作者 | Madan Thangavelu
譯者 | 明知山
策劃 | Tina
在大規模分布式系統中,將關鍵系統從一種架構遷移到另一種架構,不僅在技術層面存在挑戰性,還需要一個精細的遷移過程。Uber 運營著全球最複雜的實時履約系統之一。本文將介紹 Uber 如何將工作負載無縫地從本地環境遷移到混合雲架構,並實現零停機時間和最小的業務影響。
系統複雜性
Uber 的履約系統是一個具備實時性、一致性和高可用性的系統。用戶持續不斷地與應用程式發生互動,如發起新行程、取消已有行程和修改行程細節。
餐廳不斷更新訂單狀態,快遞員在繁忙的城市中穿梭,確保包裹能夠及時送達。系統每秒鐘處理超過兩百萬次交易,高效地管理著平台上用戶和行程的狀態。
我是將這個履約系統從本地架構遷移至混合雲架構的技術負責人。除了開發新系統所需的代碼並進行驗證之外,最具挑戰性的部分是設計一個可以實現零停機時間並將對客戶影響減少到最小的遷移策略。
舊系統架構
讓我來概述一下原有的履約系統。它由多個服務構成,這些服務在內存中維護用戶和行程實體的實時。此外還有一些輔助服務負責處理鎖定機制、搜索功能和數據存儲,確保系統能夠跨數據中心進行數據複製。
所有的乘客端交易都被定向到「需求」服務,而所有的司機端交易被定向到「供應」服務。這兩個系統通過分布式事務技術來保持同步。
這些服務以 pod 的形式運行。一個 pod 就是一個自給自足的單元,內部的服務相互交互,共同為特定城市的履約活動提供支持。一個請求進入一個 pod,通常會在這個 pod 的內部服務之間流轉,除非需要訪問 pod 外部的服務數據。
在下圖中,綠色和藍色服務組分別代表兩個不同的 pod,每個 pod 包含了所有服務的副本。城市 1 的流量被路由到 pod1,城市 2 的流量被路由到 pod2。
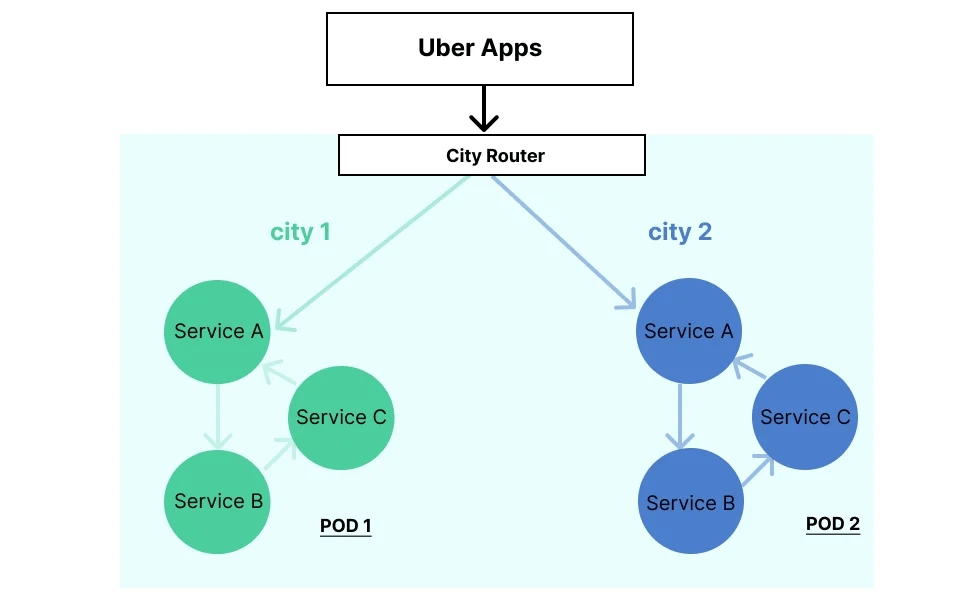
此外,該系統還通過採用 saga 模式促進了 A、B 和 C 服務之間的分布式事務,確保了它們存儲的實體數據保持同步。通過內存數據管理和序列化技術,每個服務內部的實體數據一致性得到了有效的保證。
這個系統在 Uber 的早期發展階段就進行了擴展。它採取了一些架構決策,這些決策可能更貼合 Uber 不斷增長的業務需求。首先,系統被設計為優先考慮可用性而非一致性。也就是說,在多個系統中保存了不同的實體,系統最終能夠達到一致狀態,但並沒有通過真正的 ACID 兼容系統來管理跨系統的變更。由於所有數據都存儲在內存中,系統在垂直擴展和特定服務的節點數量方面存在固有的限制。
重新設計的系統
新系統減少了服務數量。原本處理「需求」和「供應」等實體的服務被合併到一個由雲數據存儲提供支持的單體應用程式中。所有的事務管理的責任都被轉移到了數據存儲層。
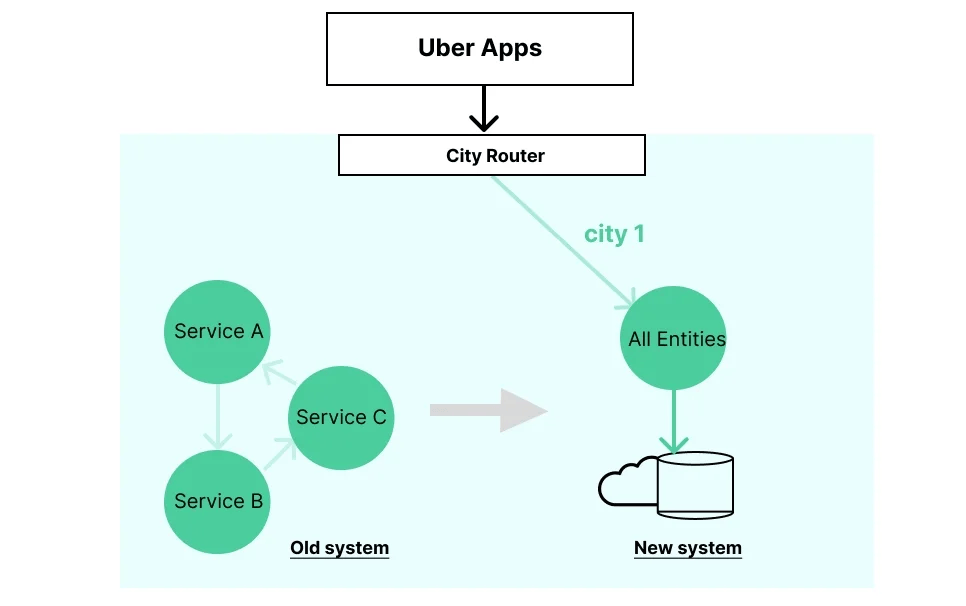
新系統和已有的服務消費者
對於這種關鍵系統的遷移,需要一個全面的多維策略來覆蓋遷移的方方面面。在微服務環境中,每個系統都與周圍的許多系統進行著複雜的交互。交互主要通過兩種方式進行:API 和發布到消息總線中的事件。
新系統修改了所有的核心數據模型、API 契約和事件模式。因為有數百個 API 調用者和系統消費者,所以不可能一次性遷移完畢。我們採取了一種「向後兼容層」的策略,保持現有 API 和事件契約不變。
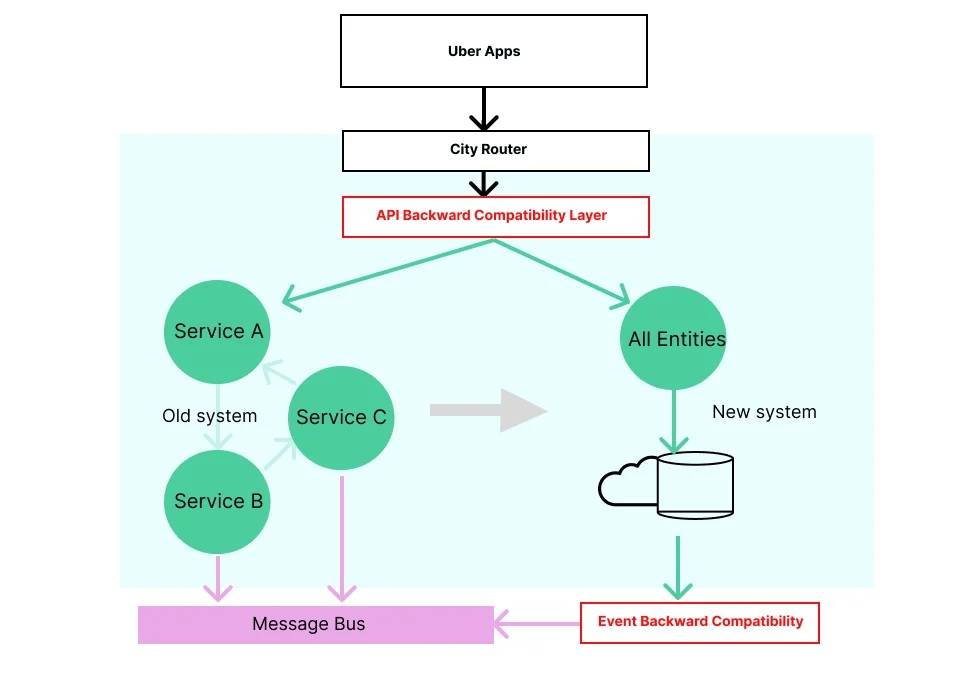
創建一個向後兼容層使得系統可以在不中斷現有消費者使用舊接口的情況下進行重新架構。在接下來的幾年中,消費者可以根據自己的節奏逐步遷移到新的 API 和事件模式,不必與整個系統的重新設計緊密耦合。同樣,舊系統的事件消費者也將繼續通過向後兼容層以舊模式接收事件。
實體的生命周期
這個過程的複雜性在於不斷變化的實體狀態。以系統中的三個關鍵實體——乘客、司機和行程為例,它們可以在不同的時間點開始和停止。舊系統將這些實體存儲在不同的內存系統中,而新系統必須在資料庫中反映這些變化。

遷移過程的一個主要挑戰是確保在過渡期間,每個實體的狀態及其相互關係都能被保留,並且能夠適應高頻率的變化。
遷移策略
在遷移的每個階段——發布之前、發布期間和發布之後——都必須採用多種策略,確保流量能夠平穩地從現有系統轉移到新系統。我將在文章的後續部分進行詳細的討論。
發布之前
影子驗證
確保新舊系統間的 API 契約一致性至關重要,這有助於建立信心,保證新系統與現有系統的一致性。引入向後兼容性驗證層可以確保舊系統和新系統之間 API 和事件的一致性。
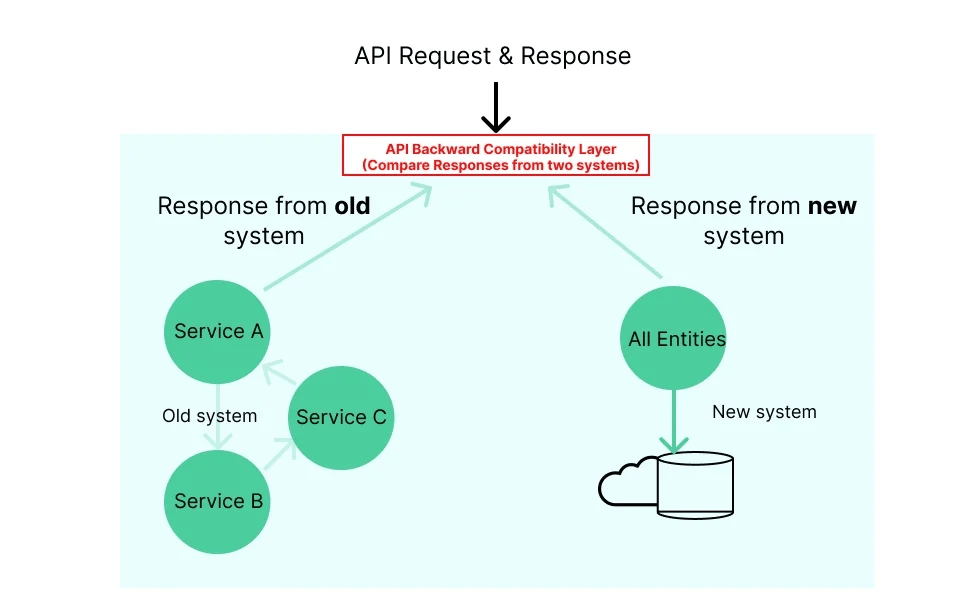
每個請求都會被發送給舊系統和新系統。兩個系統對請求的響應將根據鍵值進行比較,差異被記錄到一個可觀測性系統中。在每次發布之前,我們的目標是確保兩個系統的響應完全一致。
在實時系統中確實存在一些細微的差別。特別是在即時系統中,並非所有調用都會成功並獲得確切的響應。一種策略是將所有成功的調用視為一個具有高匹配率的群組,並確保大多數 API 調用都是成功的。在某些有效的情況下,對新系統的調用可能會失敗。例如,當司機請求離線 API,而新系統中沒有該用戶的上線記錄,可能會出現客戶端錯誤。對於這些邊緣情況,我們可以暫時忽略一致性不匹配的問題,但同時需要保持警惕。
此外,只讀 API 的一致性是最容易實現的,因為它們沒有副作用。對於寫入 API,我們引入了一個系統,舊系統會在共享緩存中記錄請求響應,新系統會重放這些響應。因為我們有跟蹤標頭,新系統可以透明地獲取舊系統最初接收的響應,並將它們從緩存中傳輸到新系統,而不是進行全新的外部調用。我們因此可以在不受外部依賴影響的情況下更好地匹配新舊系統的行為,在響應和欄位方面實現更高的一致性。
端到端集成測試
大規模重構是提高端到端(E2E)測試覆蓋率的一個好時機。這樣可以確保新系統在流量增長和新代碼部署時的穩定性。在此次遷移過程中,我們將測試用例數量增加至 300 多個。
端到端測試應在開發生命周期的多個關鍵節點執行:在工程師編寫代碼時、在構建過程的預部署驗證階段、以及在生產環境中持續進行。
金絲雀黑盒測試
為了最小化潛在的負面影響,可以先只將代碼暴露給一小部分請求,避免不良代碼造成廣泛影響。為了進一步優化策略,可以只在預生產環境中部署代碼,並在這個環境中持續執行端到端測試。只有在金絲雀測試環境成功通過所有測試後才允許部署系統繼續推進到生產環境。
負載測試
在將大量生產負載轉到新系統之前,必須進行全面的負載測試。由於我們能夠通過向後兼容層將流量重定向到新系統,所以可以將全生產流量轉到新系統。此外,我們編寫了自定義負載測試腳本來驗證包括資料庫和網絡系統在內的獨特集成點。
預熱資料庫
雲服務供應商的資料庫和計算資源擴展通常不是即時完成的。在面對突然增加的負載時,系統的擴展可能跟不上需求。在分布式數據存儲環境中,數據的再均衡、壓縮和分區拆分可能會引發熱點問題。為了應對這些挑戰,我們通過模擬合成數據負載實現了一定程度的緩存預熱和分區拆分。這樣可以確保在生產流量流向這些系統時系統能夠平穩運行,無需突然進行系統擴展。
回退網絡路由
由於應用程式和資料庫系統分別部署在兩個不同的雲平台上,且一個在本地,另一個在雲端,因此管理網絡拓撲就變得尤為重要。兩個數據中心至少建立了三條網絡路由,並通過專有網絡連接資料庫。用超過三倍正常容量的流量對這些網絡進行驗證和負載測試,確保在生產環境中即使在高負載條件下網絡連接也能保持穩定和可靠。
發布期間
流量固定
多個應用程式在相同的行程中相互協作,司機和乘客的行程代表同一個行程實體。當 API 調用從乘客端轉移到新系統時,相關的行程和司機狀態也必須從舊系統中遷移出來。我們已經實現了路由邏輯,確保行程能夠持續進行並在同一個系統中完成。為此,我們在遷移執行前約 30 分鐘開始記錄所有消費者的標識符,確保相關實體的請求會被鎖定在同一系統中。
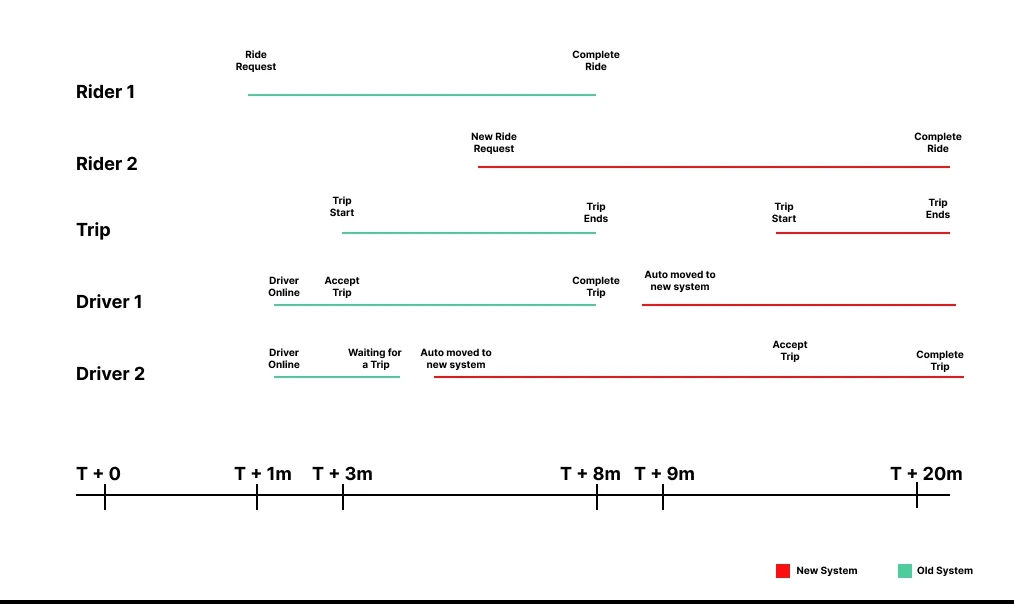
分階段發布
我們對選定城市的首批遷移行程進行了端到端測試。隨後,我們將非活躍行程中的空閒乘客和司機遷移至新系統。遷移完成後,所有新的行程都只在新系統中啟動。在這一過渡期間,兩個系統並行提供服務。隨著舊系統中的行程逐漸結束,乘客和司機也將逐步遷移至新系統。在一小時內,整個城市的服務完全轉移到新系統。若新系統出現故障,我們可以執行相同的遷移流程,反向將服務遷移回舊系統。
發布之後
可觀測性和回滾
在兩個系統間進行切換時,確保健壯的跨系統可觀測性至關重要。為此,我們開發了一個儀錶盤,它能夠實時顯示流量逐漸從舊系統遷移到新系統。
我們的目標是在遷移過程中確保關鍵業務指標——行程量、可用供應、行程完成率和行程開始率——保持穩定。這些聚合指標應該在遷移過程中保持平穩,儘管在遷移的關鍵時刻舊系統與新系統的混合比例可能會發生變化。
由於 Uber 在數千個城市運營,並提供眾多功能,因此,對這些指標進行城市級別的細緻觀察至關重要。在遷移數百個城市的過程中,手動監控所有指標是不現實的。我們必須開發專門的工具來自動監控這些指標,並能夠突出顯示那些顯著偏離正常範圍的指標。簡單的警報系統也是無效的,因為大量沒有根據每個城市的流量特點進行適當調整的無效警報會削弱對遷移過程的信心。因此,我們需要一個靜態工具來深入分析每個城市的健康狀況,確保所有城市在遷移過程中的平穩運行。
如果一個城市顯示出不健康的跡象,我們可以選擇只將該城市回滾到舊系統,而讓其他城市繼續運行在新系統中。
生產環境黑盒測試
與「金絲雀黑盒測試」策略類似,我們應該持續在生產系統上運行相同的測試,以便及時發現潛在問題。
成功遷移的關鍵要素
確保舊系統擁有充足的運行時間至關重要,這有助於我們專注於新系統開發而不受干擾。在著手新系統開發之前,我們花了四個月時間來提升舊系統的穩定性。跨項目規劃至關重要,我們先在舊系統中開發功能,隨後,在新系統開發過程中,這些功能在兩個系統中並行開發,最後在在新系統中開發。為了避免長期同時維護兩個系統,這種平衡策略至關重要。
在遷移關鍵系統時,確保這些系統具備強大的一致性保障,這是保證業務連續性的關鍵。40% 左右的工程資源應該放在新架構的可觀測性、遷移工具和強大的回滾機制上。
關鍵技術要素包括:對 API 流量的全面控制,精確到單個用戶級別;強大的欄位級一致性;影子匹配機制;健壯的跨系統可觀測性。在遷移過程中,我們需要面對充滿競態條件和特殊處理的情況,可能需要明確的業務邏輯或產品開發策略來應對。
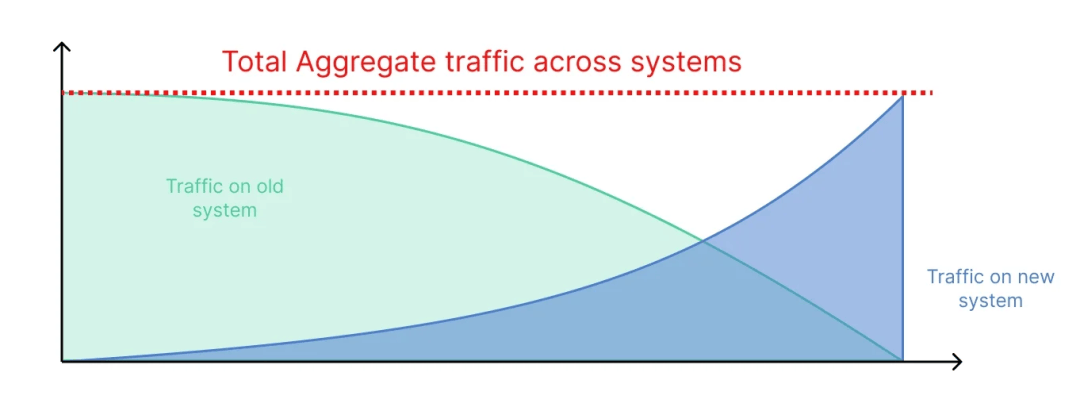
流量向新系統的遷移在開始時保持平穩,並在疊代中逐漸增長。隨著對新系統的信心增強,流量遷移往往會呈現出指數級的加速,如下圖所示。

提前加速遷移的挑戰在於,你可能會陷入同時維護兩個同等重要的系統,這需要更長時間的維護。由於新系統規模的擴大,任何中斷都可能對生產用戶造成重大影響。因此,最佳策略是在將流量遷移到新系統之前,先對最小數量的功能集進行驗證,在一段時間內保持穩定,然後在較短時間內快速增加流量遷移。
在 Uber,我們在開發和遷移過程中僅影響了不到幾千名用戶。本文所討論的技術是我們從舊系統平穩過渡到新系統的關鍵。
查看英文原文:
https://www.infoq.com/articles/uber-migration-hybrid-cloud/
剝離幾百萬行代碼,複製核心算法去美國?TikTok 最新回應來了
《黑神話:悟空》的第二個受害者出現了,竟是AI搜索惹的禍!
拖欠半年工資沒發,員工拿飲水機抵錢!又一家明星智駕獨角獸燒光 10 多億後黯然離場
《黑神話:悟空》開發者被獵頭瘋搶,聯創發聲求放過:你們不缺人才,別搞我們