前沿的AI獨角獸公司們正在花費所有精力使 LLM 更擅長推理。然而蘋果最近卻給他們潑了盆冷水。
近期,蘋果公司的一個六人研究團隊最近發表了一篇題為《了解大型語言模型中數學推理的局限性》的論文,論文中各種基準測試,十分詳實。不過最後的結論基本上就是想證明:當前的 LLM 無法推理。

「當前的 LLM 無法執行真正的邏輯推理;他們從訓練數據中複製推理步驟,「該論文中寫道,其中還包括 OpenAI 的 GPT-4o 等 LLM,甚至是備受吹捧的」思考和推理「LLM,o1。該研究還對一系列其他模型進行了研究,例如 Llama、Phi、Gemma 和 Mistral。
該論文的資深作者 Mehrdad Farajtabar 在 X 上發帖解釋了該團隊是如何得出結論的。據他介紹,LLM 只是遵循複雜的模式,即使是小於 30 億個參數的模型也達到了只有更大的模型才能更早達到的基準,特別是 OpenAI 三年前發布的 GSM8K 分數。
Mehrdad10月10日在帖子中表示:

大型語言模型 (LLM) 真的能推理嗎?或者它們只是複雜的模式匹配器?
研究人員引入了 GSM-Symbolic,這是一種在 LLM 中測試數學推理的新工具,因為 GSM8K 不夠準確,因此對於測試 LLM 的推理能力不可靠。

01
4大證據
證明大模型不具備形式推理能力
三年前,OpenAI 發布了 GSM8K 數據集(目前常用的一種小學數學推理基準數據集),測試 GPT-3(175B參數)在數學題上的表現,那時 GPT-3 的得分僅為 35%。如今,擁有約 30 億參數的模型已能夠在 GSM8K 測試中取得超過 85% 的得分,參數更大的模型甚至超過 95%。
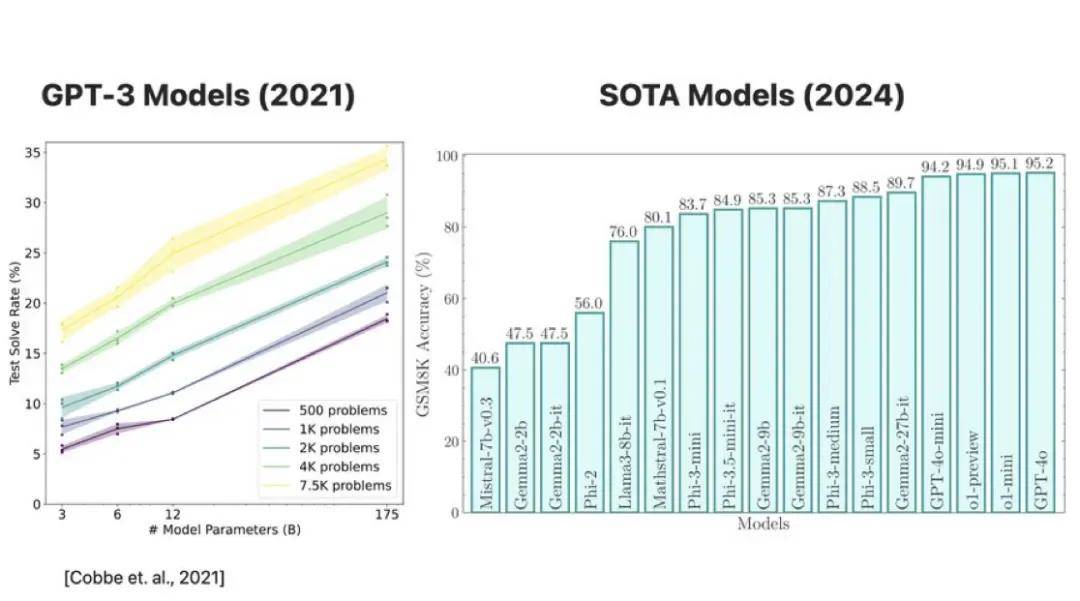
然而,隨著準確率的提升,疑問也隨之而來:這些模型的推理能力是否真的進步了?它們的表現是否真的體現了邏輯或符號推理能力,抑或是簡單的模式識別,數據污染,甚至過擬合的結果?
為進一步探索這一問題,研究團隊此發了 GSM-Symbolic,用於測試大語言模型在數學推理中的極限。GSM-Symbolic 基於 GSM8K 數據集,通過符號模板生成多樣化的問題實例,允許更可控的實驗設計。
為了更清晰地觀察模型在面對這些變體問題時的表現,他們生成了 50 個獨特的 GSM-Symbolic 集合,這些問題與 GSM8K 問題類似,但更改了其中的數值和名稱。
基於 GSM-Symbolic,他們從 5 個方面說明了為何他們認為大語言模型不具備形式推理能力。
GSM8K 的測試結果並不可靠
通過對多個開源模型(如 Llama 8B、Phi-3)和閉源模型(如 GPT-4o 和 o1 系列)的大規模評估,他們發現模型在 GSM8K 上的表現存在顯著波動。
例如,Llama 8B 的準確率在 70%-80% 之間波動,而 Phi-3 的表現則在 75%-90% 之間浮動。這也表明,模型在處理相似問題時表現並不穩定,GSM8K 上的高分並不能證明它們具備真正的推理能力。
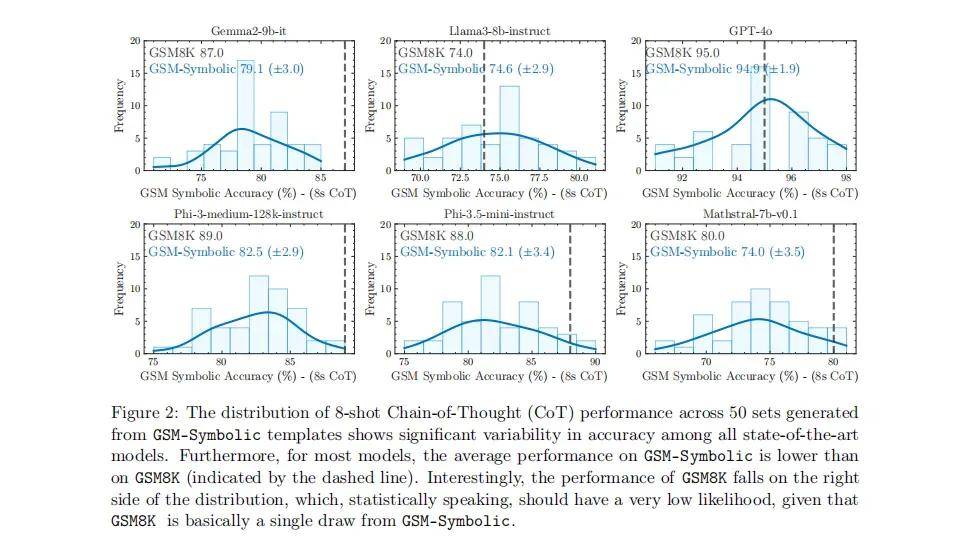
圖|由 GSM-Symbolic 模板生成的 50 套 8-shot 思想鏈(CoT)性能分布,
顯示了所有 SOTA 模型之間準確性的顯著差異性。對於大多數模型來說,GSM-Symbolic 的平均性能低於 GSM8K(圖中由虛線表示)。有趣的是,GSM8K 的性能落在分布的右側,從統計學上講,這僅有非常低的可能性,因為 GSM8K 基本上只是 GSM-Symbolic 的一次單一抽樣。
大模型的數學推理能力相當脆弱敏感
團隊觀察到由相同模板生成的不同集合之間存在較大的性能差異,並且與原始GSM8K準確率相比性能有所下降。這表明語言模型所展現的推理過程可能並不正式,因此容易受到變化的影響。一種解釋是,這些模型試圖進行一種分布內模式匹配,將給定的問題和解題步驟與訓練數據中看到的類似問題和步驟進行對齊。由於此過程不涉及正式推理,因此可能導致同一問題的不同實例之間存在較大差異。
具體測試表現為:對名稱和數字變動的敏感性研究還發現,當前的大語言模型對問題中的專有名稱(如人名、食物、物品)的變化仍然很敏感,當數字發生變化時,大語言模型就會更加敏感。例如,僅僅改變問題中的名字,就可能導致模型的準確率變化高達 10%。如果將這種情況類比到小學數學測試中,僅僅因為改變了人名而導致分數下降 10% ,是非常不可思議的。
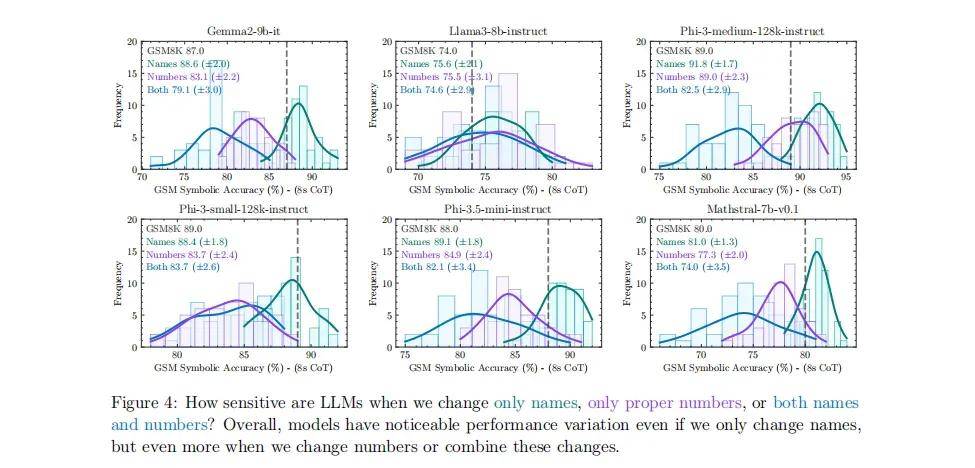
圖|當只更改名稱、專有編號或同時更改名稱和編號時,大語言模型的敏感性如何?總體而言,即使只更改名稱,模型也有明顯的性能變化,但當更改編號或合併這些變化時,性能差異更大。問題難度的增加導致表現急劇下降。
擴展問題難度,性能分布波動劇烈
研究團隊通過引入三種新的 GSM-Symbolic 變體(GSM-M1、GSM-P1、GSM-P2),通過刪除一個分句(GSM-M1)、增加一個分句(GSM-P1)或增加兩個分句(GSM-P2),來調整問題難度。

圖|通過修改條款數量來修改 GSM-Symbolic 的難度級別
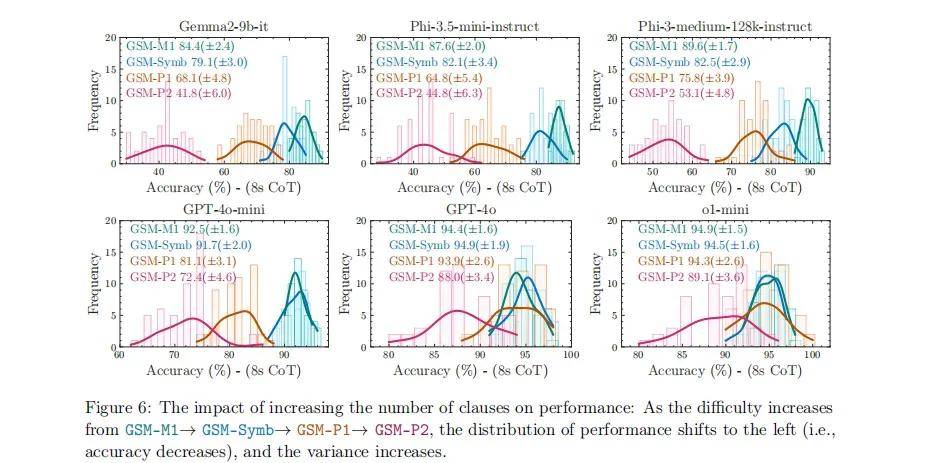
圖|增加條款數量對性能的影響:隨著GSM-M1GSM-SymbGSM-P1GSM-P2的難度增加,性能分布向左移動(即準確性下降),方差增加。
結果發現,隨著問題難度的增加(GSM-M1 GSM-Symb GSM-P1 GSM-P2),模型的表現不僅下降顯著,且表現波動也變得更加劇烈。面對更複雜的問題時,模型的推理能力變得更加不可靠。
大模型沒有真正理解數學概念
研究中還添加無關子句,實驗表明對LLM推理性能的巨大影響,研究團隊設計了 GSM_NoOp 實驗,在原有問題中添加一個似乎相關但實際無關的子句 (hence "no-op")。
結果顯示,所有模型的表現都顯著下降,包括性能較好的 o1 模型在內。這種現象進一步說明,模型並沒有真正理解數學概念,而是通過模式匹配來得出答案。

圖|在 GSM-NoOp 上,模型的性能明顯下降,較新的模型比舊的模型下降更大。
(a) 在GSM-NoOp上,模型的性能顯著下降,其中較新的模型比舊模型下降得更多。(b) GSM-Symbolic上的性能與GSM8K非常接近。然而,在GSM-NoOp上,即使使用完全相同問題的變體作為示例(NoOp-Symb),或者使用包含No-Op操作的不同GSM-NoOp問題的不同問題作為示例(NoOp-NoOp),性能顯著下降的情況也無法恢復。(c) 值得注意的是,一些在GSM8K和GSM-Symbolic上表現明顯差於(b)中模型的,在NoOp-Symb上卻表現出了更好的性能。
擴展規模和計算能力並不能解決根本問題
此外,他們還探討了通過擴大數據、模型規模或計算能力是否能夠解決推理能力不足的問題。Mehrdad Farajtabar 表示,儘管 OpenAI 的 o1 系列在性能上有一定改善,但它們也會出現這樣的愚蠢錯誤,要麼是它不明白「現在」是什麼意思,要麼是它不明白「去年」是什麼意思,還有一種更可能的解釋是,更大的訓練數據具有這種模式,所以它又沿用了這種模式。
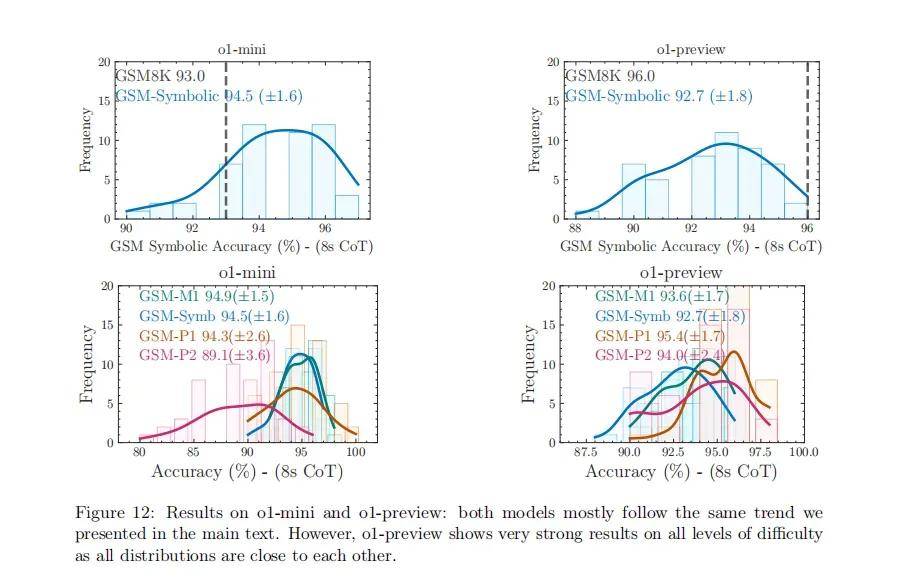
圖|o1-mini 和 o1-preview 的結果:這兩個模型大多遵循我們在正文中介紹的相同趨勢。然而,o1-preview 在所有難度級別上都顯示出非常強大的結果,因為所有分布都彼此接近。
作者認為,理解大語言模型的真正推理能力對於在現實世界中的應用至關重要,尤其是在 AI 安全、教育、醫療保健和決策系統等對準確性和一致性要求極高的領域。
研究結果表明,當前大語言模型的表現,更像是高級的模式匹配器,而非具備形式推理能力的系統。為了在這些領域安全、可靠地部署大語言模型,開發更為魯棒和適應性強的評估方法顯得尤為重要。
02
不過,OpenAI 的o1模型的推理的確強勁
令人驚訝的是,根據研究人員的說法,在這個基準測試中,OpenAI 的 o1 表現出「在各種推理和基於知識的基準測試中的強勁表現」,但當研究人員引入 GSM-NoOp 實驗時,能力下降了 30%,該實驗涉及向問題添加不相關的信息。PS:上個月OpenAI推出o1模型時也曾表示,提示詞宜簡單而非複雜。
這證明 OpenAI 這一系列新發布的模型的「推理」能力是越來越好的,也許 GPT-5 會好很多。
然而,可能是 Apple 的 LLM 在推理方面不太拿得出手,該團隊沒有測試 Apple 的模型。
03
科技圈又亂了:
大模型壓根不會推理,o1也不行
此外,並不是每個人都對這篇研究論文感到滿意,因為它甚至沒有解釋 「推理 」的真正含義,而只是引入了一個評估 LLM 的新基準。
「總體而言,我們在語言模型中沒有發現形式推理的證據……它們的行為更好地解釋為複雜的模式匹配——實際上非常脆弱,以至於改變名稱可能會使結果變化約10%!」Mehrdad 進一步補充道,擴展這些模型只會得到「更好的模式機器」,而不是「更好的推理器」。
首先,LLM更多是根據分散注意力的材料來進行「推理」,所以這種失敗,並不是什麼新鮮事。史丹福大學的 Robin Jia Percy Liang 早在 2017 年進行了一項類似的研究,結果相似。
其次,LLM 中缺乏足夠抽象、正式的推理的另一個表現是,大模型往往在解決小問題上的性能還可以,但隨著問題變大,性能很快就會下降,甚至分崩離析,正如7月 Subbarao Kambhapati 的團隊最近對 GPT o1 的分析:

在整數算術上也能看到同樣的問題。在較舊的模型和較新的模型中,都反覆觀察到,在越來越大的乘法問題上,答案準確度的衰減。
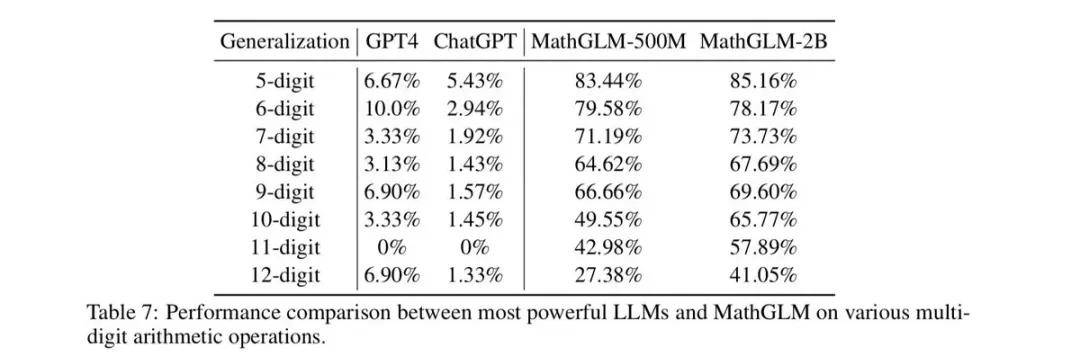
一些人一直聲稱大型語言模型(LLMs)無法進行推理,並且它們是通往通用人工智慧(AGI)的歧途。可能蘋果在嘗試將大型語言模型應用於其產品後終於接受了這一事實,這也可能是它退出對OpenAI投資的原因之一。
即便是目前最先進的o1模型,也不能解決這個問題。

再有,Gary Marcus 還指出,大模型不遵守西洋棋規則。
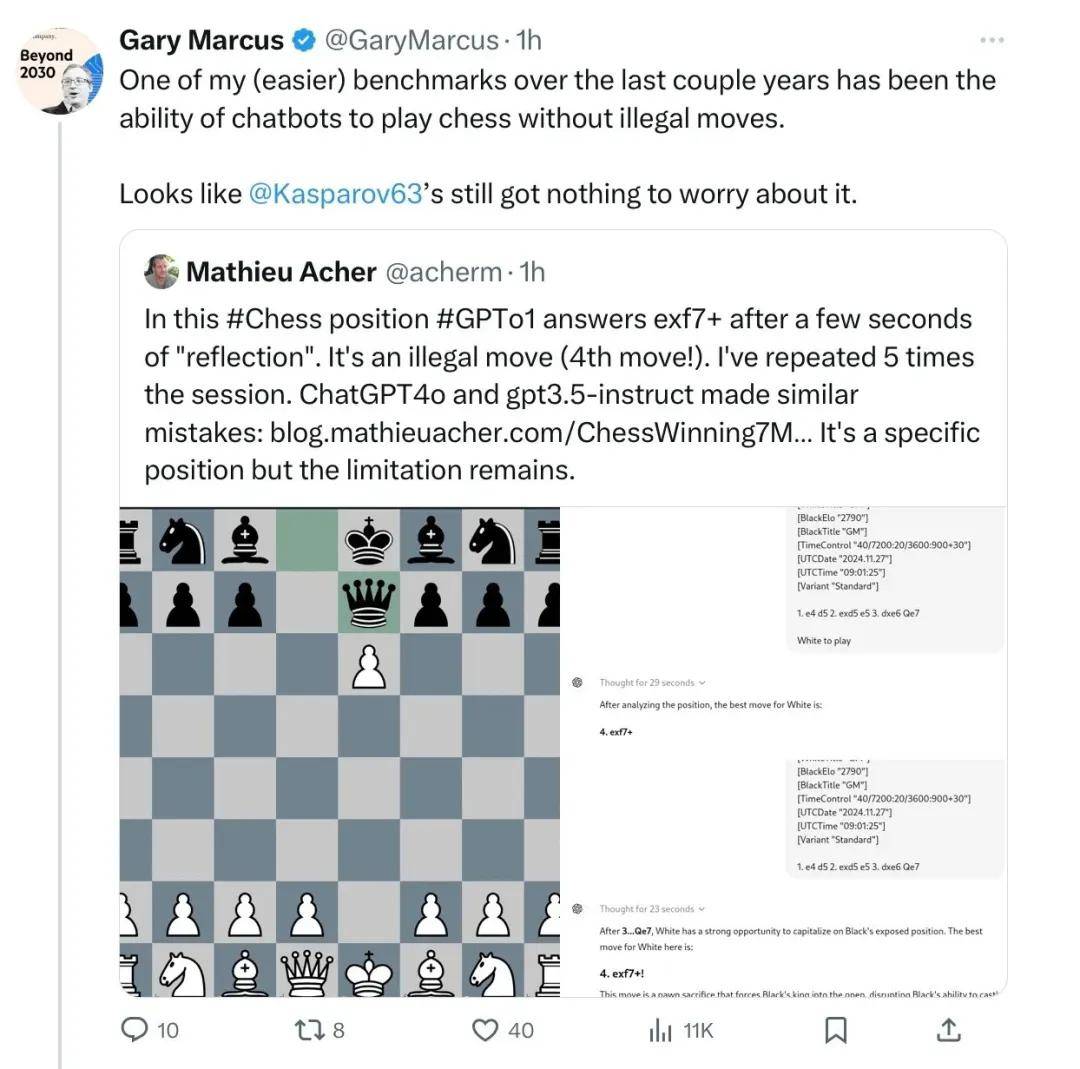
大多數研究人員都在讚揚蘋果的這篇論文,並認為其他人接受大型語言模型無法進行推理這一點也很重要。大型語言模型的長期批評者加里·馬庫斯也分享了多個大型語言模型無法執行推理任務(如計算和象棋)的例子。

04
反對者:這是真的嗎?論文作者混淆了概念
但這是真的嗎?大型語言模型真的不會推理嗎?
不過,反對這一論文結果的也大有人在。
有人認為,蘋果論文的一個問題是它將推理與計算混淆了。「推理是知道用算法來解決問題,而不是全部在腦海中解決,」人工智慧研究者Paras Chopra解釋道,同時他也指出,儘管大多數大型語言模型(LLMs)最終得出了錯誤的答案,但它們確實知道解決問題的方法。他認為,即使答案錯誤,知道解決問題的方法也足以檢查大型語言模型是否在進行推理。
一篇在Hacker News上的討論強調,蘋果公司的研究人員向大型語言模型(LLMs)提出的一些問題試圖「捉弄」它們,因為這些問題中包含了不相關的信息,而大型語言模型無法主動過濾掉這些信息。
推理是在知識領域中逐步、疊代地減少信息熵的過程。OpenAI的o1-preview通過引入疊代更好地實現了這一點。它並不完美,但確實做到了。
亞利桑那州立大學(ASU)計算機科學和人工智慧教授 Subbarao Kambhampati同意,關於大型語言模型具備推理能力的一些說法是誇大其詞的。然而,他表示,大型語言模型需要更多的工具來處理系統2任務(即推理),而「微調」或「思維鏈」等技術並不足以滿足這一需求。
當OpenAI發布o1模型,並宣稱該模型能夠思考和推理時,Hugging Face的執行長Clem Delangue並不買帳。「又一次,一個AI系統並不是在『思考』,而是在『處理』、『運行預測』……就像谷歌或電腦所做的那樣,」Clem 在談到OpenAI如何錯誤地描繪其最新模型所能實現的功能時說道。
雖然一些人表示贊同,但另一些人則認為這正是人類大腦的工作方式。「又一次,人類的大腦並不是在『思考』,而只是在執行一系列複雜的大規模生物化學/生物電計算操作,」Phillip Rhodes回復德朗格道。
為了測試推理能力,有些人還會問大型語言模型(LLMs)單詞「Strawberry」中有多少個「r」,這完全沒有意義。大型語言模型無法直接計算字母數量,因為它們是以稱為「標記」的文本塊來處理文本的。自大型語言模型誕生以來,對它們的推理測試就一直存在問題。
05
寫在最後
每個人對大型語言模型似乎都有強烈的看法。一些人基於Yann LeCun或弗朗索瓦·肖萊(Francois Chollet)等專家的研究,認為應該更認真地對待大型語言模型的研究;而另一些人則跟風批評。有人說它們是我們通往通用人工智慧(AGI)的門票,而另一些人則認為它們只是被美化的、有著花哨名字的文本生成算法。
相比之下,AI大神Andrej Karpathy最近表示,這些大型語言模型或Transformer所使用的預測下一個token的技術,或許能夠解決其他領域之外的許多問題。
雖然在某種程度上,大型語言模型確實能夠進行推理,但一旦將它們付諸實踐進行測試,最終還是會失敗。這並不是什麼新鮮事,反而是一種機會:機器還取代不了人類!