文|陳斯達
編輯|李然
「美國貼吧」要把自家數據喂給ChatGPT了。
5月17日,據官方消息,Reddit 已與 OpenAI 達成協議,允許其使用自家內容訓練聊天機器人及其他產品。合作宣布後,Reddit股價在盤後交易中上漲11%。
圖源:X
合作的互利共贏,OpenAI在官網中有所介紹:
- OpenAI能用上Reddit的實時內容:自家AI 工具由此能夠更好地理解和展示 Reddit 上最新話題的內容,因為OpenAI可訪問得Reddit數據 API,將提供實時的、結構化的、獨特的內容。
- Reddit能用上OpenAI的AI技術:Reddit 將建立在 OpenAI 的 AI模型平台上,將使Reddit為redditor和 mod帶AI驅動的全新功能。
- 最後,OpenAI將成為Reddit的廣告合作夥伴。
OpenAI的執行長Sam Altman持有Reddit 8.7%的股份,此前還是Reddit的董事會成員。所以OpenAI為了避嫌,強調此次合作是「由OpenAI的營運長(Brad Lightcap)領導」,並「由(OpenAI)獨立董事會批准」。Altman作為OpenAI董事會成員,據TechCrunch,本人在此次決定上採取迴避姿態。
此次合作的梗圖誕生:Altman這一出,屬於是左手倒右手,一看都是自家人。

圖源:Reddit
我想知道這次合作具體怎麼談成的。
我想知道這次合作具體怎麼談成的。
很多網友似乎不太理解Reddit內容對於大模型的價值,紛紛表示Reddit會讓ChatGPT變得「不幹凈」。
熟悉「貼吧」內容調性的網友們馬上炸開了鍋,有人馬上棄坑:Claude不比你GPT香?
圖源:X
大本營Reddit平台上的悲觀發言:把各位貼吧老哥的發言喂給大模型,AGI的進展立馬倒退四年:
圖源:Reddit
OpenAI的模型要用貼吧上科技板塊的數據訓練,看來對AGI的預測要推後四年。
OpenAI的模型要用貼吧上科技板塊的數據訓練,看來對AGI的預測要推後四年。
有人也不明白了:Reddit至於那麼差嗎?
圖源:Reddit
只有我比較開心?Reddit上有用的內容也不少,如果能用AI查詢,豈不美哉?
只有我比較開心?Reddit上有用的內容也不少,如果能用AI查詢,豈不美哉?
殊不知,前有論文證明「弱智吧」內容才是AI中文語料質量的高地,這波屬於是網友信不過OpenAI技術大拿們的眼光了。

圖源:論文
用平台數據拓寬收入渠道,曾遭大規模抵制
成立於2005年的Reddit,於2024年3月上市,目前並不盈利。據其最新介紹,Reddit日活躍用戶為8270萬。據Techcrunch,Reddit的平台帖子超10億個,評論數超160億條,用戶生成的內容每天還在增長。平台也可以被看做AI公司訓練模型的「金礦」。
此次合作也說明,Reddit依然在嘗試不同業務,不希望過於依賴於廣告收入。
OpenAI、谷歌等公司將Reddit的數據用於自家模型訓練後,Reddit不甘「白嫖」,2023年6月,Reddit宣布將對開發人員訪問其API收取高額費用。其對每5000萬個API請求收取12000 美元的費用,在業內定價已經很高。
大樹底下不能乘涼了。靠著Reddit發家的各種第三方應用及個人開發者沒法掙錢,Reddit社區自此開啟一場聲勢浩大的抗議。在海量用戶的自發組織下,在6月12日開始癱瘓。超過8000個版塊(類似於微博、貼吧的不同話題)都被版主設置成了「私人版塊」,其他用戶無法訪問。
來源:The Verge
這場利益沒有對齊的抗議很快又被自發終結。僅僅過了兩天,大部分版塊恢復運營。用戶找不到平替之前,還得接著用Reddit。
Reddit官方下場「反白嫖」的最終目的很快落地——用平台內容向大模型公司收費。
2024年3月上市前,Reddit與谷歌母公司Alphabet還達成每年價值約6000萬美元的交易,允許自家內容用於谷歌模型的訓練。5月早些時候,Reddit公布的首份季報中,收入超過分析師預期。這表明,Reddit與谷歌的交易及其推動廣告業務增長的努力,正在得到回報。
來源:路透社
為什麼各家大模型公司都在搶著給Reddit送錢,真的找不到更好的語料嗎?
數據「掘金」的終點,難道是貼吧?
OpenAI掌門人Altman最近在播客中提到,模型未來的進步,不應該依賴數據。但就目前階段來說,數據仍然是當下各大玩家的必爭資源。
根據大模型的尺度法則,即便模型參數和算力都不斷提高,但是數據量和質量如果停滯不前,模型的性能也很難持續進步(見智能湧現文章,大模型鬧「數據饑荒」,科技巨頭進入灰色地帶)。
3月在英偉達GTC大會上,黃仁勛對話Transformer七子時也有觀點認為:高質量的模型需要的其實是高質量的數據,一味堆量是不夠的。
外國網友還在擔心,把過於負面的Reddit「貼吧語料」喂給AI會不會適得其反;中文網際網路上,最好的大模型語料庫真的就是貼吧——弱智吧。
這個結論來自三月底發布的一篇論文。研究團隊發現,大語言模型目前能理解、執行複雜指令,回答也能做到準確流利。然而這些進步基本都發生在英語世界,中文大模型的若要進步,就需要基於獨特的語言特徵和文化深度,找到合適的數據集。
圖源:論文
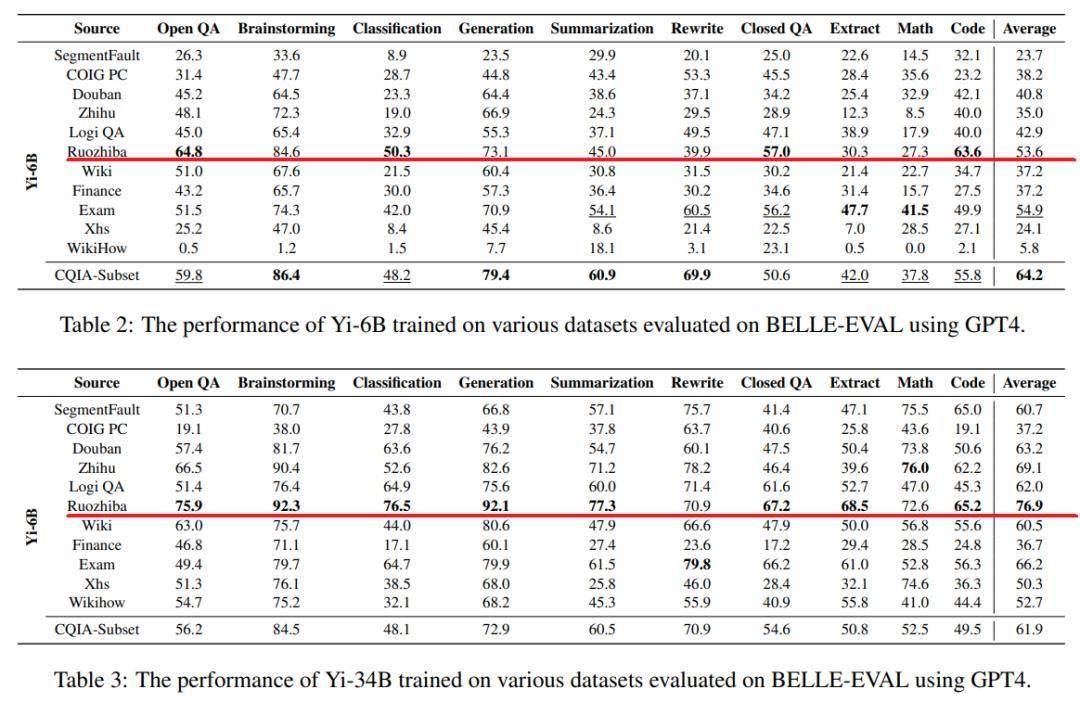
研究看中了各類中文社交媒體、論壇的語料質量。論文不僅打造了中文指令微調數據集COIG-CQIA,還為後續從中文網際網路選擇訓練數據提供了參考。
論文作者從微博,知乎,豆瓣,小紅書等主流的社區論壇中抽取了大量的語料進行綜合,提出了COIG-CQIA數據集。而在這個過程當中,研究人員對這些社交平台上的語料進行了一個排名。
經過比較,弱智吧數據集在多個子集上的平均排名中最終位居第二。
圖源:論文
弱智吧的內容有那麼神?有網友整理過弱智吧的經典發言:
- 每個人工作都想賺錢,那麼是誰在虧錢?
- 我閉上眼睛觸碰星空,閱讀宇宙留給我的盲文。
- 世界是個大象,我們都在盲人摸象,抽象是對這個世界的鞭撻。
- 雨天,我走進水坑裡,不小心踩碎了天空。
- 生魚片是死魚片。
- 有的人看不到未來,其實是看到了未來。
- 夜裡很安靜,我打開了收音機錄下來,等白天吵鬧的時候播放。
論文介紹,弱智吧的帖子充滿雙關語、多義詞、因果倒置、同音異義詞。有些邏輯陷阱人類看了都汗流浹背,對AI來說,那必須是增強模型邏輯推理能力的絕佳養料。
雖然網際網路社區的語料對於AI來說養分可能確實充足,但是網友們對於社區直接將自己貢獻的內容拿去賣錢,卻不一定那麼樂意。
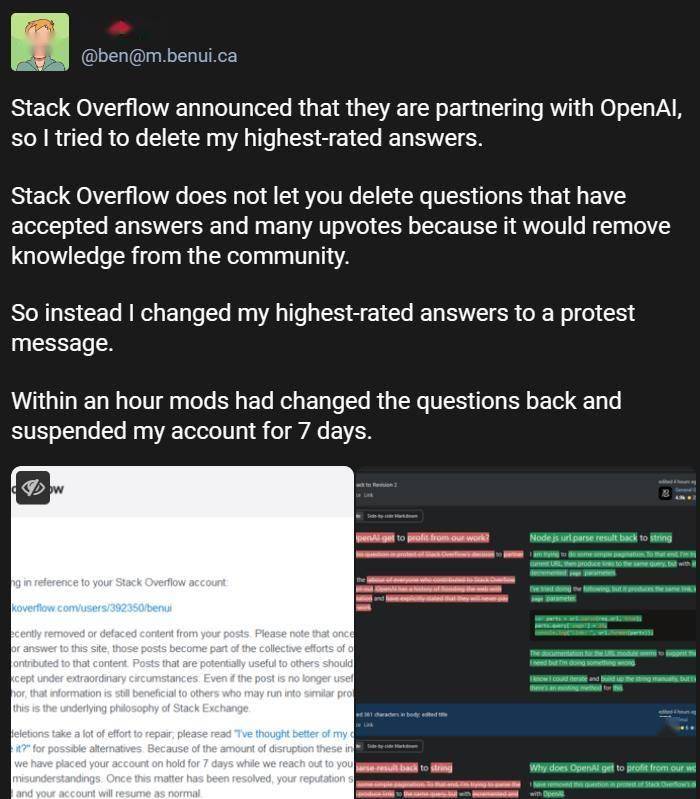
Stack Overflow是面向程式設計師及開發人員的論壇。2024年5月初也與OpenAI合作為模型訓練提供數據。一些用戶為了表示不滿,刪除或者編輯自身問題和答案,避免被用於訓練AI,但Stack Overflow恢復了被刪的帖子,封禁了對應的帳號。
圖源:網絡
有網友分享怎樣把自己的高贊經驗帖編輯為抗議帖的方法,並表示,「(版主的鎮壓)也是在提醒大家,在平台上發布的任何內容都能用於盈利目的。在 Discord、Twitter 等平台上的所有消息,早晚也要被抓取投喂給模型,最後再把相應AI服務售賣給你。」
但與Stack Overflow相比,Reddit的各路網友暫時沒有用刪帖表示反抗,轉而心疼起AI:孩子,吃點好的吧。

圖源:Reddit
A:之前有人擔心:把整個網際網路喂給AI,AI會讓人類滅亡
B:我不認為現在這是玩笑了。
C:這就是為什麼我的網絡發言如此愚蠢。我其實很聰明(聰明一詞拼寫錯誤)!
D:你拯救了人類!
A:之前有人擔心:把整個網際網路喂給AI,AI會讓人類滅亡
B:我不認為現在這是玩笑了。
C:這就是為什麼我的網絡發言如此愚蠢。我其實很聰明(聰明一詞拼寫錯誤)!
D:你拯救了人類!