
作者 | 程茜
編輯 | 漠影
如今,個人大模型和企業大模型以及在其基礎上發展出的個人智能體和企業智能體,將與公有大模型共存互補,以混合AI形態加速落地。
在此背景下,大模型的形態更加多元、數量增長愈發使得「算力為王」成為當下AI時代的主題,讓「如何用好算力」這件事也被注入了更多新的期待。但這並不意味著「得算力者得天下」,企業更需關注的是如何駕馭海量算力,充分讓算力成為支撐個人智能體和企業智能體在各種行業中應用的養料。

算力的高效利用迫在眉睫。其中,醫療領域在進行大規模數據處理、分析,需要考慮避免算力資源的浪費節省成本;從數字人助教到課程大模型等豐富應用在教育行業出現,需要讓算力足夠支撐這些多元應用……
同時,由於當下生成式AI的應用場景豐富,涉及的算法框架多樣且需要面臨不同的GPU選配、硬體搭配等,這些中間環節都為算力使用者提出了不小的挑戰。未來,算力的利用率將持續攀升,產業焦點正從拼卡、拼硬體堆疊過渡到拼軟體。相比於硬體堆疊,軟體調度在可獲得性、靈活性、可靠性等方面的優勢,成為企業解決當前算力利用率提升困境行之有效的一大解決方案。
聯想集團提出的AI for ALL戰略,在這場混合式人工智慧的競賽中占得先機。在Q4財報發布之際,聯想集團再次發布一支硬核科普視頻,視頻通過UE5搭建了科幻感十足的場景,模擬《沙丘》般的混合算力基建,並輔以AI生成內容等手段,對抽象技術進行了3D立體呈現。

針對企業合理分配調用現有算力的迫切需求,通過拆解算力在企業AI訓練感知、調度、加速、應用的全鏈路流轉,看到聯想集團在層層交織的巨大算力網絡中,如何以混合算力基礎設施軟體為企業抽絲剝繭,將星羅棋布的混合算力單元探索、挖掘、輸送到企業的不同業務需求中。
一、 混合式AI加速落地,企業用好算力面臨三大攔路虎
如今,軟體已成為加速計算的根本必要條件,簡單的硬體疊加部署算力已經難以追趕混合AI步伐,各行各業必須意識到從硬體堆疊向軟體基礎設施轉變才是大勢所趨。
因此,在企業現有的多元化混合算力基礎設施上,亟需更優的混合算力基礎設施軟體釋放全部混合算力資源,這在當下幾乎已經成為企業大模型與業務相結合的必要條件。

但是,充分調度現有的混合算力面臨三大難點。
首先是多元化應用場景與算力匹配的難題。為了滿足AI愈加多元化的應用場景,企業構建的計算集群往往有上百種,不同組合的伺服器、存儲、網絡需要不同的調度方式,同時AI領域目前至少有5種以上的算法框架和10種以上運算元庫,企業的適配難度極高。
第二點在於,集群的故障斷點次數多,恢復成本極高。根據統計,目前業界頂尖的千卡集群,每月至少有15次斷點故障。每月額外費用超過百萬元,常規的斷點續訓技術上,每次故障恢復時間達到2個小時,使得訓練效率大幅降低。
並且現在規模更大的萬卡集群出現,其面臨的故障中斷次數及恢復時間也呈指數級增長。
第三點則在算力利用率方面,出乎意料的是,AI模型算力利用率MFU(Model FLOPs Utilization)普遍在30%左右,幾乎有超過一半的算力被浪費,大量算力仍處於閒置狀態,在算力供需不平衡的當下,提高算力利用率至關重要。

這些難題無疑給算力使用者、AI基礎設施提供者帶來了不小的挑戰。但挑戰背後正是歷史機遇,聯想集團作為算力基礎設施提供者在技術積累、產品創新、應對挑戰上齊頭並進,為算力使用者帶來了更佳的創新解決方案。正如聯想集團董事長兼CEO楊元慶在聯想創新科技大會Tech World上所說:「人工智慧變革不是一場集成商的角逐,而是一場創新者的賽跑。」
二、拆解混合算力基礎設施軟體,全流程為企業釋放算力資源
數據中心往往由三種集群構成,包括服務於AI的集群、通用計算集群、高性能計算集群,它們共同為企業的計算需求效力。但因調度器不同,這三種集群存在調度壁壘——使得企業的AI需求無法調度全部GPU資源,部分昂貴的GPU資源閒置,這在AI需求緊迫的當下已經成為企業一大桎梏。

4月18日,聯想集團在2024 Tech World上最新發布了聯想萬全異構智算平台HIMP(Lenovo wanquan Heterogeneous Intelligence Management Platform)。面對企業算力應用困境,它能夠極致壓榨企業混合算力資源,讓算力充分為企業AI訓練所用。

視頻中頗具視覺衝擊力的「四稜錐」,便是聯想的混合算力基礎設施軟體HIMP,在企業AI訓練的感知、調度、加速、應用全鏈路過程中助力各行各業釋放全部的算力。
首先要感知和調度算力,這是其合理分配算力資源的關鍵,也構成算力使用的基礎。
針對不同計算集群間調度存在壁壘,無法將全部GPU資源為AI需求所用這一痛點,聯想HIMP的一大獨創性就是能跨越集群間不同網絡定位擁有最優訓練速度GPU的拓撲感知機制。視頻中在三維空間中不斷變化的網絡拓撲動畫,打破了不同集群間的調度壁壘,成為算力網絡中的重要一環。拓撲感知機制可以使千卡集群的網絡通信效率提升10%-15%。
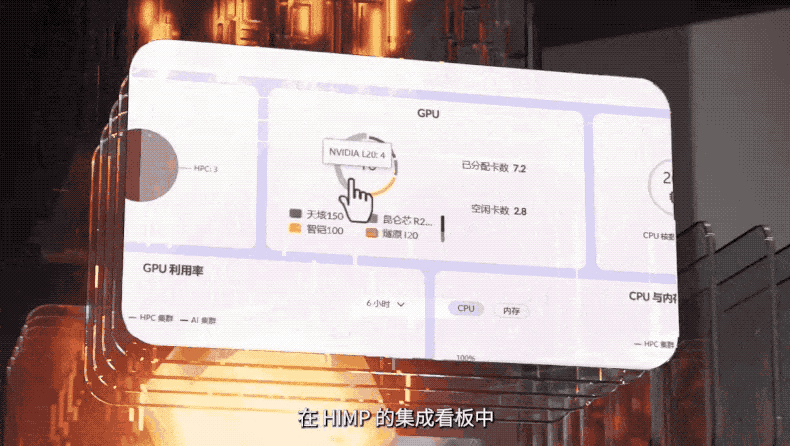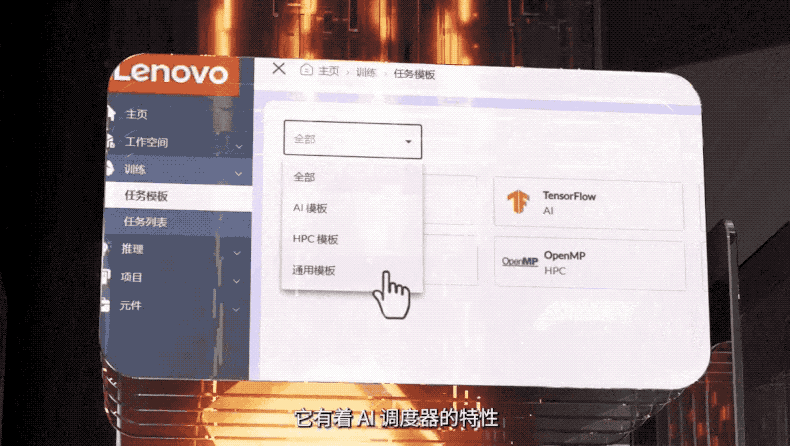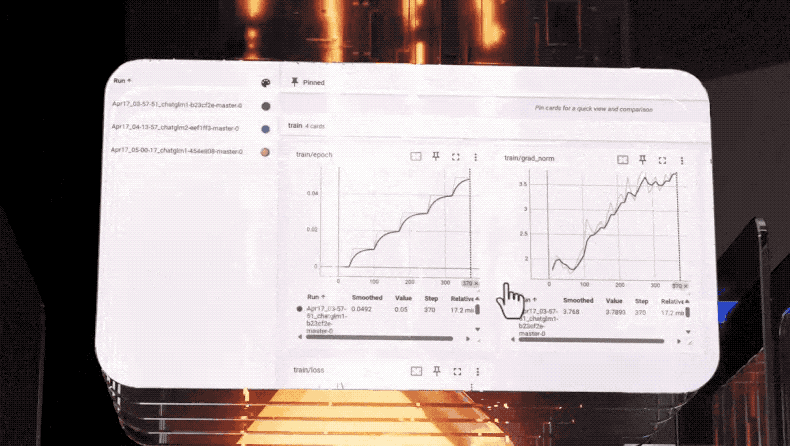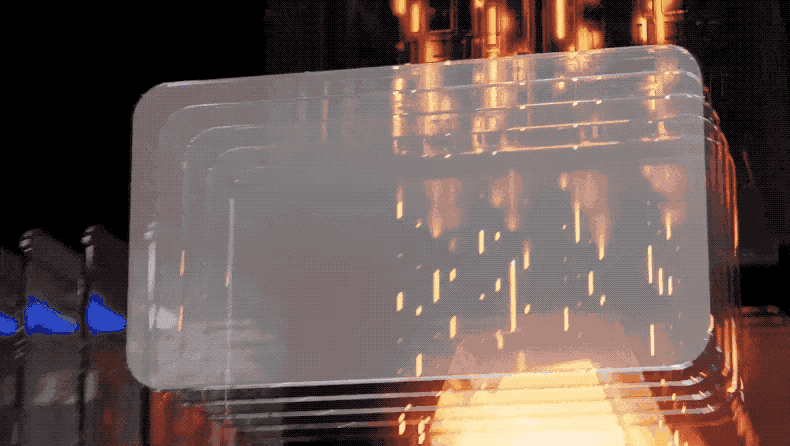
同時,聯想集團打造的超級調度器,可以一舉盤活AI集群、通用計算集群、高性能計算集群。通過一個面板,能夠清晰看到聯想HIMP可以實時感知、監測和收集算力數據以及不同業務的算力需求,通過分析相應數據進行算力的合理分配與調度,將所有GPU資源為AI所用。
合理分配之後的下一步就是如何讓算力加速。
往往在企業AI訓練過程中,幾乎有一半的響應時間會在網絡中被消耗,網絡通信速度慢直接影響算力的使用效率。
聯想集團以近似於「蟻群覓食行為」的集群調度算法,為AI計算提速。視頻通過蟻群算法的仿生學比喻超級調度器,生動再現蟻群在複雜的環境中,駕輕就熟地找到最佳路徑,減少網絡中消耗的時間。

同時,為了驗證大模型訓練的效果,其中會夾雜部分推理任務。正如視頻中從訓練任務中分離而出的紅色小方塊,其所需的算力資源小,不需要占滿整顆GPU。以往用戶會在作業系統層進行GPU虛擬化的算力分配,這過程中,會產生大概20%的算力損耗。
因此,為了提升算力的使用效率,聯想HIMP的另一大獨創性就是GPU驅動層的內核態虛擬化技術,視頻使用三維動畫展示了GPU在驅動層的虛擬切割,代表推理任務的紅色方塊在其中極速飛梭,使GPU成為一個算力蜂巢。推理任務之間能實現任務隔離,單獨任務分開計算。算力在虛擬化過程中損耗可以降到5%以下,在極致情況可以降到1%以下,幾十張卡實現「千卡集群」,驅動企業的混合算力應用率提升。

最後就是應用層面,這也是算力被可持續利用起來,保證成功率的關鍵。
AI訓練中任一節點故障都會導致整個集群停擺。聯想集團創新性提出以模型之力拯救模型,通過對大量AI訓練故障進行特徵採樣,構建了可以預測AI訓練故障的模型。
如視頻中呈現的藍色粒子向集群輸送任務時,遇到故障就會迅速在旁路藍色粒子中備份,使斷點續訓的恢復時間從幾小時減少到一分鐘,大幅提升了企業的訓練效率。

聯想集團的異構智算平台HIMP打通了全部的算力網絡,這一全流程AI訓練框架落成,使得AI模型算力利用率MFU(Model FLOPs Utilization)大幅提升。在混合AI落地的需求背景下,聯想集團的混合算力基礎設施軟體調度加持,助力企業釋放全部混合算力。
聯想HIMP也成為AI 2.0時代聯想集團AI基礎設施戰略框架的核心,大模型訓練和推理的基礎設施底座。
結語:極致壓榨算力潛能,直面算力指數級增長
生成式AI浪潮席捲千行百業,正如這支可視化財報科普解讀視頻所提到的:「AI所帶來的新工業革命,本身就是人類對算力這一資源的挖掘和應用」。在算力資源稀缺的背景下,作為AI基礎設施的行業領軍者之一,聯想集團正循序漸進去極致壓榨算力資源推動AI基礎設施釋放最大動能,讓企業充分利用好海量算力,與搭載個人大模型的AI PC一起助力混合AI時代加速到來。

過去20多年,PC網際網路和移動網際網路引領了網際網路產業革命,並帶動了相應的基礎設施產業繁榮,如今AI有望應用於千行百業,放眼未來10年,對於AI技術的強大需求將催生一個指數級增長的算力市場,基礎設施巨頭聯想集團正立於潮頭,成為守在風口的先行者。