作者 | Claudio Masolo
譯者 | 張衛濱
策劃 | 丁曉昀
最近,優步在其官方工程博客上發布了一篇 文章,闡述了將批數據分析和機器學習(ML)訓練的技術棧遷移到 谷歌雲平台(GCP) 的戰略。優步運行著世界上最大的 Hadoop 裝置之一,在兩個區域的數萬台伺服器上管理著超過上艾位元組(exabyte)的數據。開源數據生態系統,尤其是 Hadoop,一直是數據平台的基石。
遷移計劃的戰略包括兩個步驟,即初始遷移和利用雲原生服務。優步的初始戰略包括利用 GCP 的對象存儲作為數據湖存儲,同時將數據技術棧的其他部分遷移到 GCP 的基礎設施即服務(IaaS)上。這種方式可以實現快速遷移,並將對現有作業和流水線的影響降至最低,因為他們可以在 IaaS 上複製其內部軟體棧、引擎和安全模型的對應版本。在此階段之後,優步工程團隊,計劃逐步採用 GCP 的平台即服務(PaaS)產品,如 Dataproc 和 BigQuery,以充分利用雲原生服務的彈性和性能優勢。
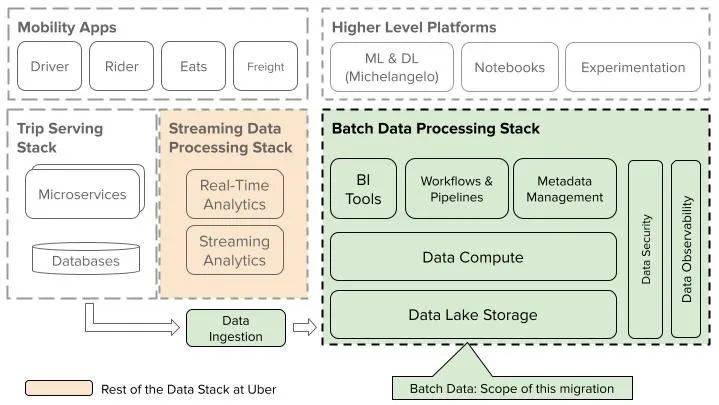
遷移的範圍(圖片來源:優步博客)
初始遷移完成後,團隊將重點集成雲原生服務,以最大程度地提升數據基礎設施的性能和可擴展性。這種分階段的方式能夠確保優步的用戶(從儀錶盤的所有者到 ML 的參與者)在不改變現有工作流或服務的情況下體驗無縫遷移。
為了確保平滑和高效的遷移,優步團隊制定了幾項指導原則:
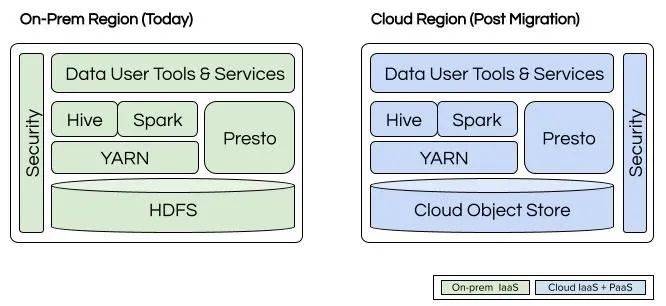
遷移前和遷移後的優步批數據技術棧(圖片來源:優步博客)
優步團隊重點關注遷移過程中的數據桶映射和雲資源布局。將 HDFS 文件和目錄映射到一個或多個桶中的雲對象至關重要。他們需要在不同的粒度水平上應用 IAM 策略,同時要考慮對桶和對象的限制,比如讀 / 寫吞吐量和 IOPS 限流。團隊的目標是開發一種映射算法,以滿足這些約束條件,並按照以組織為中心的層級方式組織數據資源,從而改進數據的管理。
另外一個工作方向是安全集成,調整現有的基於 Kerberos 的令牌和 Hadoop Delegation 令牌,使其適用於雲 PaaS,尤其是谷歌雲存儲(Google Cloud Storage,GCS),這是非常重要的。這個工作方向旨在支持無縫的用戶、群組和服務帳戶的認證與授權,並保持與內部環境一致的訪問級別。
團隊還關注數據複製。權限感知的雙向數據複製服務 HiveSync 能夠讓優步以雙活模式運行。他們擴展了 HiveSync 的功能,以便於將內部環境中數據湖的數據複製到基於雲的數據湖和對應的 Hive Metastore 中。這包括初始的批量轉移和持續的增量更新,直到基於雲的技術棧成為主方案。
最後一個工作方向是在 GCP IaaS 上提供新的 YARN 和 Presto 集群。在遷移過程中,優步的數據訪問代理會將查詢和作業流量路由至這些基於雲的集群,確保平穩遷移。
優步向谷歌雲的大數據遷移將面臨一些挑戰,比如存儲方面的性能差異和遺留系統所導致的難以預知的問題。團隊計劃通過使用開源工具、利用雲彈性進行成本管理、將非核心用途遷移到專用存儲,以及積極主動的測試集成和淘汰過時的實踐來解決這些問題。
查看英文原文:
Uber’s Journey to Modernizing Big Data Infrastructure with Google Cloud Platform (https://www.infoq.com/news/2024/06/uber-bigdata-migration-gcp/)
德國再次擁抱Linux:數萬系統從windows遷出,能否避開二十年前的「坑」?
下一代 RAG 技術來了!微軟正式開源 GraphRAG:大模型行業將迎來新的升級?
李彥宏:開源模型是智商稅;網際網路公司開山之舉,有贊取消HRBP崗位;小紅書大裁員,30%員工丟飯碗?| Q資訊
有贊取消 HRBP 崗位,員工拍手叫好!中國科技大廠的尷尬境地:既要富士康的效率,又要谷歌的創新