作者 | Claudio Masolo
译者 | 张卫滨
策划 | 丁晓昀
最近,优步在其官方工程博客上发布了一篇 文章,阐述了将批数据分析和机器学习(ML)训练的技术栈迁移到 谷歌云平台(GCP) 的战略。优步运行着世界上最大的 Hadoop 装置之一,在两个区域的数万台服务器上管理着超过上艾字节(exabyte)的数据。开源数据生态系统,尤其是 Hadoop,一直是数据平台的基石。
迁移计划的战略包括两个步骤,即初始迁移和利用云原生服务。优步的初始战略包括利用 GCP 的对象存储作为数据湖存储,同时将数据技术栈的其他部分迁移到 GCP 的基础设施即服务(IaaS)上。这种方式可以实现快速迁移,并将对现有作业和流水线的影响降至最低,因为他们可以在 IaaS 上复制其内部软件栈、引擎和安全模型的对应版本。在此阶段之后,优步工程团队,计划逐步采用 GCP 的平台即服务(PaaS)产品,如 Dataproc 和 BigQuery,以充分利用云原生服务的弹性和性能优势。
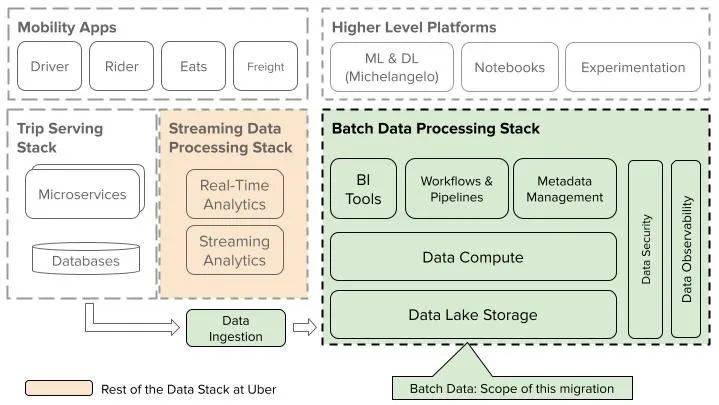
迁移的范围(图片来源:优步博客)
初始迁移完成后,团队将重点集成云原生服务,以最大程度地提升数据基础设施的性能和可扩展性。这种分阶段的方式能够确保优步的用户(从仪表盘的所有者到 ML 的参与者)在不改变现有工作流或服务的情况下体验无缝迁移。
为了确保平滑和高效的迁移,优步团队制定了几项指导原则:
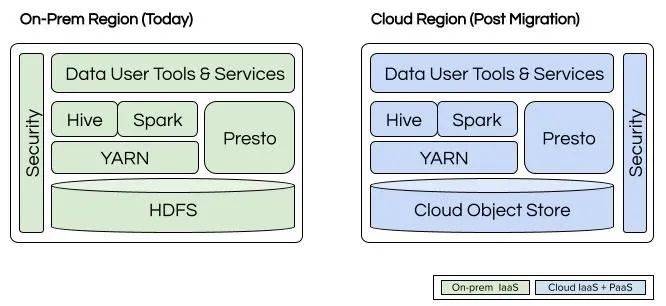
迁移前和迁移后的优步批数据技术栈(图片来源:优步博客)
优步团队重点关注迁移过程中的数据桶映射和云资源布局。将 HDFS 文件和目录映射到一个或多个桶中的云对象至关重要。他们需要在不同的粒度水平上应用 IAM 策略,同时要考虑对桶和对象的限制,比如读 / 写吞吐量和 IOPS 限流。团队的目标是开发一种映射算法,以满足这些约束条件,并按照以组织为中心的层级方式组织数据资源,从而改进数据的管理。
另外一个工作方向是安全集成,调整现有的基于 Kerberos 的令牌和 Hadoop Delegation 令牌,使其适用于云 PaaS,尤其是谷歌云存储(Google Cloud Storage,GCS),这是非常重要的。这个工作方向旨在支持无缝的用户、群组和服务账户的认证与授权,并保持与内部环境一致的访问级别。
团队还关注数据复制。权限感知的双向数据复制服务 HiveSync 能够让优步以双活模式运行。他们扩展了 HiveSync 的功能,以便于将内部环境中数据湖的数据复制到基于云的数据湖和对应的 Hive Metastore 中。这包括初始的批量转移和持续的增量更新,直到基于云的技术栈成为主方案。
最后一个工作方向是在 GCP IaaS 上提供新的 YARN 和 Presto 集群。在迁移过程中,优步的数据访问代理会将查询和作业流量路由至这些基于云的集群,确保平稳迁移。
优步向谷歌云的大数据迁移将面临一些挑战,比如存储方面的性能差异和遗留系统所导致的难以预知的问题。团队计划通过使用开源工具、利用云弹性进行成本管理、将非核心用途迁移到专用存储,以及积极主动的测试集成和淘汰过时的实践来解决这些问题。
查看英文原文:
Uber’s Journey to Modernizing Big Data Infrastructure with Google Cloud Platform (https://www.infoq.com/news/2024/06/uber-bigdata-migration-gcp/)
德国再次拥抱Linux:数万系统从windows迁出,能否避开二十年前的“坑”?
下一代 RAG 技术来了!微软正式开源 GraphRAG:大模型行业将迎来新的升级?
李彦宏:开源模型是智商税;互联网公司开山之举,有赞取消HRBP岗位;小红书大裁员,30%员工丢饭碗?| Q资讯
有赞取消 HRBP 岗位,员工拍手叫好!中国科技大厂的尴尬境地:既要富士康的效率,又要谷歌的创新