最長3分鐘,快手的視頻大模型,成色幾何
在OpenAI文生視頻大模型Sora發布後,國內企業爭相入局,國產文生視頻大模型邁入加速階段。

過去半年,AI 生成視頻一直處在斷斷續續推進的狀態。
號稱國內首個自研視頻大模型的 Vidu,以及後續位元組、騰訊等多家國產廠商推出視頻生成模型,都在時不時引發外界的關注。
近日,又一國產視頻大模型加入戰局,快手「可靈」視頻生成大模型官網正式上線。

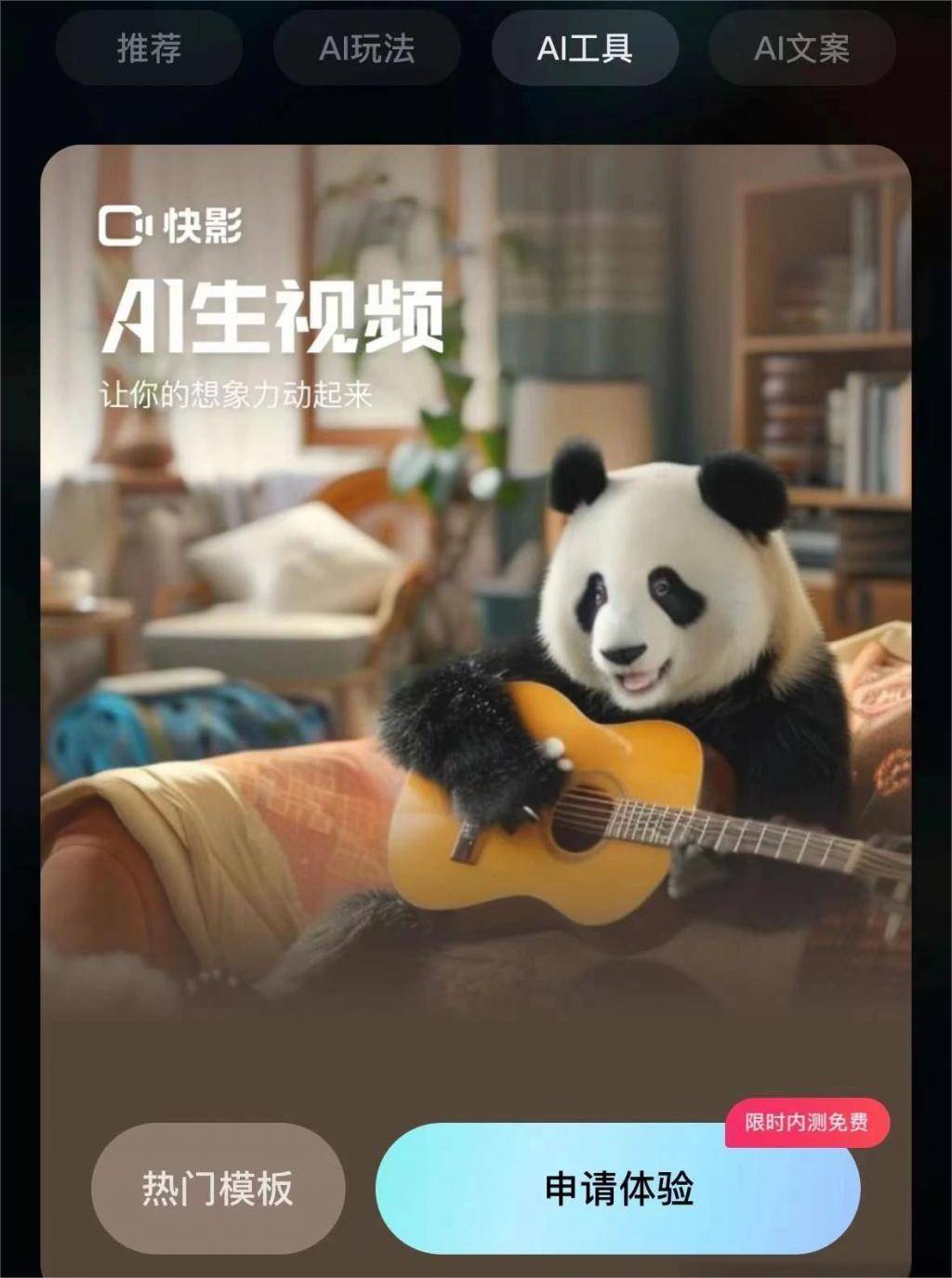
21日,快手可靈大模型發布重磅更新:正式開放圖生視頻功能,支持將靜態圖像轉化為5秒鐘視頻,用戶可通過提示詞文本控制圖像中物體的運動;同時推出視頻續寫功能,支持對生成視頻一鍵續寫和連續多次續寫,最長可生成約3分鐘視頻。
相較此前各家放出的視頻大模型以展示視頻為主,本次亮相的可靈大模型不但效果對標Sora,且已在快手旗下的快影App開放邀測體驗。
據快手方面介紹,可靈大模型為快手AI團隊自研,採用Sora相似的技術路線,結合多項自研技術創新,其生成的視頻解析度達1080p,時長最高可達2分鐘(幀率30fps),支持自由的寬高比。
此外,官方還宣稱,可靈大模型能夠生成大幅度的合理運動,並使其符合客觀運動規律。

在官方給出的視頻範例中,一位太空人在月球上奔跑,隨著鏡頭慢慢抬升,太空人的步態和影子都能保持合理恰當。
幾乎同時,美圖宣布將在7月底上線新品MOKI,該產品基於美圖奇想大模型的視頻生成能力,可幫助用戶生成AI短片。
然而, 也有觀點認為,相比一擁而上的大語言模式,視頻大模型更慢熱,且少了巨頭的身影。
為什麼會如此?
大廠們不感興趣嗎?
同時,在上一輪大語言模型競爭中,快手和美圖的存在感較低。
而在視頻大模型賽道,這兩家企業最大的優勢又是什麼?
對此,北京商報記者魏蔚和書樂進行了一番交流,本猴以為:
還在衝刺「高考」的大廠,不會直接進擊「博士後」。
做視頻,不是一堆圖組成PPT,大廠不急於這一塊發力,且實用性不強,只是一個肌肉展示。

畢竟,視頻生成不是將一堆AI繪圖連在一起變成動畫片。
除了考慮形象一致、符合描述、光影分割、分鏡表現等更多細節外,還有對劇情的理解能力、再創造能力。
這些都需要對視頻結構、內容解析、拍攝技巧和敘事手法等多個垂直領域進行深度學習。
其難度遠不是聊天、繪畫或專精於下棋之類靠數據堆積和用戶糾錯來完成的。
即使是影視領域的大師也常有敗筆,讓還處在「高考階段」的人工智慧出片,其難度可想而知。
但快手和美團,則需要秀肌肉,哪怕只是一個秀。
快手也好,美圖也罷,在視頻大模型賽道上,最大的優勢只是他們擁有讓人工智慧深度學習的豐富「學習資料」。
依靠這些「學習資料」,可以規避一定的版權問題,並且通過多年在視頻領域的內容積累、垂直細分和標籤標註,都讓大模型能夠更好地「檢索」知識,也讓其在算法設計上多少有一定的視頻專業素養。
但也僅此而已,在技術上依然缺少在人工智慧算法上的原始積累。
此外,視頻大模型即使成熟,也很難在影視領域有大的突破。
無論是短劇、廣告還是長視頻或電影,儘管都會內卷「大片特效」。

但受眾最終被吸引的還是內容(從編劇到運鏡,以及演員演技)。
這些才是大規模商業變現的關鍵。
愚以為,視頻大模型或許更容易在動畫領域找到一些商機。
作者 張書樂,人民網、人民郵電報專欄作者,中經傳媒智庫專家,資深產業評論人