專家解讀化學諾獎:如果沒有今年的化學獎,可能就沒有物理學獎

嘉賓:馬劍鵬 (國際著名計算生物學家、復旦大學複雜體系多尺度研究院首任院長)
整理:深究科學
蛋白質結構預測的歷史回顧
蛋白設計也好,蛋白質結構預測也好,它歸根到底跟一個問題有關係,就是叫蛋白質摺疊。
我先來簡單解釋一下什麼叫蛋白質摺疊。我們知道,蛋白質首先是有空間結構的,而且有很多蛋白的空間結構是唯一的。蛋白質的胺基酸序列,是由遺傳密碼來決定的。遺傳密碼是一維的,所以它這裡有個問題,就是如何由一維的蛋白質序列記住這個三維的結構,這就是所謂的蛋白質摺疊問題。
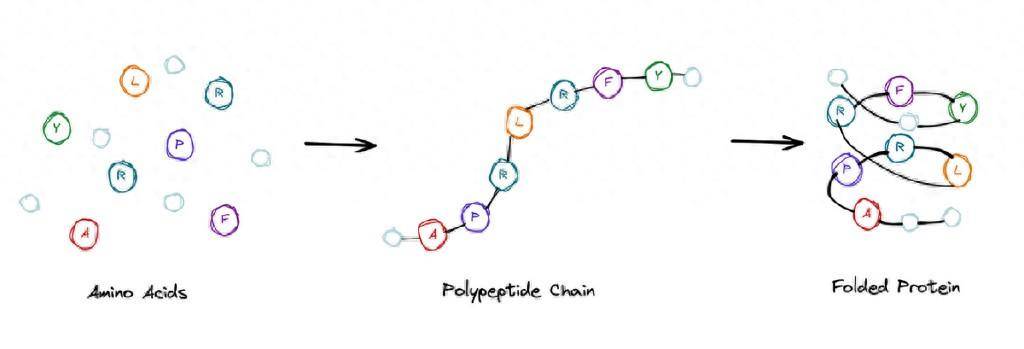
那麼,為什麼這個問題那麼重要?有人說這個問題是太陽底下最難的一個科學問題之一,也是上個世紀末生物學裡面所謂的一個「皇冠上的珍珠」。誰能解決這個問題,就肯定能獲得諾貝爾獎,所以很多人都在為之努力。
這裡有個關鍵,組成蛋白質的胺基酸主要有20種,胺基酸殘基是線性連接的。大家可以從科普的角度上想像,它是一個胺基酸的鏈,就像一串珠子,一串念佛珠。如果這個珠子一共有20種不同的顏色,所謂的20種不同胺基酸的系列,把這串珠子往水裡一放,它會很快摺疊成每次折都一樣的三維結構。
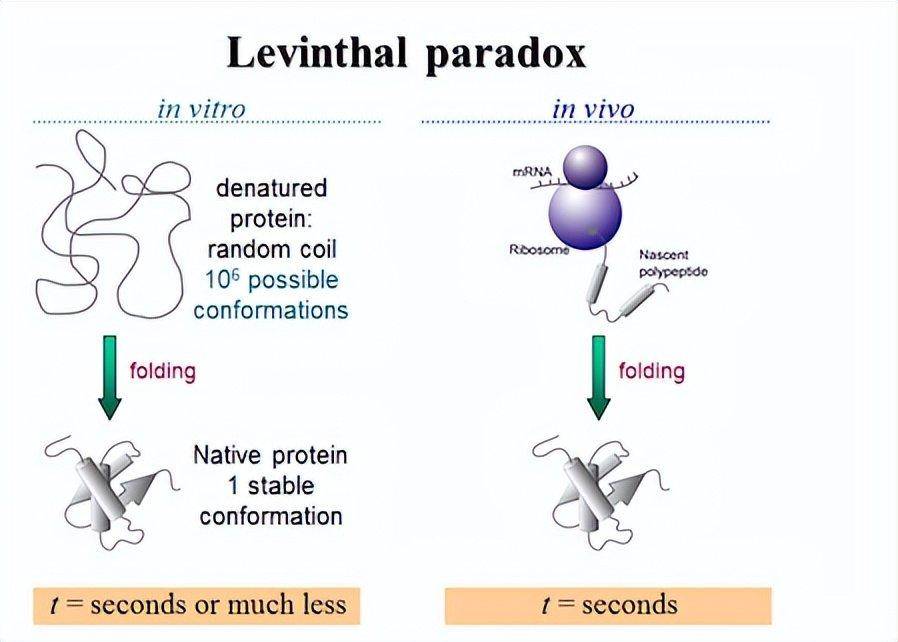
問題是,如果這個鏈的摺疊過程是一個窮舉的過程,要把這條鏈從展開的構型摺疊成最後一個三維唯一的結構,這需要的時間可能會比宇宙的壽命還長。但事實上,蛋白質鏈在細胞裡面被合成的一瞬間就很快就折起來了,折的速度遠遠比1秒鐘要快。
這就來了一個問題,它怎麼折的?因為它沒有腦子,就是水裡面有一些物理作用之類的這麼折起來。蛋白摺疊會非常快,所以這裡顯了一個悖論,到底是怎麼摺疊起來的?這就是著名的蛋白質摺疊問題和著名的利文索爾悖論(Levinthal's paradox)。
從上個世紀中葉到現在,無數的前輩一直在孜孜不倦地研究這個問題,包括我們研究院的榮譽院長、2013年諾貝爾化學獎得主麥可·萊維特(Michael Levitt)教授等人。隨著時間的歷史推移,這個問題慢慢地就分化成了兩個問題:一個是蛋白質為什麼會這樣,或者它是怎麼摺疊的;另一個問題相對比較實用一點,蛋白質結構預測問題。
關於第一個問題到現在還沒有完全回答好,而第二個問題就是給你一個蛋白質的序列,告訴它最後的摺疊結構就行,只關心終點,不關心怎麼來的途徑。關於途徑這個事情是個基礎科學問題,也是個物理學問題,很多人還在搞這個東西。
但後面這個問題,隨著時間的推移,一開始做物理的人更起勁在回答,由於實用性的結構預測是非常困難的,所以幾十年來有人孜孜不倦地在做,進步不是很大,但是有那麼些人在做,包括今年獲得化學獎得主David Baker,他這麼多年一直在這個行當裡面,是一個領軍人物,做得比較好,但是他在很長時間內預測精度也只有40%。
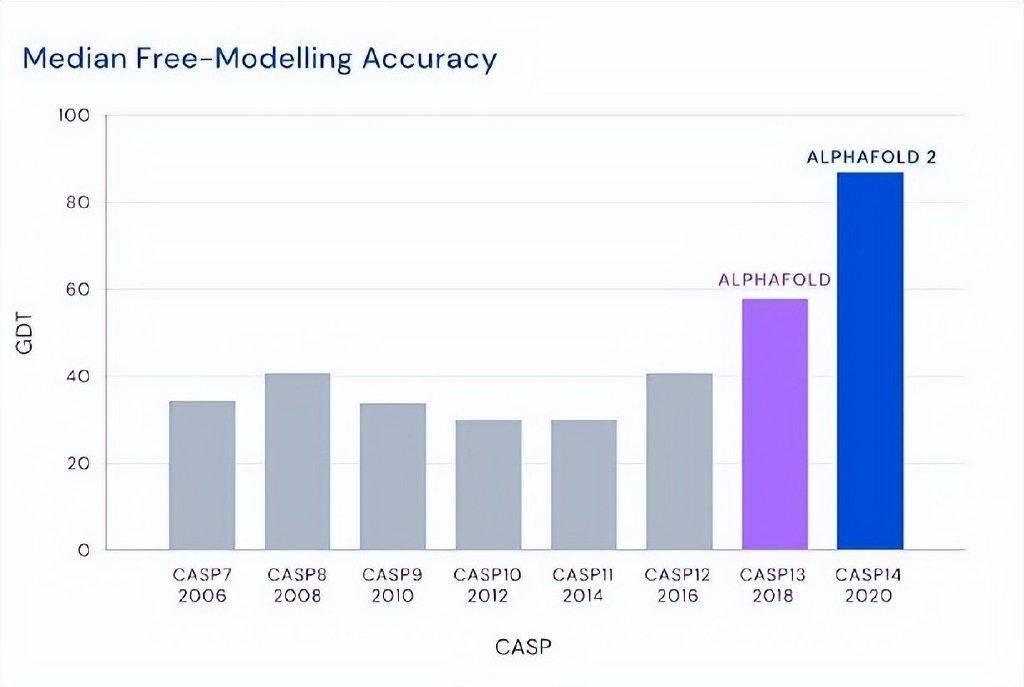
這個精度是指一個非常著名的國際比賽——關於蛋白質結構預測關鍵評估(CASP)的比賽。我們團隊也參加這個比賽,做了很多努力。麥可·萊維特50年前創的這麼一個行當,就是因為他一直是做計算的,他企圖用計算機來預測這個問題,但精度一塌糊塗。由於這個問題非常重要,所以大家一直在做,但我說的精度一塌糊塗,就是說當年用計算機來預測出來的蛋白結構,就算達到40%的精度,也不足以讓生物學家或者做實驗的工作者覺得這是有用的。
然而,突然有一年,大概四五年前吧,出了個Alphafold。這個Alphafold第一次把這個精度從40%提高到60%,已經讓人很震驚了。再過了兩年,到CASP14的時候(2020年),它一下子達到了88%,88%這個數字很重要,因為實驗的測定精度也只有90%,所以你接近88就接近90了。大家覺得這個問題幾乎解決了,全世界都為之震驚。
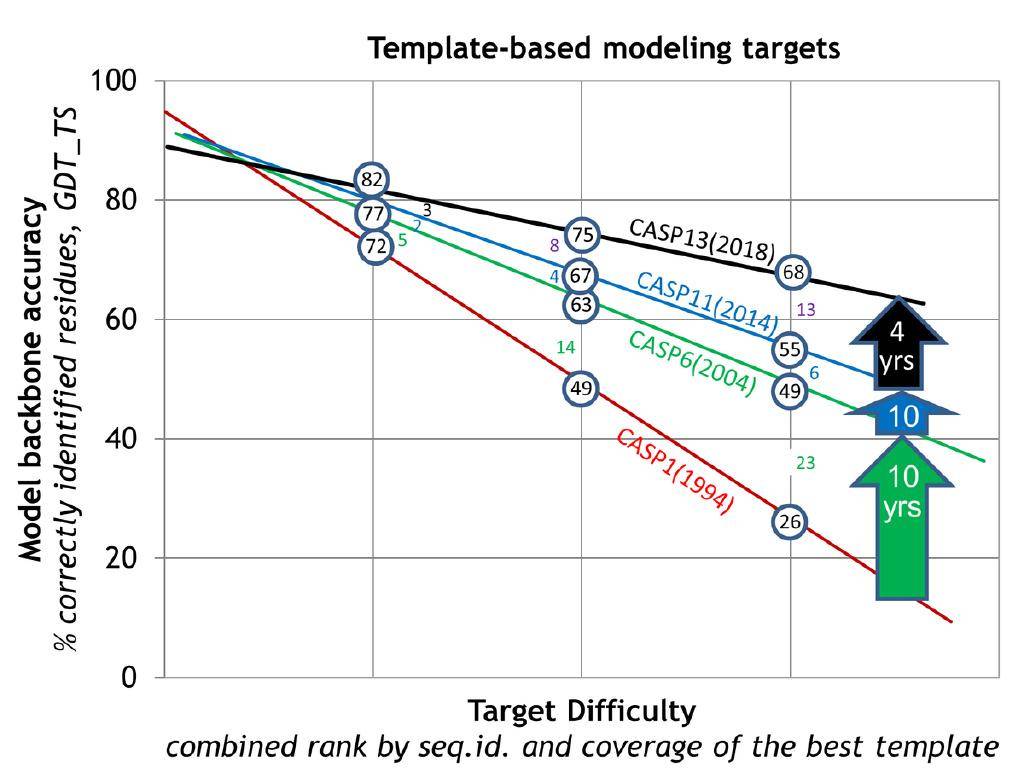
這裡要強調一點,像麥可包括我就做這個行當的,大家孜孜不倦地在做,但我們都清楚,一路走來,這個問題計算機預測是不可能在我們有生之年得到解決的,當年我們這些人是這樣走過來,沒想到兩下子,Alphafold 1、Alphafold 2一下就到了80%多,現在又有Alphafold 3了。
這個就是歷史,非常簡約的歷史。
AI變革蛋白結構預測、蛋白設計
現在來講講這個Alphafold是怎麼突然間兩步就到位,幾乎做成了結構預測,就是AI框架,在Alphafold 1出來以前,包括David Baker都是在用計算的。我現在講的全都是用計算機預測蛋白質結構。

絕大部分人都不是用AI,也有一些人在用AI,但AI在這方面的展示結果並不好,都是用一些其他的物理方法,包括Baker,尤其是Baker。Baker以前不是用AI,我也不是,麥可也不是,但就是因為這個deep learning(深度學習)方法的介入,導致這個精度有了突飛猛進的進步。那麼,這就要說到AI技術,這是兩條不同的路徑。
今年諾貝爾物理學獎給了AI領域,而化學獎則給了在蛋白質預測上有突出貢獻的AI技術。在不久以前,大家都記得AI曾經打敗過西洋棋,當時大家覺得不得了,西洋棋已經被AI打敗了,但是後來什麼事情沒有發生,因為你要打敗西洋棋,拿個計算機就可以窮舉,你要把世界上所有的棋譜都學進去了,因為一個高手下棋不是要多想幾步嗎?計算機肯定比你想的快,它把所有的路都走完了,那把你打敗也不奇怪。
deepmind公司的這幫人,尤其是今年諾貝爾獎的第二個得主哈薩比斯,他是一個計算機工作者,他就去找了一個科學問題,不僅找了個科學問題,還找了個太陽底下最難的科學問題,就是蛋白質結構預測問題。這個問題不是個新問題,它早就在那裡存在的,Baker包括我們一直在做。他就撿起了這個問題,把這個問題朝前推了一大步,於是就有了Alphafold 1和Alphafold 2。
這下全世界整個變過來了,科學家也開始注意,原來AI這麼厲害。這就是為什麼現在有一個非常熱門的詞,叫AI for Science。以前從來沒聽說過,AI for Science裡面,AI不是什麼新詞,AI很多年了,Science更是有悠久的歷史。為什麼現在才想起來叫AI for Science?原來這兩個東西關聯性不是太大,就是說AI本身是一個算法,或者是個工程技術,傳統的做AI的人都是做視覺、人臉識別、無人機操控、自動駕駛之類工程問題上的應用,它的難度跟蛋白質摺疊是根本沒法比的。蛋白質的確是非常非常難,所以我說,大家都認為它是太陽底下最難的一個科學問題。
那麼,居然在這麼難的問題上朝前跨了一大步,所以現在它直接的效果就是導致AI for Science的出現,而且現在我們已經是人生無處不AI。原因很簡單,就是大家全世界無論是做Science的人,還是其他領域的人,都注意到現在的這個deep learning這個東西,居然把這麼難的一個科學問題也可以往前推這麼一大步,那稍微簡單點的(科學問題)就更容易了,所以這廣泛的就應用開了。
今年物理學獎和化學獎的相互成就
今年諾貝爾化學獎,其實分兩撥人。第一個就是Baker,後來是哈薩比斯和賈伯,哈薩比斯和賈伯是一個團隊的,他們就是做Alphafold的那兩個人。Baker跟Alphafold理論上沒有關係,這不是他發展的,但他後來包括現在也在用。那為什麼得這個獎?
自從用計算機可以用來預測蛋白質結構,所謂預測蛋白質,無非就是蛋白質結構建模,只不過是這個模型不是用實驗數據來檢測的,是用計算機來建的。有了這個能力以後,這個行當裡面就可以大致分為兩大問題:一個就是大家孜孜不倦地在追求的蛋白質摺疊問題,我給你一個序列,你把它對應的結構給我弄准,這就是摺疊問題,那也是Alphafold最大的貢獻之一,它可以把蛋白摺疊弄得比別人好得多得多。Baker也是做這個問題出身,Alphafold 2那兩個人也是在這個時候有巨大的貢獻。
諾獎委員會專門點了下蛋白設計,它的區別在於,這兩個問題的關聯度是極大,但也不完全是一回事。這兩個東西的本質要求是必須得有一個蛋白質序列,把它的結構查一查。但是以前,我們連自然界已知的蛋白質序列給你,也未必搞得准。不是40%,對吧?後來88%了嘛,那你何來談設計?
它區別就是純粹的摺疊,那就是把一個已知的序列,你把它結構弄准了就行了。但是設計顯然是指你要設計一個自然界不存在的蛋白序列,至少是經過修改過的序列,那就說設計更難,但設計的底層邏輯肯定也是摺疊,你不會摺疊,你設計什麼?但是會摺疊不等於說你一定會設計。

在這兩個方向上面的做世界上做摺疊其實是非常多,Baker當然是個領軍人物,後來就被Alphafold給取代了。但是Baker在Alphafold出來以後,他也踉蹌了幾步,因為他的摺疊精度一下子被Alphafold給碾壓了。但是他又很快崛起了,他最近幾年主要是在設計上。所以諾獎裡面就講了很清楚,也就強調了蛋白設計這個事。
我一直講,蛋白質的摺疊是個基礎科學問題,但蛋白質設計是一個藝術,就是你到底設計什麼,這個選項是非常多的。那麼這個時候,我要不得不強調一下,為什麼把這個給Baker在這個獎裡面。諾獎裡面說David Baker主要以設計為主,其實他也是做摺疊出來的,在Alphafold以前,他在摺疊方面是做得最好。但是做設計,他在全世界幾乎就是一個望塵莫及的存在,很多團隊都企圖做設計,但是做不過Baker。
做摺疊還是有很多人,而且還有幾個人不見得比Baker做得差,可能Baker做得比較早。但是設計是怎麼也做不過他,這裡面當然有很多的原因,但是我認為有個很主要的原因,就是Baker的團隊除了很有錢,可以招到很多優秀的人才以外,他會做實驗。Baker本人是做實驗出身的,其實他後來改行做計算蛋白結構預測,這就充分說明了在蛋白質建模,尤其在設計這個行當裡面,必須要乾濕結合,不僅要有預測,設計也是先有預測,然後你要用濕實驗去驗證,就是設計出來的東西是很難繼續用計算的方法來判別設計得對還是錯,以及它的合理性。其實有一部分可以使用計算的,但是不可能100%的准,最後還是要通過濕實驗來驗證。
當然,做設計的人也可以去找一個實驗團隊跟你合作,但是合作一般比較難。這個Baker組的強項就在於此,他們本團隊就有很強大的這個實驗工作能力,所以說他的蛋白設計什麼時就「噴」地一下出來了,這就是個關鍵問題。所以諾獎這三個人裡面,Baker就是這個方面的貢獻。其實他一方面是前面我也講過摺疊也做得不錯,但是我剛才講了,如果這個獎是給蛋白質結構預測的話,不應該光給Baker,肯定還有別的人。但是要強調設計的話,那它確實是獨樹一幟的。
那後面兩個人是顯然獲獎的,那是Alphafold的發明人,因為他們把精度給猛推了一把。Alphafold這個方法主要是基於deep learning,deep mind公司做出來的,或者現在他們公司分出來就叫Isomorphic Labs。它是很了不起的,它的成功帶動了一系列的應用。但我必須要強調一下,就是說其實Alphafold到今天為止,至少Alphafold的成功,它對AI這個領域的貢獻或者它的影響力,就是它的作用,其實遠遠大於對蛋白質本身的影響。
因就是說Alphafold,包括現在Alphafold 3也是,它雖然很強大,但蛋白質結構預測也好,蛋白質建模這個問題並沒有被解決,它只是往前推了一大步。但是它的偉大之處在於不僅把這個這個問題往前推了一大步,雖然它沒有完全解決,它向全世界展示,你看,我在這麼難的問題上也能往前爬一大步,那其他問題就更容易了。所以才導致了整個AI被全世界徹底接受,而且每個人都在用AI。
這也是為什麼今年的物理學家給了AI這個獎項,他們去找回了他們原始的、這個最早的創始人。但是應該說,如果沒有化學獎這幾個人的成功,雖然化學獎發在物理獎後面,今年的物理獎是不會給AI的。
那未來AI應該做什麼?那其中有一個使命,其實它更重要的使命多了,就是要來解決它兩端能不能統一起來,就是數據驅動和邏輯驅動這兩樣東西。其實你看它這個獎,尤其是物理學獎,它如果離開統計力學沒有那麼遠的話,這兩者統一起來是有可能的。這也是AI界的一個前沿問題。
Alphafold預測蛋白側鏈有短板
AF就是AlphaFold的成功,它對AI行當的衝擊要比對蛋白質(結構預測)本身要大。怎麼來理解?首先一點,我剛才說我們做蛋白質結構的側鏈,側鏈結構預測當中的一個分支就是蛋白質結構。蛋白質本來就有主鏈和側鏈,我們花了很大的力氣,現在還在做這個事情來分析。
就是AlphaFold 2也好,AlphaFold 3也好,它吐出來的結果,不是說它80%或者怎麼的,這個精度很高,它到底走到哪,到底還有什麼問題?其實,這是個非常非常聚焦的一個問題,或者是專業問題。它其實主要的誤差就在側鏈上。

我這麼說的話,是有數據的。我並不是否認AlphaFold的貢獻,它的貢獻無窮大,但是它並沒有解決這個問題,我覺得這個就是其中的一個原因,因為它的側鏈不夠准。所謂的側鏈不夠准,嚴格來講,應該是這麼說,就是說如果要是從藥物設計的角度講,藥物設計、藥物分子,大部分都是跟側鏈相互作用的。要是從那個角度講,純粹的,注意純粹地用AlphaFold來預測結構是不夠的,絕大部分情況下是不夠的。
但是這不等於說AI在新藥創新上就無能為力了,相反它很有用。也就跟剛才講的一樣,如果你來摺疊,我說這個摺疊是憑空摺疊,就從序列開始,把這個把結果搭起來,都能搭得那麼好,雖然不是100%,主鏈側還有很大的誤差,那其他的問題,比方說小分子篩選,或者腫瘤診斷、製藥,它有很多的環節,幾乎每個環節上都可以來用,就這麼來。你不能把AI賦能新藥創新,就等價為是AlphaFold的這個預測,那就是兩碼事情。
計算生物學未來的發展潛力
因為藥大部分都是跟蛋白相互作用。有些小分子藥,是跟蛋白作用,或者是蛋白質藥,那就是跟另外的蛋白質相互作用,或者是核酸藥,核酸最後也要跟蛋白質相互作用。當然核酸也有可能跟核酸相互作用,這個是毋庸置疑的。但這個結構設計問題,其實是非常好,就是說Alphafold 3,最近在朝著這個方向上邁出了一個非常好的方向,但這個問題還遠沒有得到解決。怎麼回事?就是說Alphafold 1好,Alphafold 2也好,David Baker也好,雖然今年諾獎的主題就是蛋白質結構的預測,對不對?
為什麼AI、deep learning這套東西在蛋白質結構理論上取得了巨大成功?原因很簡單,因為蛋白質結構已經有幾十年的發展史,就是很多代的科學家做實驗,他們累計了很多的數據。有個Datebase(資料庫)叫PDB,protein database bank。正因為他們幾十年的累積,提供了很多蛋白質結構的信息,才有可能讓AI去學一把。所以這個蛋白質結構數據就建得比較好,這是數據驅動(data driven)的科學問題。
但世界上還有別的東西,還有生物材料,或者其他的各種東西,它就沒有那麼多的結構信息讓AI去學。這個時候怎麼辦?AI還能起作用嗎?這個問題AI就是做不到。你看Alphafold 2,不要說其他的生物材料,哪怕是蛋白質和核酸相互作用,或者蛋白質和小分子作用它也做不好。
這個方向朝前邁了不小的一步,但沒有解決這個問題,不過這個方向是好的。所以,未來我相信,凡是生物學,哪怕包括化學,都會受到它巨大的影響。
今年2個諾獎給AI,下一步如何開闢未開墾的領域

某一個領域得了諾貝爾獎,這肯定是好事。為什麼?這個領域受到了諾貝爾獎的肯定。我給你舉個例子,今是2024年,它是給了AI。2013年,麥可·萊維特和我的博士生導師馬丁·卡普拉斯,他們獲得諾貝爾獎的時候,我們這個領域當然是非常振奮的。

在這個以前,計算生物學,尤其是像搞我們這種蛋白質結構計算的人,是不受待見的。什麼意思?就是做實驗的人是不把我們當回事,認為你這個東西沒用,你們自己一群做理論的人,自己在那自娛自樂。確實是這麼回事,是一個輔助性的學科。但他們2013年諾獎的成功,已經把計算生物學這個重要性顯著地抬出來、抬上去了,但是還不夠。

那現在Alphafold的成功,起初還沒有獲諾貝爾獎。就是前幾年,它一下子讓計算生物學從一個不太受人待見的、一個所謂的輔助性學科,而且它也比較難,因為它是個交叉學科,傳統的學者、傳統學生物的人做不了,傳統學物理、數學的人又不懂生物,這確實是比較難。Alphafold的成功已經讓計算生物學從一個所謂的輔助性學科變成了一個引領性科學,那現在諾獎已給(計算生物學領域),無論從AI算法本身,今年物理獎的肯定,又再加個化學獎,即在Science上的應用,那後面前途是無法估量。
當然了,你還可以反過來問這個問題:這個問題諾獎都給了,你還應該幹什麼?那不就沒有創新了?這個也是一個很有哲學意義的問題。就是說,首先他被授予了諾獎,說明這個問題很重要,而且大家會大發展起來。但是那些領頭羊們、要搞探險創新的人確實應該去想想,下一步未開墾的東西是什麼?因為諾貝爾獎就不會給兩次。
審核:梁前進 北京師範大學生命科學學院 教授
出品:中國科協科普部
監製:中國科學技術出版社有限公司、北京中科星河文化傳媒有限公司

舉報
評論 4