
簡介
檢索增強生成(Retrieval Augmented Generation,簡稱「RAG」)是一種自然語言過程,它涉及將傳統檢索技術與LLM(大型語言模型)相結合,通過將生成屬性與檢索提供的上下文相結合來生成更準確和相關的文本。最近,這種技術在聊天機器人開發中得到了廣泛的應用,使公司能夠通過使用其數據定製的尖端LLM模型來改善與客戶的自動化通信。
Langflow(https://github.com/langflow-ai/langflow)是Langchain的圖形用戶介面,Langchain是LLM的集中式開發環境。早在2022年10月,LangChain就發布了,到2023年6月,它已成為GitHub上使用最多的開源項目之一。可以說,如今LangChain席捲了整個人工智慧社區,特別是為創建和定製多個LLM而開發的框架,這些LLM具有與最相關的文本生成和嵌入模型集成、連結LLM調用的可能性、管理提示的能力、配備向量資料庫以加速計算的選項,以及將結果順利交付給外部API和任務流等功能。
在這篇文章中,我們將使用著名的開源鐵達尼號(Titanic)數據集(https://www.kaggle.com/datasets/vinicius150987/titanic3)展示如何使用Langflow開發一個完整的端到端RAG聊天機器人。
使用Langflow平台開發RAG聊天機器人
首先,需要在Langflow平台(https://astra.datastax.com/langflow/)進行註冊。為了開始一個新項目,可以根據用戶需求快速定製一些有用的預構建流程。本文中要創建一個RAG聊天機器人程序,最好的選擇是使用向量存儲(Vector Store)RAG模板。圖1顯示了這種方案的原始操作流程。
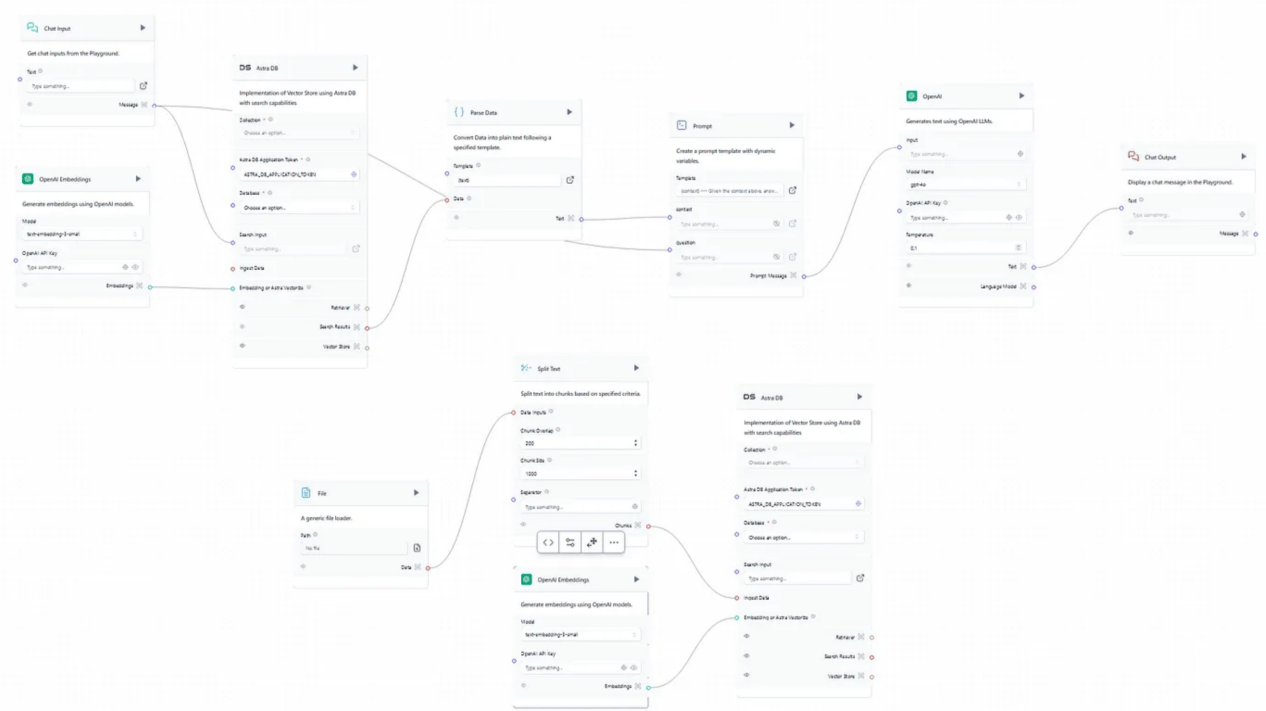
圖1:Langflow向量存儲RAG模板流
在上述模板中,為嵌入和文本生成預先選擇了OpenAI,這些是本文中使用的技術;但是,其他一些選項,如Ollama、NVIDIA和Amazon Bedrock等,也都是可用的,只需設置相關的API密鑰即可輕鬆將其集成。值得注意的是,在使用與LLM提供程序的集成之前,要檢查所選的集成是否在配置上處於活動狀態,如下圖2所示。此外,可以定義全局變量,如API鍵和模型名稱,以便於對流對象進行輸入。
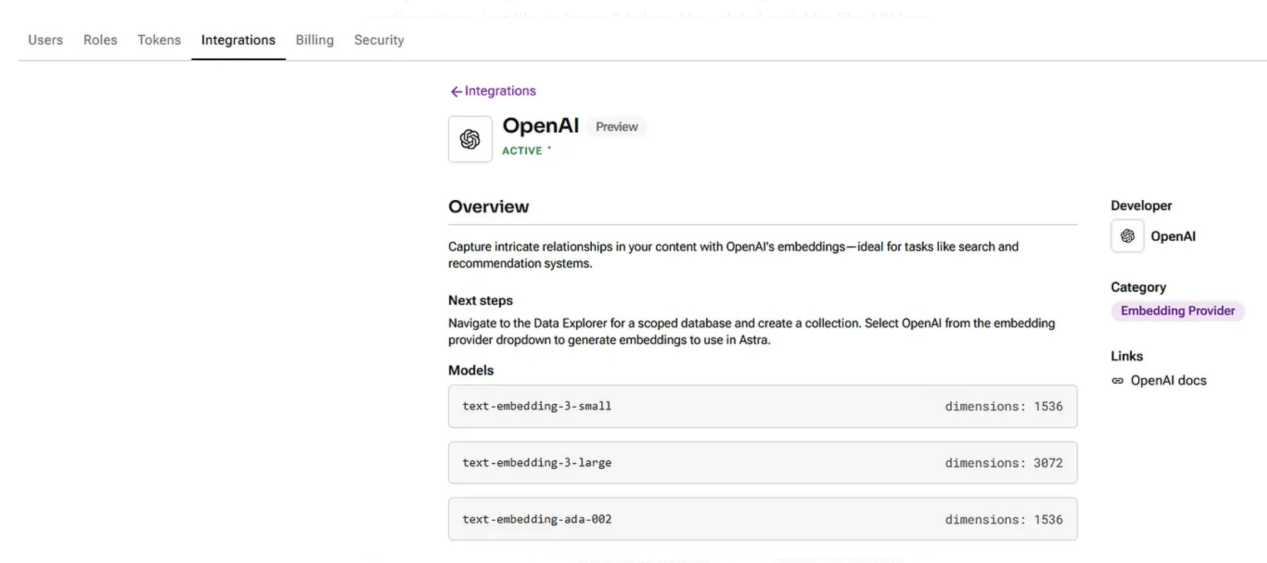
圖2:OpenAI集成和概述的介面
向量存儲Rag模板上提供了兩種不同類型的流。其中,下面的一個顯示了Rag的檢索部分,其中通過上傳文檔、拆分、嵌入,然後將其保存到Astra DB(【譯者注】。Astra DB是一個基於Apache Cassandra的開源雲原生資料庫服務,它提供了強大的向量存儲能力,非常適合用於構建RAG系統)上的向量資料庫中來提供上下文,該資料庫可以在流介面上輕鬆創建。
目前,默認情況下,Astra DB對象能夠自動檢索Astra DB應用程式令牌,因此甚至不需要收集它。最後,需要創建將嵌入值存儲在向量DB中的集合。為了正確存儲嵌入結果,集合維度需要與文檔中提供的嵌入模型中的維度相匹配。因此,如果你選擇的嵌入模型是OpenAI的text-embedding-3-small的話,那麼創建的集合維度必須是1536。下圖3顯示了完整的檢索流程。
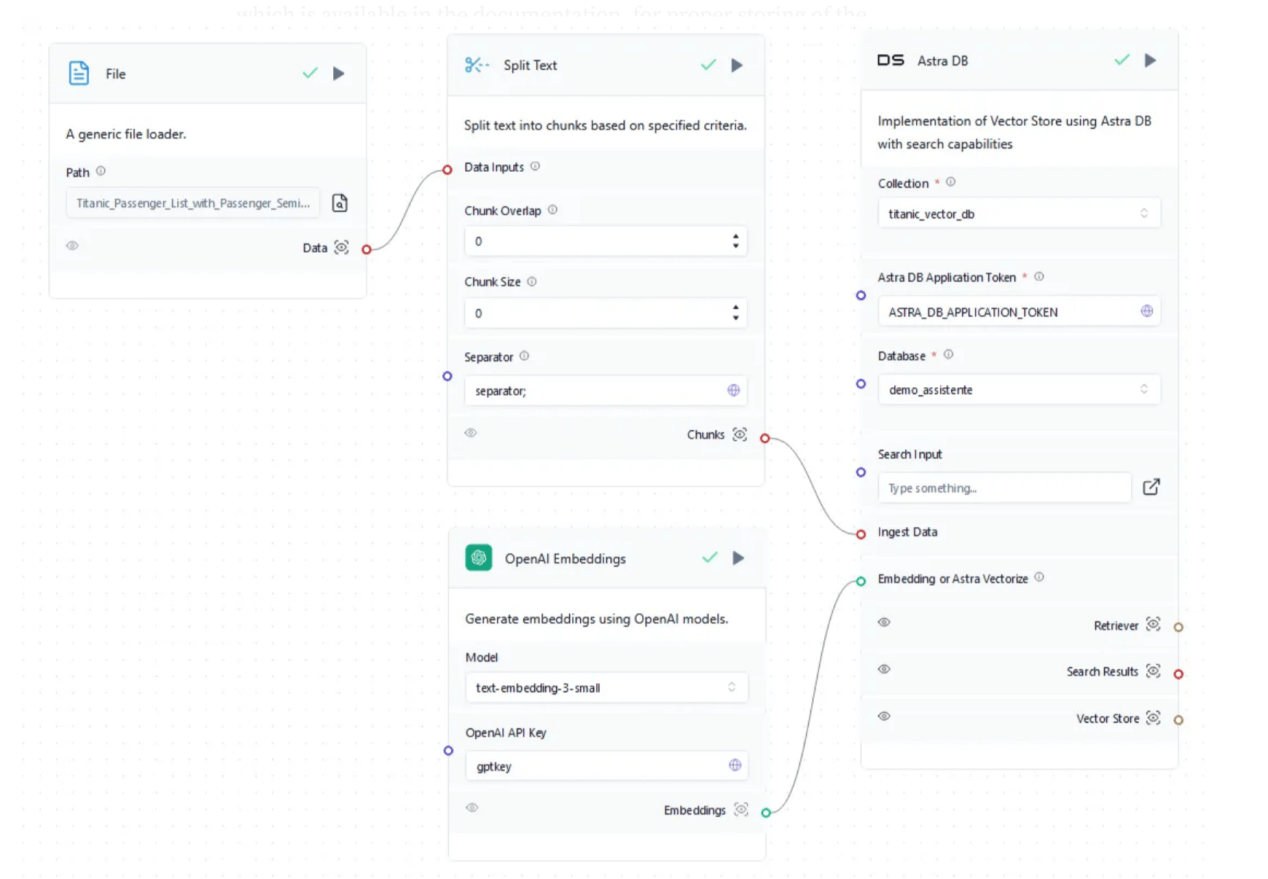
圖3:鐵達尼號數據集的檢索流程
用於增強聊天機器人上下文的數據集是Titanic數據集(https://www.kaggle.com/datasets/yasserh/titanic-dataset?resource=download,CC0許可證)。在RAG流程結束時,聊天機器人應該能夠提供具體的細節並回答有關乘客的複雜問題。但首先,我們需要在通用文件加載器對象上更新文件,然後使用全局變量「separator;」對其進行拆分,因為原始格式是CSV。此外,塊重疊和塊大小需要設置為0,因為通過使用分隔符,每個塊都將描述為一個乘客對應數據。如果輸入文件是純文本格式,那麼,有必要應用塊重疊和大小設置來正確創建嵌入。為了完成流程,向量存儲在demo_assistente資料庫的titanic_vector_db中。
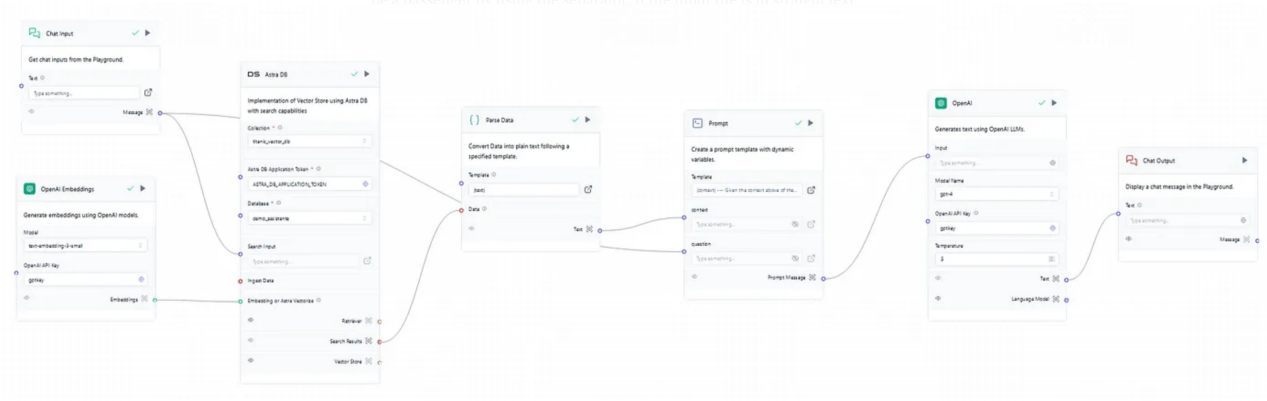
圖4:完整的生成流程
接下來,讓我們轉到RAG的生成流程,如圖4所示,它是由聊天中的用戶輸入觸發的,然後搜索到資料庫中,為以後的提示提供上下文。因此,如果用戶在輸入中詢問與名稱「Owen」相關的內容的話,搜索將在向量資料庫的集合中運行,尋找與「Owen「相關的向量,然後檢索並通過解析器運行它們以便將其轉換為文本,最後獲得稍後提示所需的上下文。圖5顯示了相應的搜索結果。

圖5:在向量資料庫中進行搜索以獲取上下文的結果
回到一開始,使用檢索流中的相同模型將嵌入模型再次連接到向量資料庫以運行有效搜索也是很關鍵的一步;否則的話,由於檢索和生成流中使用的嵌入模型的不同,會導致檢索結果內容總是空的。此外,這一步證明了在RAG中使用向量DB的巨大性能優勢,在RAG中將上下文快速檢索並傳遞給提示,然後才能對用戶做出任何類型的響應。
在圖6所示的提示中,上下文來自已轉換為文本的解析器,問題來自原始用戶輸入。下圖顯示了如何構建提示,並將上下文與問題結合起來。
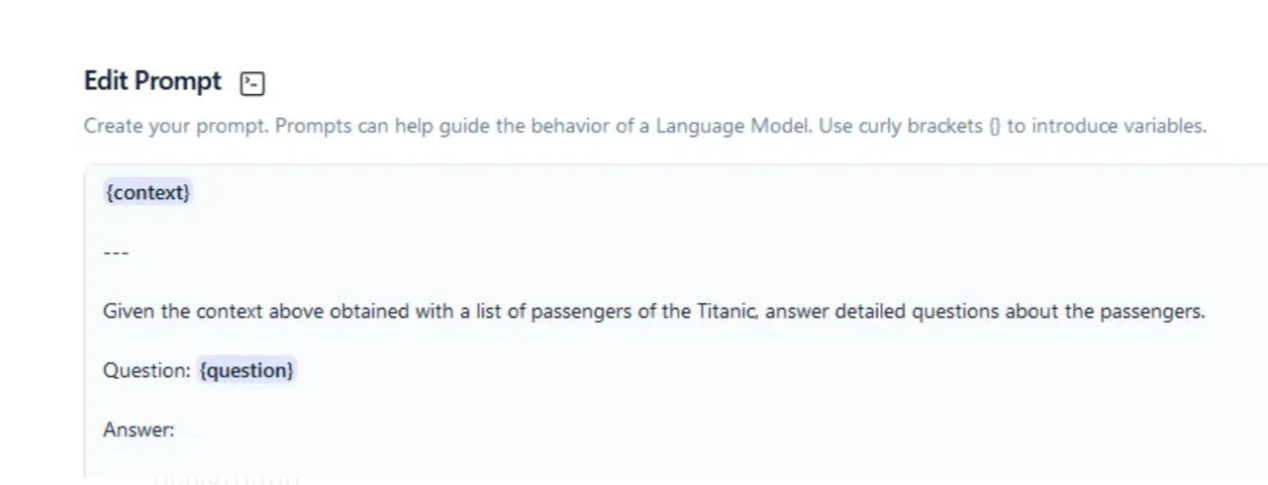
圖6:將傳遞給AI模型的提示信息
提示寫好後,是時候使用文本生成模型了。在此流程中,我們選擇使用GPT4模型,其溫度參數(temperature)設置為0.5,這是聊天機器人的標準推薦參數值。溫度參數將控制著LLM預測的隨機性。一個較低數值的溫度參數將產生更確定和直接的答案,從而產生更可預測的文本。相對來說,一個較高數值的溫度參數將產生更具創造性的輸出——儘管這個參數值太高時,模型很容易產生幻覺並產生不連貫的文本。最後,只需使用全局變量和OpenAI的API鍵設置API鍵,這一步就很容易了。接下來,是時候運行完整的流程並在Playground交互環境上檢查一下運行結果了。
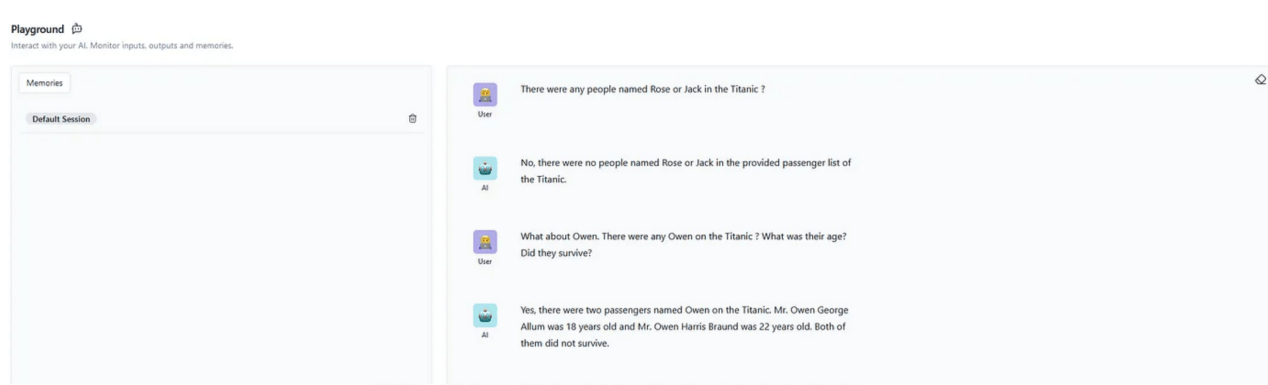
圖7:Playground交互環境顯示RAG聊天機器人的運行結果
圖7中的對話清楚地表明,聊天機器人能夠正確地獲取上下文,並正確地回答了有關乘客的詳細問題。儘管發現鐵達尼號上沒有羅斯或傑克可能會令人失望,但不幸的是,這是真的。現在,RAG聊天機器人已經創建結束;我們還可以繼續增強其功能以提高會話性能並覆蓋一些可能的「誤解」,但是本文主要展示Langflow框架如何輕鬆地適應和定製LLM。
小結
最後,我們來介紹一下流部署的問題。當前,存在多種可以供參考的部署方案。HuggingFace Spaces是一種部署RAG聊天機器人的簡單方法,它具有可擴展的硬體基礎設施和本地Langflow,不需要任何安裝。當然,Langflow也可以通過Kubernetes集群、Docker容器安裝和使用,也可以通過VM和Google Cloud Shell直接在GCP中安裝和使用。有關部署的更多信息,請參閱此框架有關文檔(https://docs.langflow.org/deployment-hugging-face-spaces)。
總之,新時代即將到來,低代碼解決方案開始為人工智慧在不久的將來在現實世界中的發展定下基調。本文介紹了Langflow如何通過直觀的UI和模板集中多種集成來徹底改變人工智慧。如今,任何具備人工智慧基礎知識的人都可以構建一個複雜的應用程式——這種程序的開發在本世紀初的話需要大量的編碼和深度學習框架專業知識。