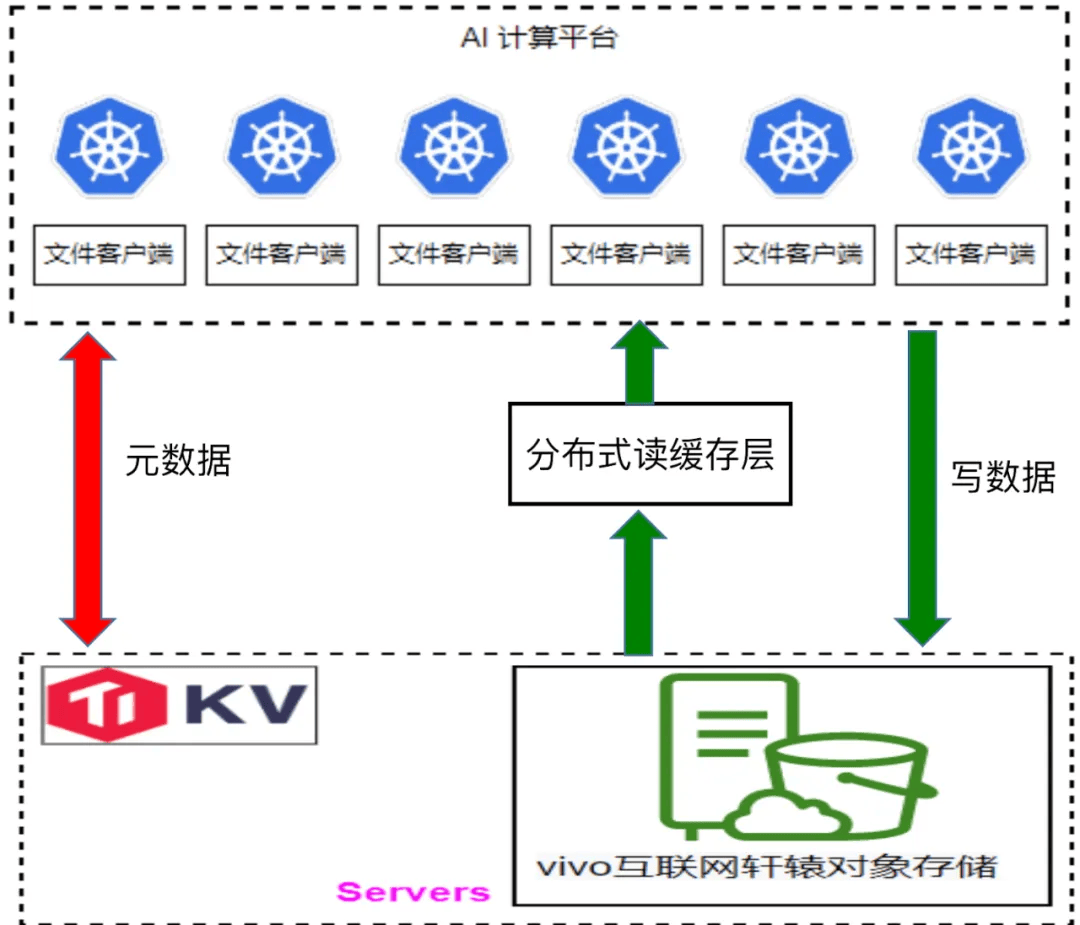
樣本加載環節
環節 2:檢查點 (Checkpoint) 寫入
在檢查點寫入方面,我們參考了百度的方案 [1]。具體而言,檢查點數據首先被寫入一個臨時緩存區域(我們稱之為「協管」區域,但此處可能指的是某種形式的中間緩存或暫存區),然後再逐步刷新到對象存儲中。在這個過程中,我們也採用了單副本模式,因為檢查點本身就是每隔一段時間保存的,即使某個時間段的檢查點丟失,對整體訓練的影響也是有限的。當然,我們也制定了一些策略來確保關鍵數據的安全性,並非所有數據都會進入這個中間緩存區域。通常,只有檢查點文件和訓練階段的日誌文件會被寫入。如果訓練中斷,檢查點文件可以從這個中間緩存區域中讀取。
檢查點寫入環節
此外,當數據被寫入並刷新到對象存儲中時,我們並不會立即從檢查點緩存中清除這些數據。因為訓練過程中隨時可能中斷,如果此時檢查點緩存中的數據被清除,而需要從對象存儲中重新拉取,將會耗費較長時間。因此,我們設置了一個 TTL(生存時間)機制。例如,如果檢查點數據每小時刷新一次到對象存儲中,我們可以將 TTL 設置為 1.5 小時。這樣,即使訓練中斷,我們也能確保檢查點緩存中有一個最新的備份可供使用。
在開發寫緩存的過程中,我們遇到了一個挑戰。由於我們的客戶端與寫緩存之間的通信採用 gRPC 協議,該協議在數據反序列化時會重新申請內存以存儲解析後的數據。在特定時間段內,如果寫操作非常集中(例如在幾十秒內),會導致大量的內存申請和釋放。由於我們使用的是 Go 語言開發,其垃圾回收(GC)機制在這種情況下表現較慢,可能會導致寫緩存的內存耗盡。
為了解決這個問題,我們調研了其他數據反序列化的方案。最終,我們採用了 Facebook 的 flatterbuffer 方案。與 gRPC 的 Pb 反序列化不同,flatterbuffer 在反序列化後可以直接使用數據,無需額外的解析步驟。通過這種方式,我們減少了內存的使用,與 Pb 相比,內存節省達到了 50%。同時,我們也對寫性能進行了測試,發現使用 flatterbuffer 後,寫性能提升了 20%
環節 3:在線推理,模型加載流量大
在用戶進行在線推理時,我們注意到模型下載產生的流量極大,有時甚至會占滿對象存儲網關的帶寬。深入分析這個場景後,我們發現存在眾多實例,每個實例都會獨立地將完整模型加載到內存中,並且這些實例幾乎是同時開始加載模型的,這一行為造成了巨大的流量壓力。
為解決此問題,我們借鑑了商業解決方案,採用了在 Pod 中實施邏輯分組的方法。在這種策略下,每個分組僅從底層存儲讀取一份完整模型,而分組內的各個節點則讀取模型的部分文件,並通過節點間的數據共享(類似於 P2P 方式)來減少總體流量需求。這種方法顯著降低了對底層對象存儲帶寬的占用,有效緩解了流量壓力。
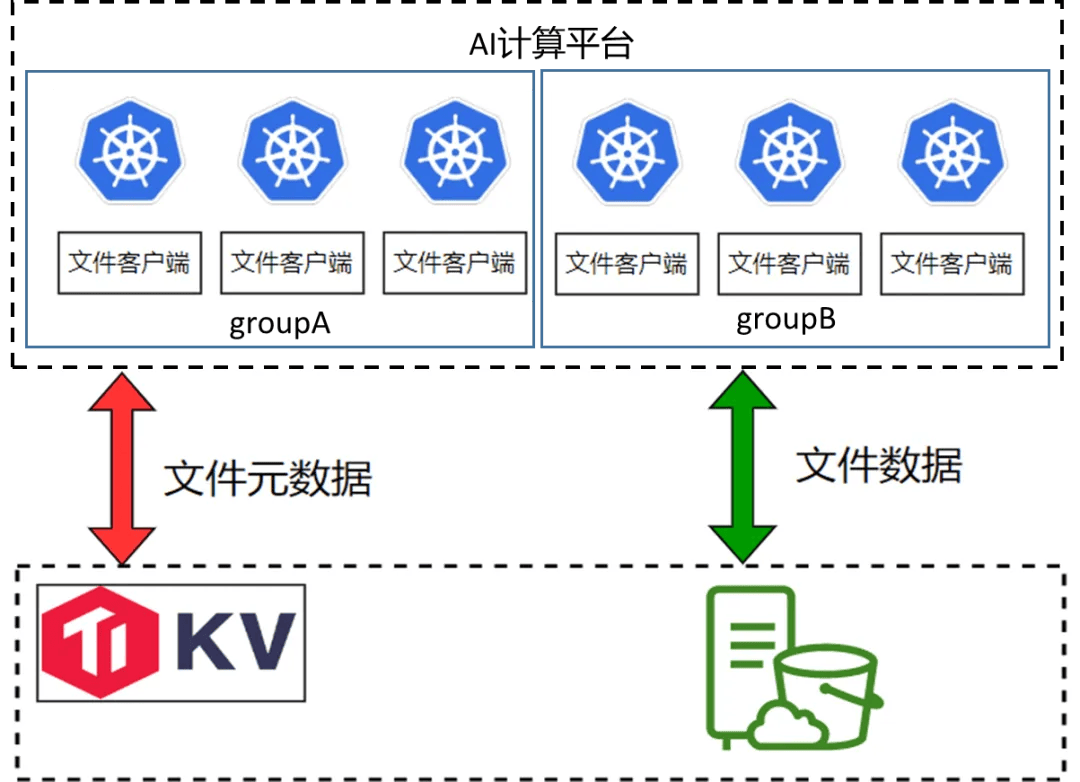
客戶端邏輯分組示意圖
技術規劃
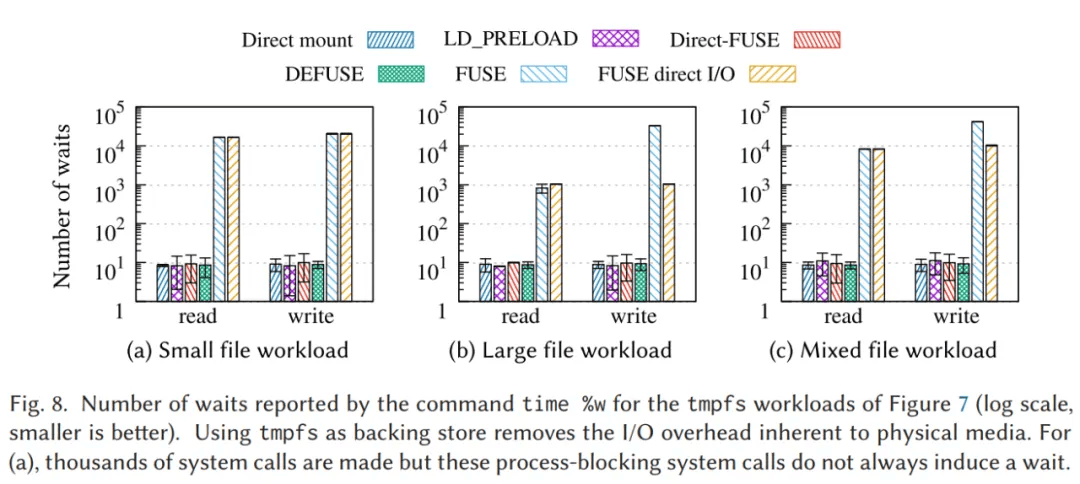
libc 調用繞過 FUSE 內核,提升讀寫性能 下面這份圖表來源於 ACM 期刊中的一篇論文。文中指出,在使用 FUSE 掛載時,請求的處理流程會先從用戶態轉移到內核態,然後再返回用戶態。在這個流程中,上下文切換所帶來的消耗是相當巨大的。
柱狀圖較高的部分代表原生的 FUSE,而柱狀圖較低的部分則代表經過優化的方案。
- 小文件場景:原生的 FUSE 相較於優化方案,其上下文次數切換的數量差距達到了 1000 倍;
- 大文件場景:原生的 FUSE 與優化方案之間的上下文次數切換的數量差距約為 100 倍;
- 混合負載場景:同樣顯示出了巨大的上下文次數切換的數量差異。
在論文中提到,鏈路消耗的主要來源是上下文切換。因此,我們計劃在 FUSE 這一層進行優化,主要針對元數據和小文件場景。目前,我們正在進行方案選型工作。
自研元數據引擎,文件語義下沉
我們還計劃開發一個自己的元數據引擎。當前,我們使用的元數據引擎是基於 TiKV 的,但 TiKV 並不具備文件語義,所有的文件語義都是在客戶端實現的。這給我們的特性開發工作帶來了極大的不便。
同時,當多個節點同時寫入一個 key 時,事務衝突也會非常頻繁。近期,我們還遇到了進程會突然卡住的問題,持續時間從幾分鐘到十幾分鐘不等。這個問題一直未能得到解決。
另外,TiKV PD 組件為主節點 Active 模式,請求上 10 萬後,時延上升明顯,PD 節點(112 核)CPU 使用率接近飽和。因此,我們正在嘗試一些方案來降低主節點的 CPU 利用率,以觀察是否能改善耗時問題。我們參考了一些論文,如百度的 CFS 論文 [2],將所有的元數據操作儘量變成單機事務,以減少分布式事務的開銷。
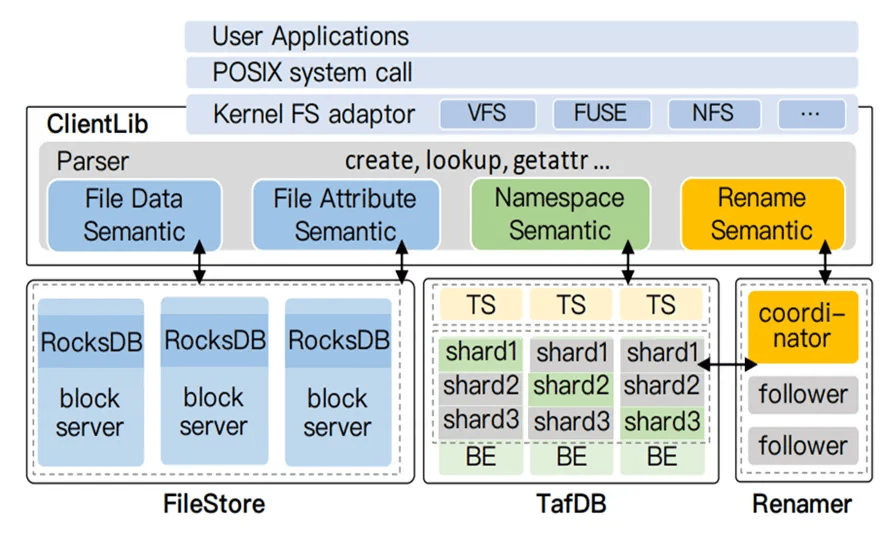
圖片來源:CFS: Scaling Metadata Service for Distributed File System via Pruned Scope of Critical Sections
緩存層實現 RDMA 通信
關於我們機房的 GPU 節點,它們目前使用的是 RDMA 網絡。與緩存層的通信仍然使用 TCP 協議。我們有規劃開發一個基於 RDMA 的通信方式,以實現客戶端與緩存之間的低延遲、低 CPU 消耗的通信。
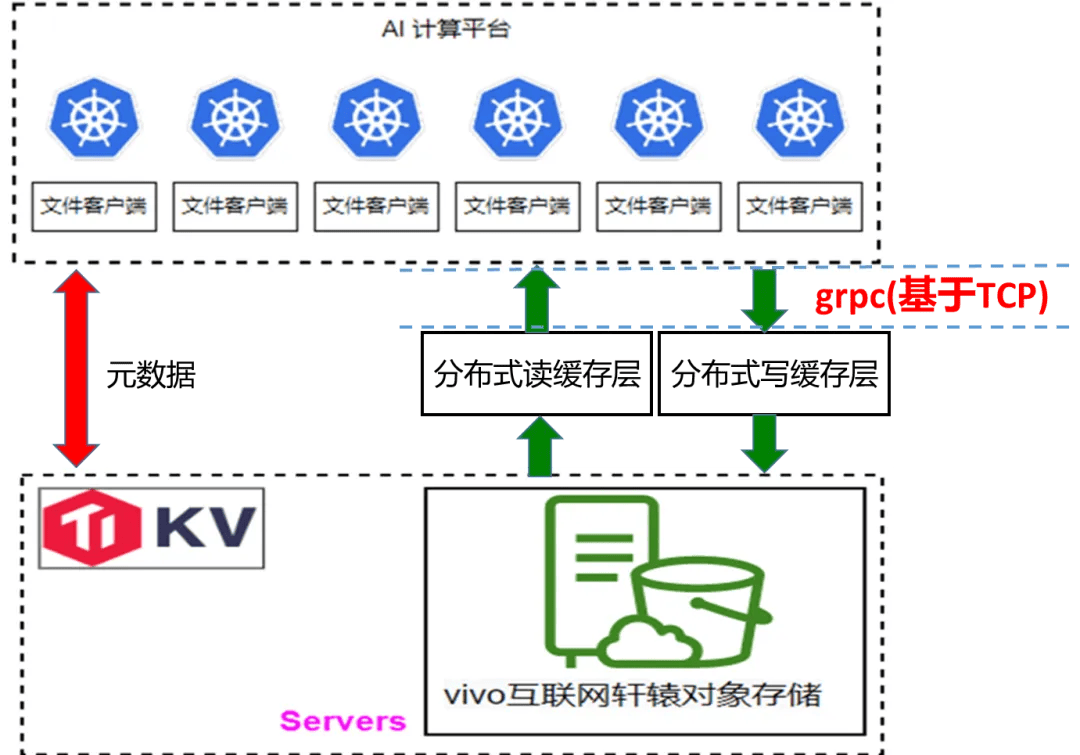
目前的緩存層通信示意圖
通過觀察客戶端的火焰圖,我們發現 RPC 通信的耗時仍然非常明顯。雖然寫緩存的處理數據只需要一兩毫秒,但客戶端將數據上傳到整個鏈路的耗時可能達到五六毫秒,甚至十毫秒。在客戶端 CPU 非常繁忙的情況下,這個時間可能會達到二三十毫秒。而 RDMA 本身並不怎麼消耗 CPU,內存消耗也比較少,因此我們認為這是一個值得嘗試的解決方案。
引用連結
本文作者