大模型火火火火火足兩年了,如今的大模型江湖,是什麼模樣?
攤開全球畫卷,OpenAI依舊在通用大模型領域一騎絕塵,但整個生態百花齊放——有擅長長文本的Claude、開源王者Llama、開源新秀Mistral、畫圖王者Midjourny……
到底什麼才是評估大模型的第一要義?參數、規模、價格、榜單排名?似乎都還不夠,或許只有能腳踏實地在人們的生活和工作里用上大模型,並且夠穩定、不出錯,才是千千萬萬企業和用戶最為關心的話題。
對如今的大模型領域,必須要再度搬出那句程式設計師的老話:Talk is cheap,Show me the code。
用起來,才是王道。
現在,打開位元組跳動旗下的AI「扣子」平台,就能看到成百上千的bot,正在參與一場火熱PK。
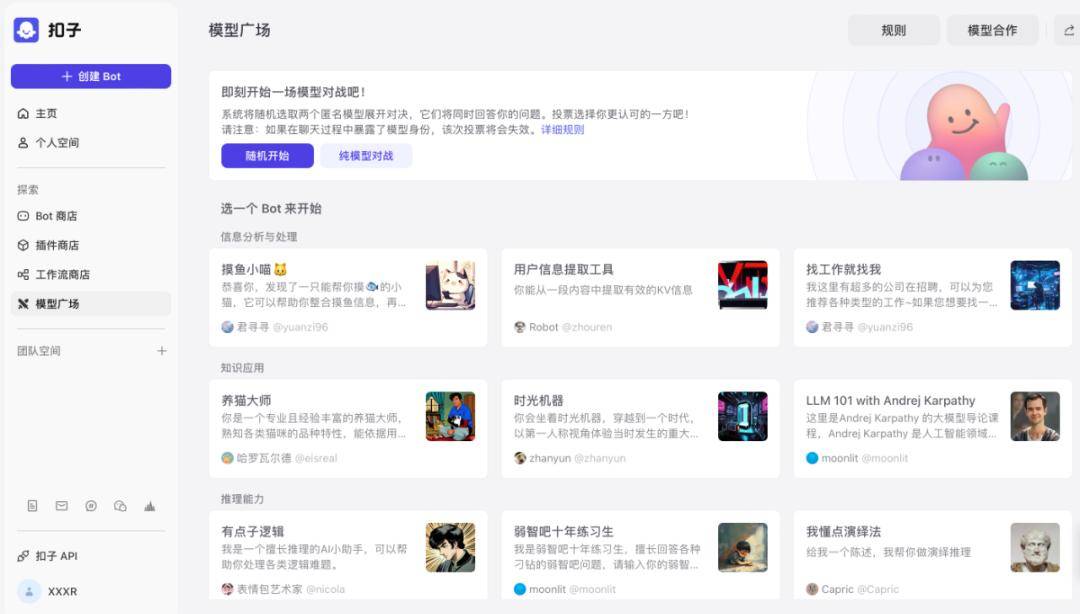
從2024年2月1日上線以來,扣子已經接入了多個國內知名大語言模型,包括豆包、通義千問、智譜、MiniMax、Moonshot、Baichuan等等——宛如琳琅滿目的大模型「貨架」,無論是哪家大模型,小中大尺寸,應有盡有。
無論是學英語、編程、寫文案,算命,民間高人們在這些模型上開發出來的應用,可以說是五花八門。但到底怎麼樣才能在這些場景用得最好?
扣子模型廣場簡單直接地提供了對比評測的平台。
如果你是一位小紅書博主,就可以直接打開扣子裡的小紅書文案生成器,搭載兩個不同的大模型,實時測試比對。
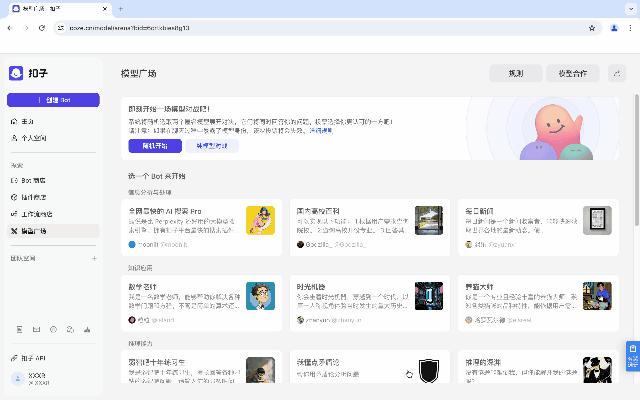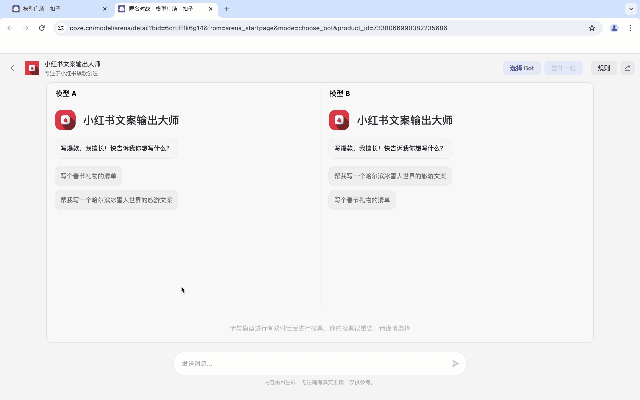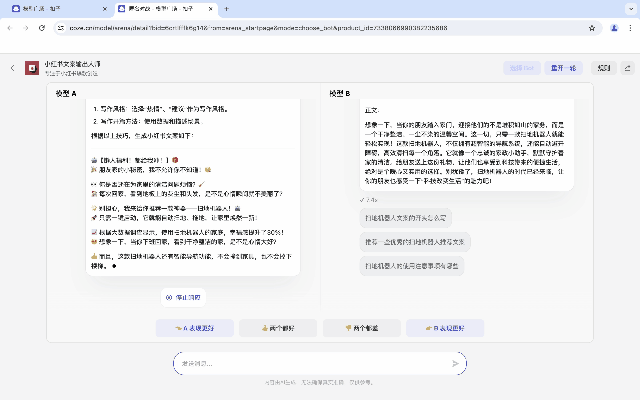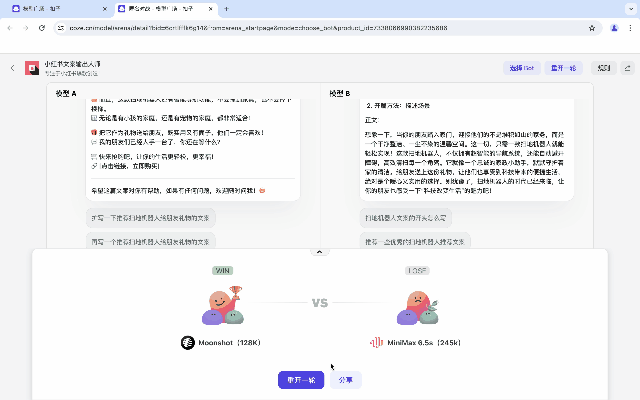
兩個Bot都使用了同樣的Prompt和插件,但無論是響應速度還是返回的內容,在實時測試里,效果對比一目了然。
如同遊戲一樣,扣子模型廣場提供了多種有趣的玩法,包括指定Bot對戰、隨機Bot對戰、純模型對戰。
比如,在隨機對戰中,系統就會隨機選擇一個Bot,進行模型對戰。這適用於評測模型在任意業務場景下的文本生成、技能和知識調用等能力——PK的兩個模型都是匿名的,基於 Bot 的Prompt、工作流、知識庫等能力配置,回答用戶的問題。
PK則過程完全向用戶公開。前來觀光的用戶,可以通過模型對戰與兩個隱藏了模型的Bot實時對話,並根據模型的回答進行投票。投票結束後,廣場才會揭秘具體的模型。
PK也不只是純看用戶投票。結果公示後,用戶則可以展開結果頁面,查看兩個模型的詳細配置,包括生成多樣性、生成隨機性等配置參數。
從2022年年底ChatGPT爆火,到如今Sora、Midjourney等多模態模型的成果震撼人心,到現在的扣子模型廣場的推出,無疑是大模型生態日漸成熟後,向應用層的「上探」——人們不再討論數字,而是開始考慮是否可用。縱觀整個AI領域的發展脈絡,這也是大模型新技術走向To C化的重要一步。
01. 大模型爆火兩年後:這麼近,那麼遠
回溯人類科技史,大概很少有技術像大模型一樣,以狂風驟雨般的速度讓全社會都形成共識:這是一項能夠切實提升生產力,改變未來的新技術。
從ChatGPT背後搭載的GPT-3.5,到GPT-4和最新的GPT-4o,過去兩年中里的通用大模型經歷了過山車一般的發展速度。大模型、晶片廠商還在共同大煉模型,試圖探索Scaling Law(縮放定律,不斷擴大參數規模和數據量,能得到更強的模型能力)的極限。僅僅以參數量來衡量,GPT-3.5參數量是1760億,這還是一個閉源模型;到了今年,人們所能用到的最先進開源模型Llama 3,參數量就已經超過4000億。
更大的參數、數據量,就像土壤,是模型能力的基礎,但土壤上能夠長出什麼樣的應用——是苔蘚還是參天大樹,考驗的是模型「有多聰明」。
動輒數千億參數的模型可以展現技術前沿,如今的模型創新者們正在努力把模型做小。這相當於將模型「蒸餾」,讓更小的模型能夠擁有更強大的性能。2023年9月發布的Mistral 7B(70億參數)就是小模型派的代表,能夠打敗130億參數的Llama 2模型。
到了2024年,「小模型」的趨勢更加勢不可擋。Meta旗下的Llama 3發布後,旗下80億模型(8B)的性能,就比上一代的Llama 2 700億參數模型還要強,因此在文本、數學、編程方面的能力大大增強。
究其原因,這是由於Llama 3「學習」的數據密度足夠豐富——用了 15 萬億 Token 的訓練數據,這比Google旗下的Gemini同等模型多學了一倍還不止。
但儘管如此,一個現實是,現在的大模型依舊面臨著「隔岸觀火」的尷尬境地:在開發者圈內,模型進展日新月異,性能更強,用例也越來炫目;但在對岸,則是「看在眼裡急在心裡」,困惑於如何用上大模型的普通用戶。
實際上,大模型離人們的工作和日常生活的距離還很遠。數據就有所印證——MIT的一項研究顯示,但就計算機視覺(CV)這個領域來看,今天能夠自動化的工作,占美國經濟中占工人薪酬1.6%的任務(不包括農業),但只有23%的薪酬任務(占整個經濟的0.4%)按自動化是更划算的。AI如今在人類工作流中所占據的比例,還非常小。
對普通的C端用戶來說,AI應用更多是一個「一輪游」的存在。過去兩年中火爆的AI應用,很多迎來大批試用、試玩的用戶之後,真正留下的日活、周活用戶寥寥無幾。真正核心受眾,停留在專業開發者、垂直領域的專業人員(如設計師、運營、寫手等等)。
一方面,這是由於底層的通用大模型能力還需要不斷提升,如今的模型還有幻覺等等可控性問題,都未得到很好地解決;此外,模型的記憶能力還處在比較小的階段,還無法真正做到記住用戶的喜好、習慣等等,更複雜的交互也無從談起。
這導致如今的各類AI應用能落地的地方,集中在容錯率較高的創作類場景中,如寫文案、畫畫、對話等等,或是基於語言大模型的簡單遊戲。
更重要的是,交互層面的門檻尚處在高位——和大模型對話,對話深度有限,還需要用戶研究怎麼寫Prompt(提示詞),數據訓練也有不小的理解門檻。企業端用戶想要用上大模型,更是想要跨越選型、微調等工作。
一言以蔽之:大模型,依舊有著艱深的理解和應用成本。
所以,真正到了輔助決策類——企業核心工作流中,大模型其實還沒辦法達到可用狀態。比如,根據數據分析廠商「九章數據」的統計,在數據分析場景里,用大模型生成SQL(結構化查詢語言,一種資料庫的核心語言)準確性約在70%左右,但剩下的30%,還需要專家人工手動檢查,這就失去了以AI提升效率的意義。
大模型和用戶側,現在就如同漸近線一般,需要找到能夠在技術和場景上相匹配之處,讓用戶真正「用起來」。在剛結束不久的「AI屆春晚」智源大會上,智源研究院院長王仲遠就表示:「國產大模型已經開始無限接近 GPT-4,這意味著基礎模型已達到可用的狀態,但當它達到可用狀態開始賦能千行百業,進入各行各個垂直領域,還需要找到更好的產業生態和合作模式。」
02. AI應用,爆發前夜
很多人會將大模型的爆火,比作如同移動網際網路那樣的歷史機遇。這樣瞬間可喚醒很多人的記憶——如今層出不窮的AI應用,就和移動網際網路時期的App混戰,如出一轍。
如果參照歷史規律,從個人電腦帶來的PC網際網路時代,再到移動網際網路時代,每一次技術革新後到大量應用出現,幾乎都需要經過2-3年以上的時間——2007年,蘋果推出iPhone 1,定義了移動網際網路時期的交互形式,直到兩年後,Uber、Whatsapp、Instagram等產品才依次出現,成為席捲全球的應用。
這期間發生了什麼?底層的技術變革繼續進行,不斷讓成本下降到可以商用的水平,大量應用創新才得以出現。這會進一步倒逼基礎設施的變革——雲計算、大數據等行業,正是由於大量移動終端增加,人們在線時長也在不斷增加。
如今的AI領域,也同樣站在了技術革新到應用繁榮的臨界點上。
伴隨著大模型技術革新,應用創新已漸有燎原之勢。2023年,GPT-4發布後,OpenAI隨即在11月上線GPTs商店,開發者用簡單的套殼,就可以馬上做出各式各樣的應用,短短兩個月內,辦公、設計、生活、教育、科研、編程等各個領域超過300萬個GPTs,如同雨後春筍般出現。
而前不久的WWDC大會上,蘋果正式官宣與OpenAI的合作——將把ChatGPT集成到iPhone、iPad和Mac設備中——宛如當年的App Store重現。
據Gartner技術成熟度曲線顯示,現在,大模型領域的生成式AI(Generative AI)和基礎模型(Foundation Models)都處於膨脹的巔峰期,再往下走,就是應用爆發時期。
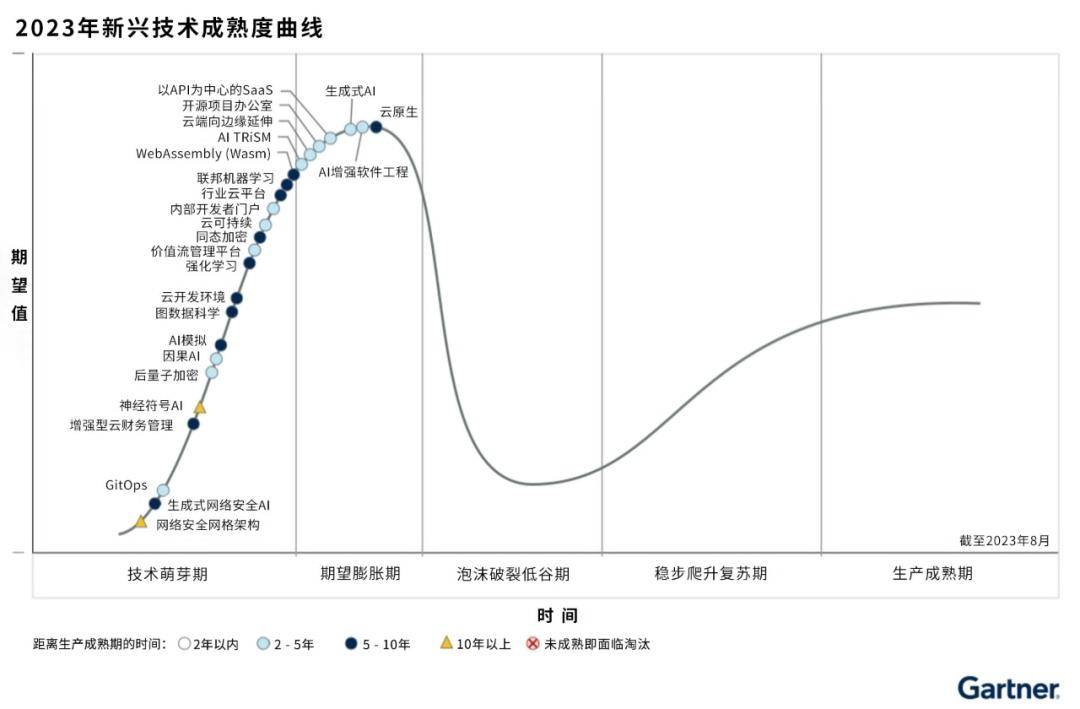 來源:Gartner
來源:Gartner
不過,但中間還有許多工作需要完成。大模型技術浪潮爆發後,從底層的晶片、中間層的Infra架構等等,都在密集而迅速地進行一輪變革:GPU晶片需要加強推理效率,而軟體中間層則需要承接大模型的大規模推理和應用需求,在算法層面降低調用成本。
AI的難,在於大模型本身的技術複雜性上,而在終端設備、大模型等「平台級」基礎設施和前端應用之間,如今會更需要「送水人」的力量——「扣子」等AI應用開發平台,現在擔當的就是這樣一種角色,讓大模型的能力順利輸送到使用場景之中。
比如,對於一位0編程經驗的用戶來說,現在開發AI應用幾乎已經沒有難度——和「扣子」進行交互,短到僅需要一句話即可。
至於用什麼模型、如何使用模型,也無需了解艱深的專業名詞才懂得模型的性能幾何。「扣子」的Home Bot就像一位手把手帶你的老師,如何使用模型、平台上有什麼現成的Bot可以使用,扣子都能給出相應的建議。
再到開發過程中,「扣子」現在就已經像是一個開箱即用的工作檯一樣,給用戶提供了豐富的組件選擇——插件、工作流、圖像流、觸發器等等。如此一來,用戶開發的,就再也不局限於簡單的套殼應用,而是可以通過聯動api、封裝好的模塊等等,完成複雜任務的執行。
從去年年底上線以來,「扣子」平台上就已經有不少有趣的用例。比如,一位汽車發燒友,為了解答身邊諸多好友的選車問題,就使用「扣子」的工作流功能,添加了 5 個節點,最後實現根據用戶需求搜索車型、對比參數,到最終輸出圖文並茂的購車建議。
在5月15日的火山引擎FORCE原動力大會上,曾經展示過一個案例,一位五年級學生開發出了一個名為「青蛙外教」的智能體,並且已經將其分享給了同學朋友們一起使用。
從某種意義上來說,「扣子」等AI應用開發平台的最重要意義,就是將原來AI應用覆蓋的開發者群體,向外延展到所有主流用戶當中。在大模型本身還無法解決端到端的問題時,發動所有人的力量來開發各式各樣的應用,才能讓大模型生態加速發展。
而「模型廣場」這樣的PK形式,更是向市場發出了寶貴的信號:對於大模型這類更強調「因地制宜」,擅長解決智力密集型需求的技術而言,盲目刷榜、比拼參數已經沒有意義。模型廠商和開發者,都應當將注意力放到一個個的應用場景中——設身處地地了解用戶反饋,才可能真正找到這一階段的PMF(Product Market Fit)。
03. 等待下一個Killer App
如果將國內大模型火熱的這兩年,劃分出演進的歷程:前半程,所有人焦急於大模型什麼時候可以趕上GPT-3.5,而從2023年下半年開始,話題陡然轉變成了:超級應用何時到來?
這種討論在2024年上半年達到頂峰。市場分化出兩種截然不同的態度——不少開發者相信,隨著模型規模擴大、智能水平提高,應用能力就自然會發展出來,因此需要集中精力、資源投入到底層大模型中;而另一面則更現實主義——做大模型過於昂貴,試錯成本太高。有投資人覺得,最好的方式是「見好就收」,尋找馬上就能商業化的場景。
兩種態度所聚焦的問題,都是AI應用。
近期,大模型圈內的不少動作,正在加速AI應用的落地進程。就在5月,大模型領域剛剛迎來一次狂風暴雨一樣的降價潮——包括智譜、Deepseek、豆包、阿里、騰訊、訊飛在內的主流大模型廠商,都宣布了一輪模型降價。
就以位元組旗下的火山引擎為例,5月,豆包大模型矩陣集體降價。現在,豆包主力模型在企業市場的定價就降至0.0008元/1000 Tokens,比行業價格降低99.3%。相當於,用戶用1塊錢,就能處理3本《三國演義》。
將模型價格打到地板價,固然有市場競爭考慮,但更核心的著眼點,其實還是擴大開發者群體——開發AI應用的試錯成本太高,導致長期以來,真正嘗試做AI應用的人群太少。但在模型降價後,開發一個模型可能只需要百元、千元級別。以往對AI應用的開發顧慮,已經不再是問題。
反過來說,AI應用供給增加,受眾擴大,也會反哺到模型的開發當中。「用戶規模的擴大,也將提升大模型的性能。」火山引擎總裁譚待表示。大的模型使用量,才能打磨出好模型,也能大幅降低模型推理的單位成本。
類似的「好信號」還有不少。進入2024年,多模態模型的進展同樣令人欣喜——無論是國外的Sora、GPT-4o、還是近期國內Dreamina、可靈等多模態模型爆火,都徹底點燃了用戶對視頻、圖像領域應用的興趣。破圈的AI換臉、AI翻譯、虛擬人跳舞等玩法越來越多。這背後,都離不開多模態的技術突破、模型推理成本的降低,以及中間層的逐步完善。
相對應的,現在的「扣子」平台也已經匹配上AI技術普及的腳步。在近期的更新中,扣子就已經開始支持存儲重要內容為關鍵變量、資料庫——相當於給Bot外掛了一個記憶模塊。而在交互體驗上,「扣子」也支持配置開場白、用戶問題建議、快捷指令、背景圖片、語音等等,還支持卡片格式輸出形式。
簡單來說,如果用戶現在想要開發一個能翻譯、像真人一樣講話的虛擬人,操作也已經非常簡單——在扣子上選擇合適的通用大模型,就可以簡單訓練出一個會說話,而且交互非常真實的AI助手。並且,「扣子」可以將構建的 Bot 直接發布到飛書和微信等平台,無縫嵌入到各類生產力工具中。
可以預見的是,隨著AI應用落地門檻進一步降低,新一輪市場競賽會迅速開始。這將讓市場跨過這一段尷尬的「應用真空期」——只有真正讓AI切實地融入人人可感知、可使用的產品之中,才可能消弭許多焦慮、矛盾,或是令人不安的未知狀態。
而眼下,那句程式設計師群體的老話,或許應該改成:Talk is cheap,show me the CozeBot。