本文將通過一個實戰案例來展示如何藉助於PyTorch自動混合精度庫對ResNet50模型進行優化,然後藉助少許幾行代碼即可獲得超過兩倍速度的模型訓練效率。
簡介
你是否曾希望你的深度學習模型運行得更快?
一方面,GPU很昂貴。另一方面,數據集龐大,訓練過程似乎永無止境;你可能有一百萬個實驗要進行,還有一個截止日期。所有這些需求都是期待特定形式的訓練加速的極好理由。
但是,我們該選哪一種模型呢?
PyTorch、HuggingFace和Nvidia已經為模型訓練的性能調優提供了很好的參考,包括異步數據加載、緩衝區檢查點、分布式數據並行化和自動混合精度等等。
在這篇文章中,我將專注介紹自動混合精度技術。首先,我將簡要介紹Nvidia的張量核設計;然後,我們一起探討發表在ICLR 2018上的開創性工作——「混合精度訓練」相關論文;最後,我將介紹一個在FashionMNIST數據集上訓練ResNet50模型的簡單示例。通過這個示例,我們來展示如何在加載雙倍批量數據的同時將訓練速度提高兩倍,而這一結果卻只需要額外編寫三行代碼。
硬體基礎——Nvidia張量核
首先,讓我們回顧一下GPU設計的一些基本原理。英偉達GPU最受歡迎的商業產品之一是Volta系列,例如基於GV100 GPU設計的V100 GPU。因此,我們將圍繞下面的GV100架構進行討論。
對於GV100架構來說,流式多處理器(SM)是計算的核心設計。每個GPU包含6個GPU處理集群(GPC)和S84 SM(或V100的80 SM)。其整體設計如下圖所示:

Volta GV100 GPU設計(每個GPU包含6個GPC,每個GPC包含14個SM;圖像來源:https://arxiv.org/pdf/1803.04014)
對於每個SM,它包含兩種類型的核心:CUDA核心和張量核。CUDA核心是Nvidia於2006年推出的原始設計,是CUDA平台的重要組成部分。CUDA核心可分為三種類型:FP64核心/單元、FP32核心/單元和Int32核心/單元。每個GV100 SM包含32個FP64核心、64個FP32核心和64個Int32核心。Volta/Turing(2017)系列GPU中引入了張量核,以便與之前的Pascal(2016)系列分離。GV100上的每個SM包含8個張量核。連結處給出了V100 GPU的完整詳細信息列表。下面詳細介紹SM設計。
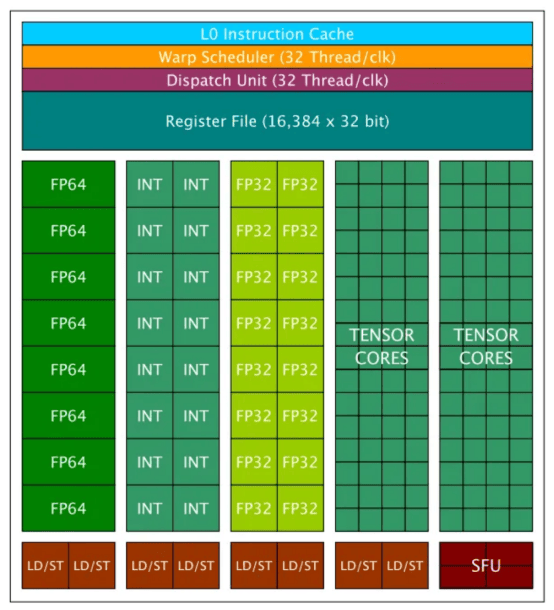
一個英偉達Tesla V100處理組就包含640個張量核(圖像來源:https://arxiv.org/pdf/1903.03640)
為什麼選擇張量核?Nvidia張量核專門用於執行通用矩陣乘法(GEMM)和半精度矩陣乘法和累加(HMMA)操作。簡而言之,GEMM以A*B+C的格式執行矩陣運算,HMMA將運算轉換為半精度格式。有關這方面的更詳細的討論可以在連結處找到。由於深度學習涉及MMA;所以,張量(Tensor)核心在當今的模型訓練和加速計算中至關重要。
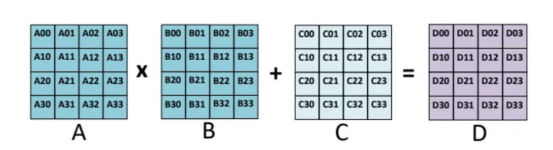
GEMM操作示例(對於HMMA,A和B通常轉換為FP16,而C和D可以是FP16或FP32),圖像來源:https://arxiv.org/pdf/1811.08309
當然,當切換到混合精度訓練時,請務必檢查你使用的GPU的規格。只有最新的GPU系列支持張量核,混合精度訓練只能在這些機器上使用。
數據格式基礎——單精度(FP32)與半精度(FP16)
現在,讓我們仔細看看FP32和FP16格式。FP32和FP16是IEEE格式,使用32位二進位存儲和16位二進位存儲表示浮點數。這兩種格式都包括三個部分:a)符號位;b)指數位;c)尾數位。FP32和FP16分配給指數和尾數的比特數不同,這導致了不同的值範圍和精度。
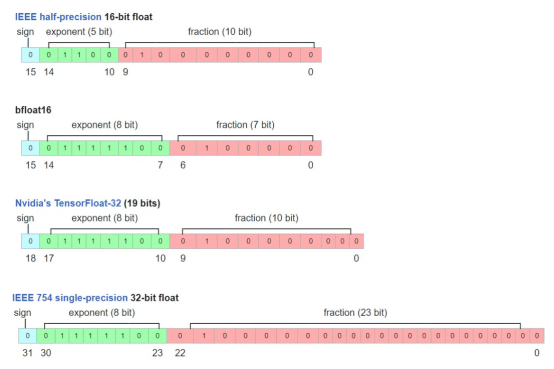
FP16(IEEE標準)、BF16(Google Brain標準)、FP32(IEEE標準)和TF32(Nvidia標準)之間的區別(圖像來源:https://en.wikipedia.org/wiki/Bfloat16_floating-point_format)
如何將FP16和FP32轉換為真實的值呢?根據IEEE-754標準,FP32的十進位值=(-1)^(符號)×2^(十進位指數-127)×(隱式前導1+十進位尾數),其中127是有偏差的指數值。對於FP16,公式變為(-1)^(符號)×2^(十進位指數-15)×(隱式前導1+十進位尾數),其中15是相應的有偏指數值。你可以在連結處查看有偏指數值的更多詳細信息。
從這個意義上講,FP32的取值範圍約為[-2¹²S,2¹²83;]~[-1.7*1e38,1.7*1e38],FP16的取值範圍大約為[-2⁵,2'8309]=[-32768,32768]。請注意,FP32的十進位指數在0到255之間,我們排除了最大值0xFF,因為它表示NAN。這就解釋了為什麼最大的十進位指數是254–127=127。當然,類似的規則也適用於FP16。
對於精度方面,請注意指數和尾數都有助於精度限制(也稱為非規範化,請參閱連結處的詳細討論)。因此,FP32可以表示高達2^(-23)*2^(-126)=2^(-149)的精度,FP16可以表示高至2^(10)*2^。
FP32和FP16表示之間的差異帶來了混合精度訓練的關鍵問題,因為深度學習模型的不同層/操作對值範圍和精度或者不敏感或者敏感,所以需要單獨解決。
混合精度訓練
前面,我們已經學習了MMA的硬體基礎知識、張量核的概念以及FP32和FP16之間的關鍵區別。接下來,我們可以進一步討論混合精度訓練的細節。
混合精度訓練的想法最早是在2018年ICLR論文《混合精度訓練》(Mixed Precision Training)中提出的。該論文在訓練過程中將深度學習模型轉換為半精度浮點,而不會損失模型精度或修改超參數。如上所述,由於FP32和FP16之間的關鍵區別在於值範圍和精度,該論文詳細討論了FP16為什麼會導致梯度消失,以及如何通過損失縮放來解決這個問題。此外,該論文還提出了使用FP32主權重拷貝和使用FP32進行歸約和向量點積累加等特定操作的技巧。
損失縮放(Loss scaling)。本文給出了一個使用FP32精度訓練Multibox SSD探測器網絡的示例,如下所示。如果不進行任何縮放,FP16梯度的指數範圍≥2^(-24),以下所有值都將變為零,這與FP32相比是不夠的。然而,通過實驗,將梯度簡單地縮放2³=8倍,可以使半精度訓練精度恢復到與FP32相匹配的水平。從這個意義上講,作者認為[2^(-27),2^(-24)]之間的額外百分之幾的梯度在訓練過程中仍然很重要,而低於2^(-27)的值並不重要。
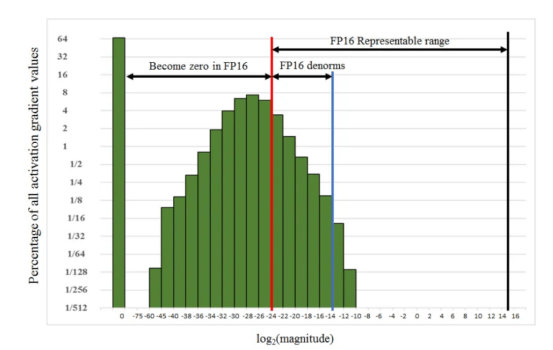
在Multibox SSD訓練示例中使用FP32精度的梯度值範圍。請注意,[2^(-27),2^(-24)]之間的值超出了FP16非規範化範圍,僅占總梯度的百分之幾,但在整體訓練中仍然很重要。圖像來源:https://arxiv.org/pdf/1710.03740
解決這種規模差異的方法是藉助損失縮放的辦法。根據鏈式法則,縮放損失將確保相同的量將縮放所有梯度。但是請注意,在最終權重更新之前,需要取消縮放梯度。
自動混合精度訓練
Nvidia公司首先開發了名為APEX的PyTorch擴展自動混合精度訓練,然後被PyTorch、TensorFlow、MXNet等主流框架廣泛採用。請參閱連結處的Nvidia文檔。為了簡單起見,我們只介紹PyTorch框架中的自動混合精度庫:https://pytorch.org/docs/stable/amp.html.
amp庫可以自動處理大多數混合精度訓練技術,如FP32主權重複制。開發人員只需要進行操作數自動轉換和梯度/損失縮放。
操作數自動轉換:儘管我們提到張量核可以大大提高GEMM操作的性能,但某些操作不適合半精度表示。
amp庫給出了一個符合半精度條件的CUDA操作列表。amp.autocast完全涵蓋了大多數矩陣乘法、卷積和線性激活運算;但是,對於歸約/求和、softmax和損失計算等,這些計算仍然在FP32中執行,因為它們對數據範圍和精度更敏感。
梯度/損失縮放:amp庫提供了自動梯度縮放技術;因此,用戶在訓練過程中不必手動調整縮放。連結處可以找到縮放因子的更詳細的算法。
一旦縮放了梯度,就需要在進行梯度剪裁和正則化之前將其縮小。更多細節可以在連結處找到。
FashionMNIST訓練示例
torch.amp庫相對易於使用,只需要三行代碼即可將訓練速度提高2倍。
首先,我們從一個非常簡單的任務開始,使用FP32在FashionMNIST數據集(MIT許可證)上訓練ResNet50模型;我們可以看到10個世代的訓練時間為333秒:
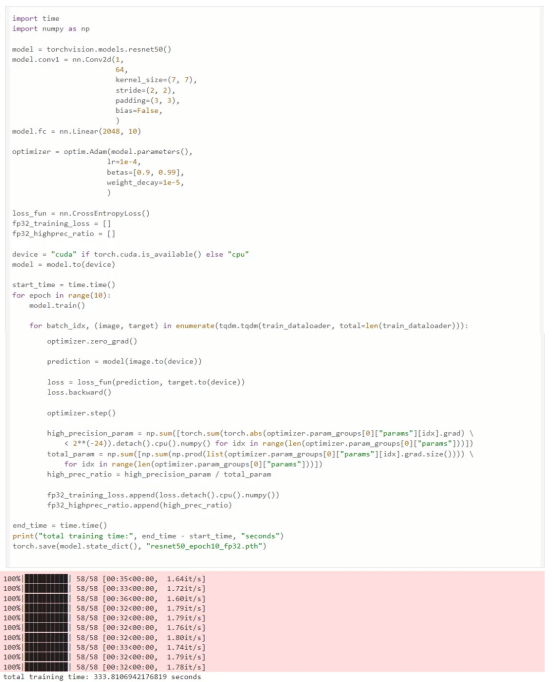
ResNet50模型在數據集FashionMNIST上的訓練
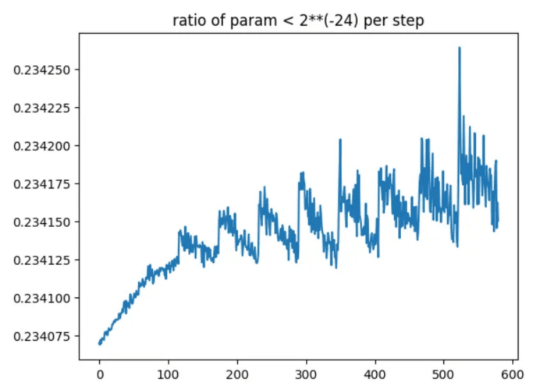
小於2**(-24)的梯度與總梯度之比。我們可以看到,FP16將使總梯度的近1/4變為零
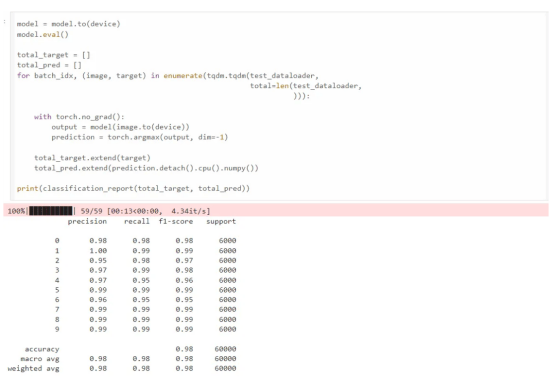
評估結果
現在,我們使用amp庫。amp庫只需要三行額外的代碼進行混合精度訓練。我們可以看到訓練在141秒內完成,比FP32訓練快2.36倍,同時達到了相同的精確度、召回率和F1分數。
複製
scaler = torch.cuda.amp.GradScaler()
#開始訓練的代碼
# ...
with torch.autocast(device_type="cuda"):
#訓練代碼
#封裝損失與優化器
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
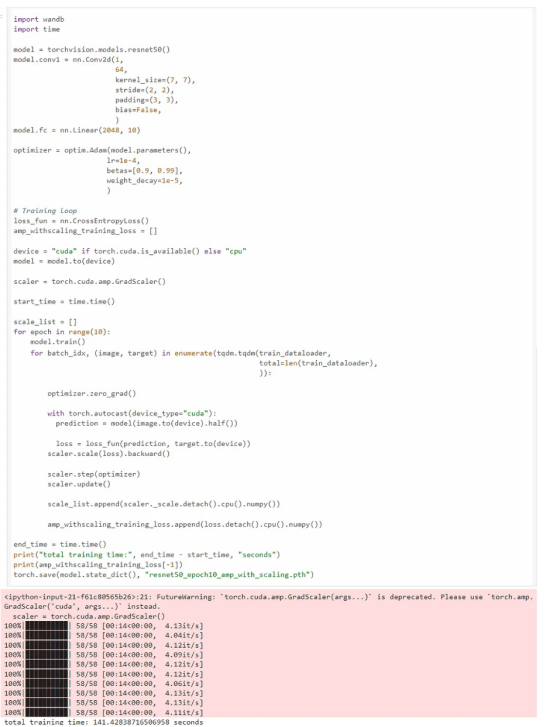
使用amp庫進行訓練
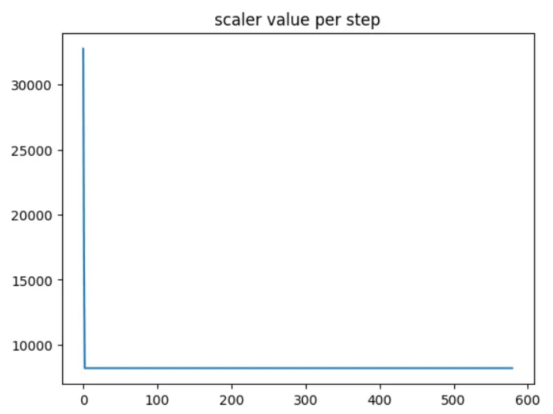
訓練期間的縮放因子(縮放因子僅在第一步發生變化,保持不變。)
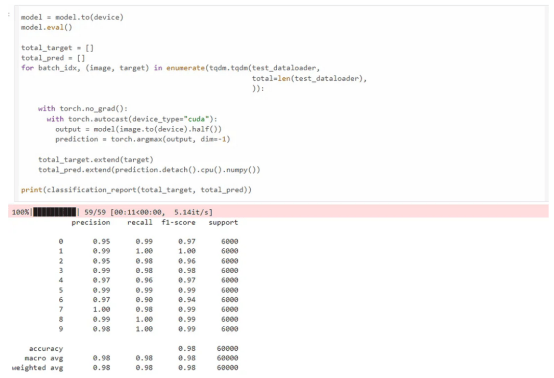
最終結果與FP32訓練結果比較
上面代碼的Github連結:https://github.com/adoskk/MachineLearningBasics/blob/main/mixed_precision_training/mixed_precision_training.ipynb。
總結
混合精度訓練是加速深度學習模型訓練的一種非常有價值的技術。它不僅加快了浮點運算的速度,還節省了GPU內存,因為訓練批次可以轉換為FP16,從而節省了一半的GPU內存。另外,藉助於PyTorch框架中的amp庫,額外的代碼可以減少到僅僅三行,因為權重複制、損失縮放、操作類型轉換等計算都是由該庫內部處理的。
需要注意的是,如果模型權重大小遠大於數據批次的話,混合精度訓練並不能真正解決GPU內存問題。首先,只有模型的某些層被轉換成FP16,而其餘層仍在FP32中計算;其次,權重更新需要FP32複製,這仍然需要占用大量的GPU內存;第三,Adam等優化器的參數在訓練過程中占用了大量GPU內存,而混合精度訓練使優化器參數保持不變。從這個意義上說,需要更先進的技術,如DeepSpeed的ZERO算法。