作者 | Mikkel Dengsøe
譯者 | Sambodhi
策劃 | Tina
導讀:隨著數據行業的蓬勃發展,構建高效且頂尖的數據團隊結構及其角色分配已成為業界矚目的焦點。本期專欄深度剖析如何布局數據團隊,揭示不同企業在數據角色劃分與團隊構成上的獨到之處。通過細緻分析 40 個頂尖數據團隊的案例數據,我們將為你揭示洞察分析師、數據工程師與機器學習專家的比例奧秘,並探討如何根據企業規模靈活調整團隊架構。無論你是數據領域的從業者,還是對高效數據管理充滿好奇的讀者,本文都將為你提供寶貴的洞見與實用的策略指導。讓我們攜手揭開數據團隊成功背後的智慧密碼,共同探索最佳實踐之道。
隨著數據團隊的日益壯大,成員數量顯著增加。這通常被視為積極信號,因為數據團隊如今已不僅限於驅動關鍵商業數據產品的開發,更超越了單純回應臨時查詢的職能範疇。然而,這樣的擴張也催生了一系列值得深思的問題,比如「我們在基礎設施投入與數據洞察產出之間是否維繫了恰當的平衡?」以及「鑒於我們所取得的成就,我們的運營效率是否達到了行業內的標準水平?」
本文旨在深入剖析美國和歐洲地區 40 個頂尖數據團隊中各類數據角色的配置情況,為你解答上述疑惑,提供有價值的洞見。
數據角色分類
在數據領域,角色的命名可謂五花八門,儘管職位名稱的多樣性並不限制數據工作的本質,但我們可以大致將這些角色歸為以下幾大類別:
- 洞察與分析:此類別涵蓋了數據分析師、產品分析師以及數據科學家。他們共同負責從數據中挖掘價值,提供深入的業務見解。
- 數據工程:數據工程師、數據平台工程師、分析工程師以及數據治理專家等角色構成了這一領域。他們專注於構建和維護數據基礎設施,確保數據的可靠性與可用性。
- 機器學習:機器學習工程師是這一類別中的核心,他們利用算法和模型,從數據中學習並自動改進預測、分類等任務。
值得注意的是,數據團隊中的角色定義往往不夠明確,這不僅使得跨公司之間的角色比較變得複雜,也讓求職者在面對不同公司時難以準確把握職位的具體期望。例如,「數據科學家」這一稱謂,在某些公司可能指代的是專注於研究與機器學習的高級人才,而在另一些公司則可能只是分析師的另一種說法。
此外,雖然公司內存在眾多分析師角色,如財務分析師、信用分析師等,但這些角色通常並不直接隸屬於數據團隊,因此在我們的分析框架中,我們僅將數據分析師和產品分析師納入數據團隊的範疇。至於機器學習角色的歸屬問題,儘管不同公司的組織架構各異,有的將其置於工程部門,有的則歸於數據部門,但為了便於討論,我們將機器學習角色統一視為數據團隊的重要組成部分。
頂級公司數據角色構成剖析
在數據團隊建設的討論中,洞察角色與數據工程角色的比例問題常常成為焦點。過度偏重洞察角色可能會削弱數據平台的質量,進而拖慢整體工作效率;而過度依賴數據工程師,則可能導致擁有頂尖的數據平台卻缺乏推動業務增長的深刻洞察或創新數據產品。
根據我們對 40 個頂級數據團隊的調研,洞察角色的中位比例達到了 46%,略高於數據工程角色的 43%。
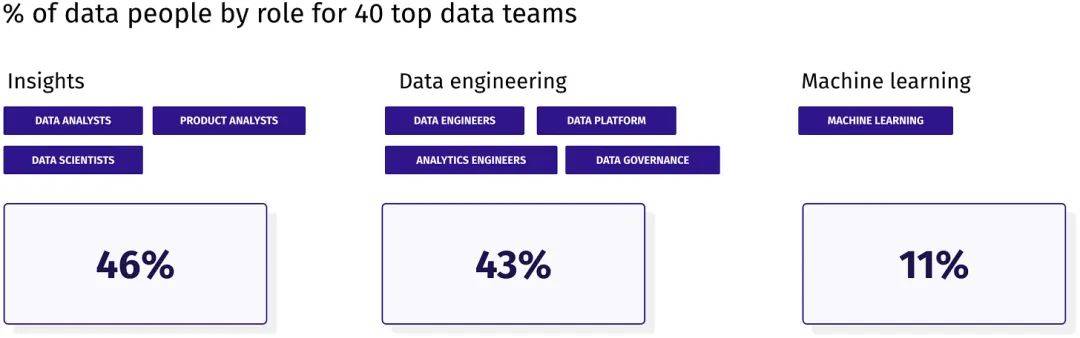
值得注意的是,這些比例因公司而異,部分原因在於角色命名的語義差異。有些公司避免使用「分析師」這一稱謂,轉而統稱所有相關人員為「數據科學家」。而另一些公司則對數據工程師和分析工程師的職責界限有著不同的理解。因此,分析工程師比例較低的公司,並不意味著在數據建模方面的投入就相對較少,這些工作可能已被整合進了分析師的日常職責之中。
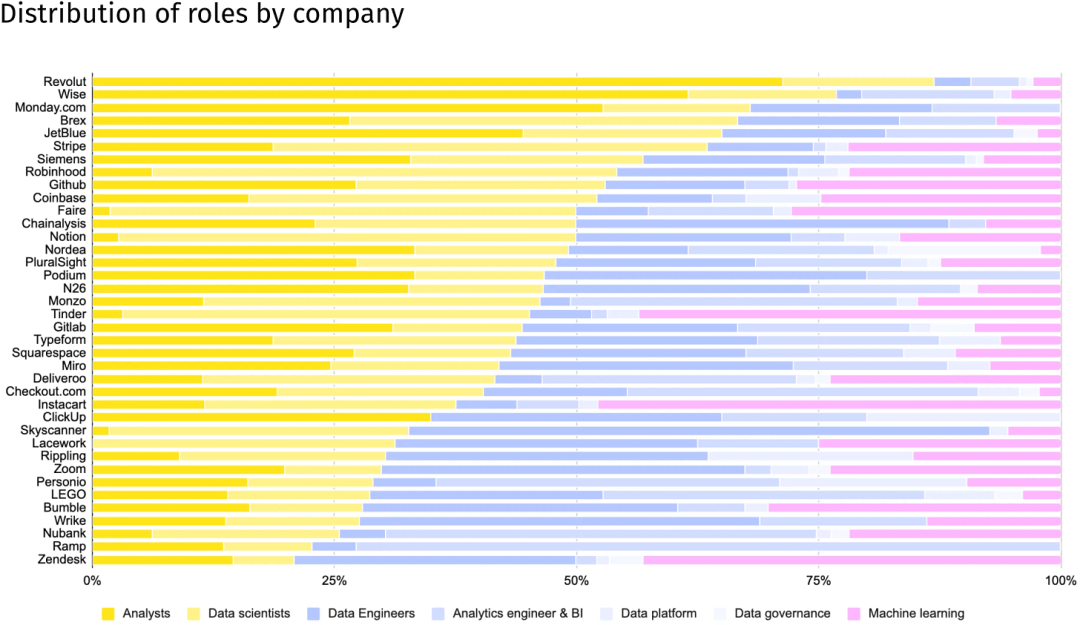
在比較不同公司的數據團隊構成時,我們需要格外謹慎。通過具體案例,我們可以更清晰地看到,最佳比例往往因公司的戰略重點和業務需求而異。
- Revolut 擁有眾多分析師,他們分布在各個市場,專注於金融犯罪預防和信用評估等領域。
- Zendesk 則擁有一個龐大的機器學習團隊,這與公司近期定位為「AI 時代最全面的客戶體驗解決方案提供商」的戰略方向高度契合。
- Nubank 則將數據分析師統一更名為分析工程師,這一舉措彰顯了公司致力於在所有業務領域深入應用軟體工程原則和數據建模技術的決心。
若欲深入了解更多關於數據團隊建設的最佳實踐,請參閱以下文章:《數據團隊占員工比例:100 家科技公司的深度剖析》(Data team as % of workforce: A deep dive into 100 tech scaleups)和《50 家科技公司中數據與產品工程師比例揭秘》)(data and product to engineer ratio at 50 tech scaleups)。
按公司規模劃分的數據團隊構成解析
不同規模的公司,其業務重點與數據團隊的構成往往呈現出鮮明的差異。對於正處於成長階段的公司而言,快速決策與新產品的迅速推向市場可能是它們最為關注的;而剛剛完成 IPO 的成熟企業,則可能將重心放在確保報告的精確性、合規性以及數據安全性上。
為了更清晰地揭示這些差異,我們可以將公司按照其規模劃分為三個層次進行深入探討:
- 中型公司:這類公司正處於快速發展期,數據團隊規模相對較小,通常少於 35 人。它們中的典型代表有 Typeform、Brex 和 Personio 等。
- 大型公司:這類公司接近 IPO 階段,數據團隊規模在 35 至 100 人之間,如 Notion、Miro 和 N26 等企業便屬於此類。
- 規模型企業:這一類別涵蓋了更大規模的成長型企業、上市公司以及數據團隊人數超過 100 人的大型企業,Zendesk、LEGO 和 Nubank 均屬於其中的佼佼者。
在探討這些不同規模公司的數據團隊構成時,有兩個觀察點尤為值得關註:
此外,我們還注意到一個有趣的現象:在大型公司中,有 60% 的公司設立了專門的數據治理職能,而在其他規模的公司中,這一比例僅為 20%。這進一步印證了大型公司在數據管理和運營上的成熟度,它們更傾向於採用結構化的方法來確保數據的高效運作(DataOps)。
總 結
通過對 40 個頂級數據團隊的數據角色分布進行深入分析,我們將數據角色大致劃分為三類:洞察(包括數據分析師、產品分析師和數據科學家)、數據工程(涵蓋數據工程師、數據平台工程師、分析工程師及數據治理人員)以及機器學習(專注於機器學習工程師)。各類角色的中位比例分別為:洞察 46%,數據工程 43%,機器學習 11%。但需要強調的是,這些數字僅供參考,因為不同公司對於數據角色的定義和劃分可能存在顯著差異。我們得出的結論是,並不存在一種適用於所有公司的通用比例。最佳的數據團隊構成應根據公司的業務重點、發展階段及規模大小進行靈活調整。
作者簡介:
Mikkel Dengsøe,Synq(http://www.synq.io)聯合創始人。
原文連結:
https://mikkeldengsoe.substack.com/p/how-top-data-teams-are-structured
剝離幾百萬行代碼,複製核心算法去美國?TikTok 最新回應來了
微信淘寶小紅書等 67個 App 啟動「網絡身份證」試點;蘇州佳能N+12補償?Transformer 作者回流谷歌 | Q資訊
繼裁掉 Python 團隊後,谷歌 Go 團隊也迎來動盪:團隊靈魂人物、領導 Go 十二年的技術負責人突然宣布退位
開發者怒了!亞馬遜雲突然「變臉」,不賺錢應用遭淘汰,沒有正式通知引眾怒