
智東西
作者 | ZeR0
編輯 | 漠影
智東西5月15日報道,騰訊文生圖負責人蘆清林周二宣布騰訊混元文生圖大模型全面開源。
該模型已在Hugging Face平台及Github上發布,包含模型權重、推理代碼、模型算法等完整模型,與騰訊混元文生圖產品最新版本完全一致,基於騰訊海量應用場景訓練,可供企業與個人開發者免費商用。

這是業內首個中文原生的DiT架構文生圖開源模型,支持中英文雙語輸入及理解,參數量15億。
跟其他業界開源模型對比,混元DiT在多個維度上無短板,並在美學和清晰度維度上具有一定優勢。其綜合指標在所有開源和閉源算法中排名第三,實現開源版本中的SOTA。
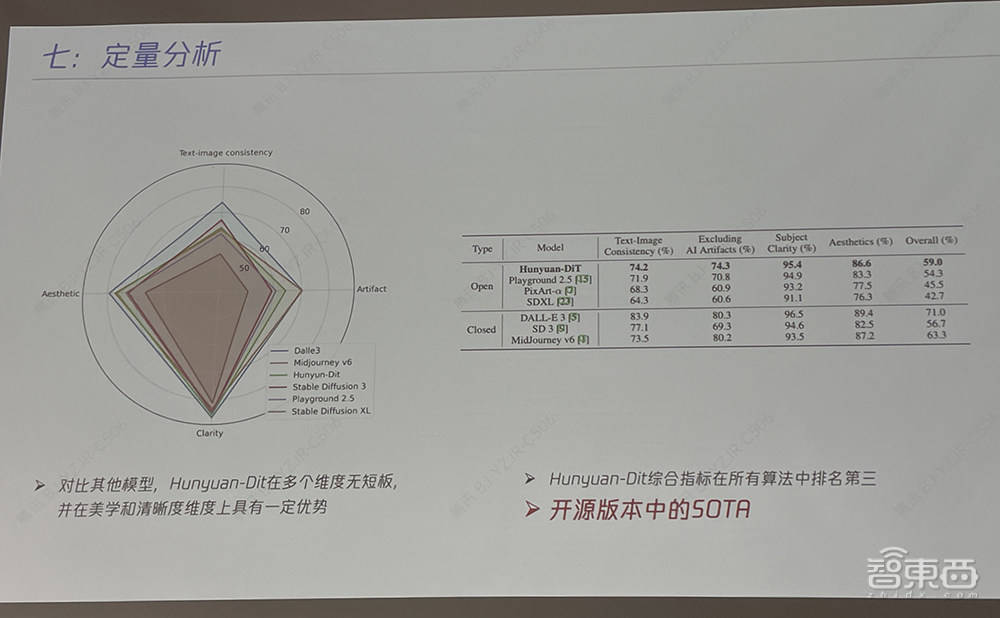
評測數據顯示,騰訊混元文生圖模型效果遠超開源的Stable Diffusion模型及其他開源文生圖模型,是目前效果最好的開源文生圖模型;整體能力屬於國際領先水平。

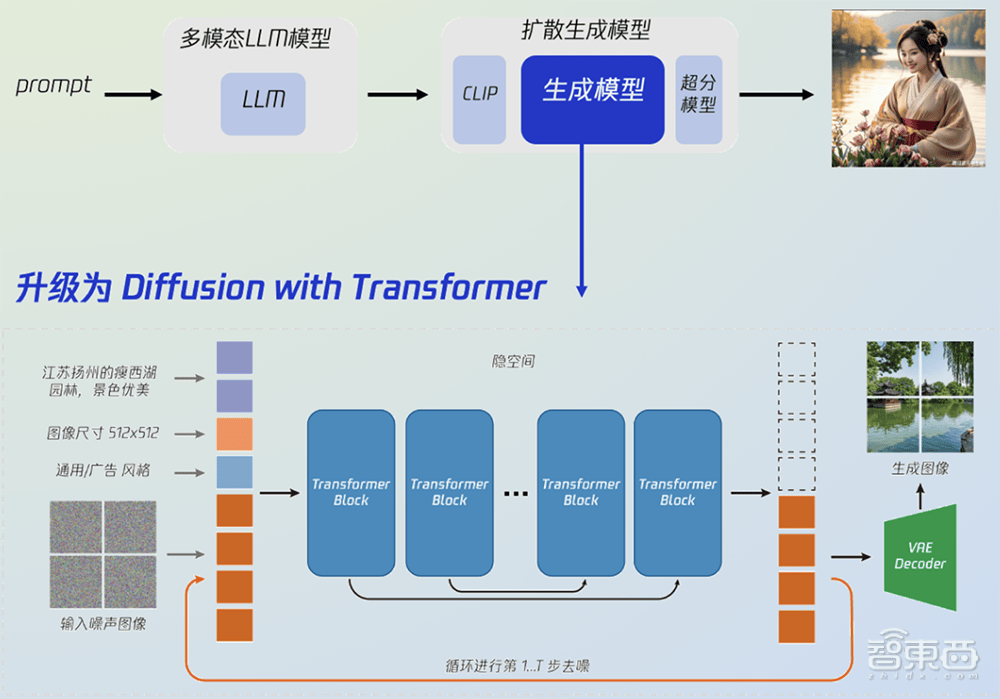
升級後的混元文生圖大模型採用了與Sora、Stable Diffusion 3一致的DiT架構,可支持文生圖,也可作為視頻等多模態視覺生成的基礎。
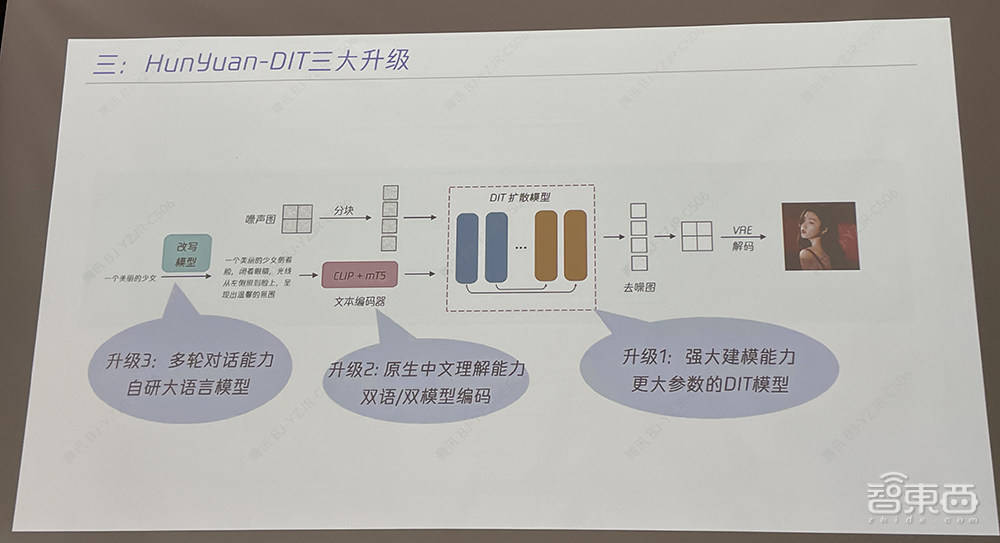
混元文生圖整體模型主要由3個部分組成:a)多模態大語言模型,支持用戶文本改寫以及多輪繪畫;b)雙語文本編碼器,構建中英文雙語CLIP理解文本,同時具備雙語生成能力;c)生成模型,從U-Net升級為DiT,採用隱空間模型,生成多解析度的圖像,確保圖像整體的穩定結構。
GitHub項目頁面建議使用具有32GB內存的GPU運行模型,以獲得更好的生成質量。
在蘆清林看來,此前開源與閉源文生圖模型的差距逐漸拉大,他希望騰訊混元文生圖大模型的開源後能夠將差距縮小。
騰訊混元已面向社會全面開放,企業級用戶或開發者可通過騰訊雲使用騰訊混元大模型,個人用戶可通過網頁端與小程序體現騰訊混元的能力。
一、更懂中文的開源文生圖大模型:基於DiT架構,多輪對話能力增強
過去,視覺生成擴散模型主要基於U-Net架構,但隨著參數量提升,基於Transformer架構的擴散模型(DiT)展現出了更好的擴展性。
U-Net只懂圖片,遇到難題易卡殼,而Transfomer能懂不同模態信息,參數/數據量越多越厲害。DiT是結合擴散模型和Transformer架構的創新技術,有高擴展和低損失的優勢,更易擴展,有助於提升模型的生成質量及效率。
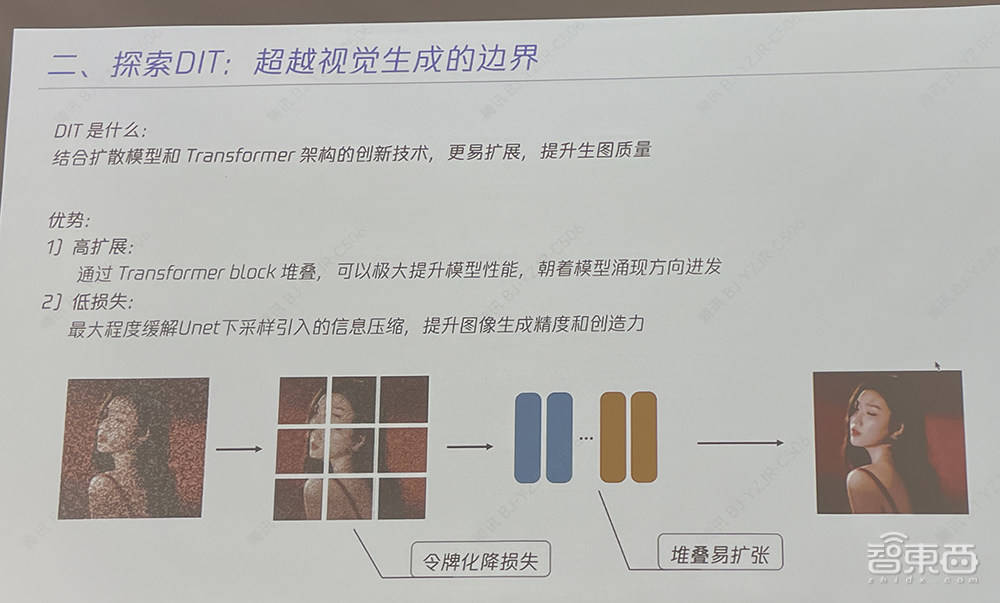
該架構通過Transformer block堆疊,可極大提升模型性能,並最大程度緩解U-Net下採樣引入的信息壓縮,提升圖像生成精度和創造力。
據騰訊文生圖負責人蘆清林分享,在原始DiT架構之上,混元DiT有三大升級:
一是強大建模能力,將文生圖架構從自研U-Net架構升級為更大參數的DiT模型,提升圖像質量和擴展能力,讓DiT架構具備了長文本理解能力,支持最長256個字符的圖片生成指令;同時利用多模態大語言模型,對簡單/抽象的用戶指令文本進行強化,轉寫成更豐富/具象的畫面文本描述,最終提升文生圖的生成效果。
二是增加中文原生的理解能力,自主訓練中文原生文本編碼器,讓中文語義理解能力更強,對中文新概念學習速度更快,對中文認知更深刻,同時讓模型更細緻地分辨不同粒度文本信息。
三是增強多輪對話能力,與自研大語言模型結合,讓模型具備上下文連貫的理解能力,同時通過技術手段控制同一話題與主體下圖片主體的一致性。
1、升級一:核心運算元升級,從UNet升級到DiT
學術界去年提出基礎DiT架構,混元DiT在此之上進一步升級,有更強語義編碼,針對更長、更複雜的文本能理解得更準確,原生中英雙語支持,尺寸更易擴展。

混元DiT架構具備更穩定的訓練過程,通過優化模型結構,支持數十億參數和1024解析度的模型穩定訓練。它還擁有更好的生態兼容性,可靈活支持ControlNet、LoRA、IP-Adapter、Photomaker等Stable Diffusion社區的插件。
同時,該架構支持輸出多解析度圖像,提升不同解析度生成圖像的質量,包括1:1、4:3、2:4、16:9、9:16等多種解析度,支持768~1280解析度圖像生成。
2、升級二:語言編碼器升級-支持原生中文理解能力
混元文生圖是首個中文原生的DiT模型,具備中英文雙語理解及生成能力,在古詩詞、俚語、傳統建築、中華美食等中國元素生成上表現出色。
通過語言編碼器升級,混元DiT架構對中文的認知更加深刻,相比核心數據集以英文為主的Stable Diffusion等主流開源模型,能更好理解中國的語言、美食、文化、習俗、地標等。
比如在生成崑曲藝術家表演的圖像時,混元文生圖在理解崑曲藝術方面明顯比其他國外主流文生圖模型更準確。

升級的混元文生圖能更細緻地分辨不同信息。其訓練方式是把數據做成正負樣本,對比學習損失,讓模型學會什麼是對、什麼是錯,做到理解和表達更細緻的屬性。
比如輸入一段涉及大量細節描述的文字,混元文生圖能夠精細理解文字要求,生成符合各種細節的圖像。

3、升級點3:多輪繪圖和對話能力增強
混元文生圖在算法層面創新實現了多輪生圖和對話能力,可在一張初始生成圖片的基礎上通過自然語言描述進行調整,達到更滿意的效果。
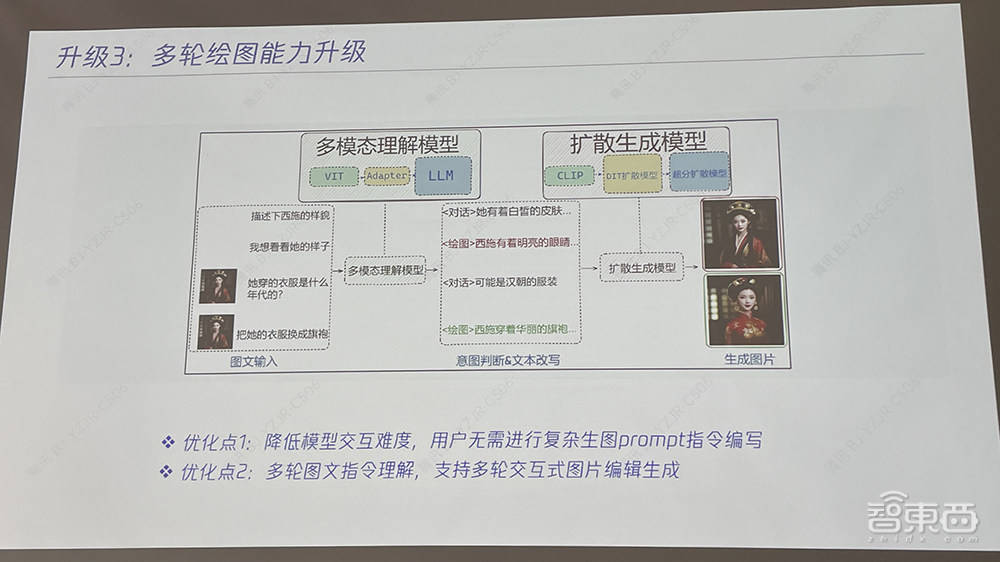
比如起初輸入指令「生成一朵長在森林中的白色玫瑰」,再要求「改成百合花」、「改成粉色」、「改成動漫風格」;起初輸入指令「畫一隻色彩斑斕的摺紙小狐狸摺紙」,再要求「把背景換成沙漠」、「把狐狸換成小狗」。

模型交互難度進一步降低,用戶無需進行複雜生圖提示詞指令編寫。混元文生圖能實現多輪圖文指令理解,支持多輪交互式圖片編輯生成,支持十輪以上的對話。

二、去年7月投入DiT研發,從零開始訓練,全鏈路自研
騰訊混元團隊認為基於Transformer架構的擴散模型(如DiT)具有更大的可擴展性,很可能成為文生圖、生視頻、生3D等多模態視覺生成的統一架構。
2023年7月起,業界研究DiT的團隊還不多,當時混元文生圖就明確了基於DiT架構的模型方向,並啟動了長達半年的研發、優化、打磨。今年年初,混元文生圖大模型已全面升級為DiT架構,並在多個評測維度超越了基於U-Net的文生圖模型。
數據顯示,在通用場景下,基於DiT視覺生成模型的文生圖效果,相比前代視覺生成整體效果提升20%,畫面真實感、質感與細節、空間構圖等全面提升,並在細粒度、多輪對話等場景下效果提升明顯。
這裡面存在極大難點:首先,Transformer架構本身並不具備用戶語言生圖能力;其次,DiT本身對算力和數據量要求極高,文生圖領域缺乏高質量的圖片描述與圖像樣本訓練數據。
騰訊混元團隊在算法層面優化了模型的長文本理解能力,能夠支持最多256個字符的內容輸入(業界主流是77個),從零開始訓練,做到全鏈路自研,在模型算法、訓練數據集與工程加速多個層面進行了系統化的創新研發。
針對文生圖訓練數據缺乏、普遍質量不高的問題,騰訊混元團隊通過優化圖片描述能力、樣本評估機制等提升文生圖訓練數據的規模和質量,同時利用多模態大語言模型強化與豐富用戶指令文本,從而提升最終文生圖效果。
混元文生圖大模型基於騰訊自研的Angel機器學習平台進行訓練,大幅提升了訓練效率。為了更好地提升模型訓練與運行效率,提升算力資源利用率,團隊為該模型構建專屬工程加速工具庫。
三、開源領域自主可控,填補中文原生DiT文生圖架構空白
為什麼選擇在這個節點開源?在媒體交流環節,蘆清林談到這主要出於兩點考慮,一是在業界投入DiT研發的時間早,經歷長時間的打磨,成熟度達到開源條件;二是看到業界需要開源中文原生DiT文生圖模型。
過去業界文生圖大多基於Stable Diffusion,開源社區有數量龐大的開發者和創作者,基於Stable Diffusion精調出了豐富的垂直場景模型,同時衍生出大量國內外模型分享與流通社區。
主要的文生圖開源社區依然主要基於U-Net架構模型進行開發,仍未有比較先進的DiT架構充分開源。而無論Stable Diffusion 3還是Sora都採用DiT架構來構建下一代圖像/視頻生成能力。開源社區缺乏先進/成熟的DiT架構開源利用,業界也難以快速吸收學術界大模型前沿技術。
中文原生的DiT文生圖架構同樣是缺失的。在中文場景,很多團隊基於翻譯+英文開源Stable Diffusion模型,導致在中文特有的場景、人物、事物上表現比較差。
還有一些團隊基於少量的中文數據在一些特殊的場景做了微調,讓模型去適配某個特殊的領域或者風格。但直接用英文預訓練的模型+中文小數據微調也存在對中文理解不足和不通用的問題。
即使國外有些論文公開,這些架構更多偏英文,對中文理解差,而且沒在大眾中做驗證,在中文應用場景受限。由中文翻譯成英文可能會導致出圖有歧義,比如中文「一隻很熱的狗在餐廳」翻譯成英文「A very hot dog in the restaurant」就變味了,會生成「一盤熱狗(hot dog)」圖。

而開源DiT研發成果,意味著全球個人和企業開發者都能直接都能直接用上了最先進的架構,不用自己重新研發和訓練,大大降低了AI使用門檻,也節省了人力物力。
基於騰訊此次開源的文生圖模型,開發者及企業無需重頭訓練,即可直接用於推理,並可基於混元文生圖打造專屬的AI繪畫應用及服務,能夠節約大量人力及算力。透明公開的算法也讓模型的安全性和可靠性得到保障。
基於開放的混元文生圖基礎模型,還有利於在以Stable Diffusion等為主的英文開源社區之外豐富以中文為主的文生圖開源生態,形成更多樣的原生插件,推動中文文生圖技術研發和應用。
騰訊已開源超170個優質項目,均來源於騰訊真實業務場景,覆蓋微信、騰訊雲、騰訊遊戲、騰訊AI、騰訊安全等核心業務板塊,目前在Github上已累計獲得超47萬開發者關注及點贊。
結語:全面開源,惠及行業,已在探索更大參數量的模型
此前的開源生態、數據集均以英文為主,建設中文原生的文生圖開源模型、中文的文生圖開源生態,是十分必要的。
此次把最新一代模型完整開源出來,騰訊混元團隊希望與行業共享在文生圖領域的實踐經驗和研究成果,豐富中文文生圖開源生態,共建下一代視覺生成開源生態,推動大模型行業加速發展。
蘆清林分享說,混元文生圖的後續優化方向包括提升技術能力和在更廣泛的場景中應用。
騰訊混元文生圖能力已廣泛被用於素材創作、商品合成、遊戲出圖等多項業務及場景中。今年初,騰訊廣告基於騰訊混元大模型發布了一站式AI廣告創意平台騰訊廣告妙思。《央視新聞》《新華日報》等20餘家媒體也已經將騰訊混元文生圖用於新聞內容生產。
據蘆清林透露,目前混元文生圖大模型的參數規模是15億,同時團隊已經在探索參數量更大的模型。他坦言模型在寫中文文字的效果上還沒做到非常成熟,等做好後也會拿出來分享。