
本文中將重點介紹如何優化RAG系統,使其儘可能高效。我們從多個角度介紹RAG系統,深入了解其用途以及如何優化。
介紹
檢索增強生成(RAG)模型通常被稱為RAG系統,在AI行業得到極大的關注。這種模型背後的概念很簡單:我們允許模型根據需要從單獨的數據集檢索信息,而不是使用海量數據訓練模型。
將如何改進機器學習模型?首先,訓練或微調大語言模型(LLM)的過程極其費錢、費時且乏味。它需要訓練有素的機器學習和AI從業人員。RAG系統利用基礎LLM,增強輸入內容,以保持模型處於最新版本,同時仍能夠合併新數據。新數據生成後,幾乎可以立即添加到檢索資料庫中。
我們在本文中將重點介紹如何優化RAG系統,使其儘可能高效。我們從多個角度介紹RAG系統,深入了解其用途以及如何優化。
走近RAG模型
顧名思義,RAG模型由三大部分組成:檢索、增強和生成。這些部分代表模型的大體工作流,每個單獨的部分包括更多的細節。
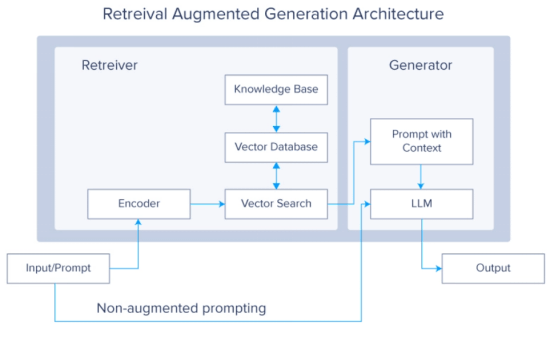
1. 查詢輸入——這個過程從用戶輸入查詢或提示開始,比如要求LLM執行一個任務,比如回答問題或幫助研究主題。視模型及其訓練數據而定,你可以依賴基礎模型的訓練數據,也可以依賴為模型提供數據。
2. 查詢編碼——使用編碼器模型(通常是像BERT這樣的預訓練語言模型或另一個基於Transformer的模型)將查詢編碼成向量表示。這個向量表示捕獲查詢的語義含義。
3. 信息檢索——使用編碼查詢向量,系統從提供的數據檢索相關文檔或段落。這個檢索步驟至關重要,可以使用密集檢索和稀疏檢索等各種技術來實現。先進的索引技術也可以用來加快檢索過程。從檢索到的文檔中選擇前N個候選文檔(基於相關性分數)。這些文檔被認為與輸入查詢最密切相關,對於生成最終響應是不可或缺的。
4. 文檔編碼——隨後將每個選定的候選文檔由向量表示解碼為人類可理解的語言。這個步驟確保檢索到的數據將用於生成階段。
5. 響應生成——連接的向量被饋送到像GPT、Mistral、Llama或其他的LLM中。生成器根據輸入生成連貫且符合上下文的響應。該響應應該以清晰、相關的方式回答查詢或提供所請求的信息。
那麼我們可以加快這個過程的哪些方面呢?就在它的名字里!我們可以優化RAG中的R(檢索)、A(增強)和G(生成)。
改進RAG檢索——增加向量化
通過增加維度和值精度來增強向量化過程,創建更詳細更精確的嵌入,這是提高RAG系統性能的有效方法。向量化過程將單詞或短語轉換成數字向量,捕獲它們的含義和關係,並將它們存儲在維度資料庫中。通過增加每個數據點的精細度,我們有望獲得更準確的RAG模型。
1. 增加向量維度——增加維度的數量讓向量可以捕獲單詞更細微的特徵。高維向量可以編碼更多的信息,為單詞的含義、上下文以及與其他單詞的關係提供更豐富的表示。
- 低維向量:一些基本的嵌入模型可能會將單詞轉換成512維向量。
- 高維向量:較複雜的模型可以將單詞轉換成超過4000維的向量。
2. 提高值的精度——通過增加值的範圍,可以提高向量表示的精細度。這意味著模型可以捕獲單詞之間的細微差異和相似之處,從而獲得更精確更準確的嵌入。
- 低精度向量:在簡單模型中,欄位值的範圍可能在0到10之間。
- 高精度向量:為了提高精度,可以將這個範圍從0擴展到1000,甚至更高。這允許模型捕獲更準確的值。比如說,人的年齡通常在1歲到100歲之間,因此0到10的範圍將缺乏準確表示的必要能力。擴大範圍增強了模型更準確地反映實際變化或差異的能力。
需要注意的是,這些優化是有代價的。增加系統的向量維度和精度值會導致更龐大的存儲開銷和計算密集型模型。
改進RAG增強——多個數據源
在檢索增強生成(RAG)系統中,檢索部分負責獲取生成式模型用於生成響應的相關信息。
如果整合多個數據源,我們可以顯著提高RAG系統的性能和準確性。這種方法被稱為增強優化,利用眾多信息庫來提供更豐富更全面的上下文,從而最終獲得更準確的響應。下面是幾個例子:
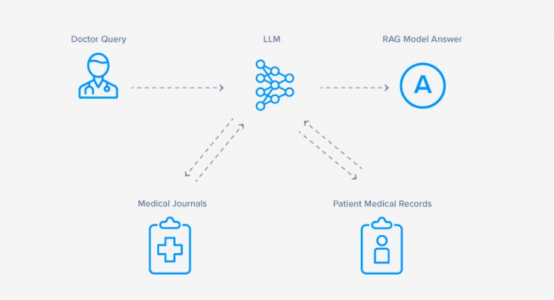
- 醫療保健——旨在回答覆雜的醫療查詢以幫助醫生的RAG系統得益於從醫學期刊和患者病歷檢索信息,以生成定製的方案。
- 法律——旨在協助律師進行案件研究的RAG系統得益於從多個相關案件檢索信息。通過對每個案件中的主題進行向量化,接受輸入提示後,RAG模型可以確定哪些案件可用於支持或辯駁訴訟觀點。
- 技術文檔——針對任何產品、軟體、硬體甚至棋盤類遊戲,回答常見問題(FAQ)的RAG LLM可以極大地幫助用戶獲得快速響應,無需閱讀大量的用戶手冊術語。
改進RAG生成——選擇最優模型
雖然實現檢索增強生成(RAG)系統時使用最先進的LLM常常可以保證卓越的內容生成和分析能力,但選擇最複雜的LLM並不總是最佳選擇。
下面是在使用RAG系統的生成部分時,需要注意的四點。
- 複雜性與效率——雖然GPT或Llama之類的高級LLM功能強大,但它們帶來巨大的計算成本和資源需求。將這些模型集成到RAG系統中可能帶來延遲問題或導致計算資源緊張,特別是在需要實時響應能力的場景中。
- 用例——基於RAG的LLM的有效性在很大程度上依賴特定的用例和領域需求。在一些情況下,較簡單的已微調模型可能優於較複雜的通用LLM。根據應用的實際需要定製模型的選擇可以確保有效地利用計算資源,又不影響性能。
- 用戶體驗和響應性——對於響應性和實時交互至關重要的應用,優先考慮較小的LLM中的速度和效率可以增強用戶體驗。一種兼顧計算效率與內容高效生成的簡化方法可確保用戶收到快速而相關的響應。
- 成本考慮——部署基於RAG的複雜LLM可能需要更高的硬體及/或運營成本。評估操作目標並權衡收益和成本,以便在致力於部署高度複雜的RAG時做出明智的決策。
提高RAG模型的速度——硬體
基於RAG的LLM的巨大價值因其優化、成本效益和高效使用的潛力而得到普及。這些優化已經提供了一種有效的方式來增強LLM的能力,允許它們檢索和合併最新的信息,確保模型保持相關性和準確性。
然而,改進RAG系統需要考慮其他方面。增加向量精度可以提高檢索準確度,但會導致更高的計算成本、更長的訓練時間和更慢的推理響應速度。最有效的RAG系統是根據你的獨特需求和目標量身定製的,又不影響整體效率。定製你的RAG系統,使其與你的特定用例、數據源和操作需求保持一致,有望提供最佳結果。
存儲數據和支持RAG的系統也是如此。高性能硬體供不應求,它們可以提供相比AI行業競爭對手最佳的性能,但這種系統很少具有普適性,無法適應所有場景。