採訪嘉賓 | 周昕毅
編輯 | 李忠良
在當今複雜的技術環境中,隨著軟體架構從單體向微服務和雲原生的演進,企業對於可觀測性的需求變得前所未有的重要。作為全球領先的在線旅遊服務平台,攜程面對的是海量監控數據與日誌處理的挑戰,這對平台的高效治理和持續穩定提出了更高的要求。
在即將到來的 QCon 上海站,攜程雲原生研發總監 周昕毅將為我們帶來《 AI 驅動下的可觀測平台架構升級實踐》的主題演講。在會前的採訪中,周昕毅分享了攜程在應對這些挑戰時所採用的創新解決方案,尤其是在數據採樣、分層存儲和統一監控 Agent 等技術手段的應用方面。他深入探討了如何在保證系統性能與成本效益的平衡下,實現對海量數據的有效治理。此外,周昕毅還分享了攜程在 AIOps 領域的領先實踐,深入剖析雲原生架構帶來的可觀測性難題,為行業提供了寶貴的技術見解。
另外,在本屆 QCon 上海站,我們也設置了大模型基礎設施與算力優化、AI 應用開發實踐、AI 重塑技術工作流程以及雲原生工程實踐等專題論壇,欲了解更多精彩內容,可點擊原文連結查看。
行業變革與現狀洞察
InfoQ:攜程的可觀測性平台現狀中,您認為最突出的問題是什麼?這些問題具體是如何影響平台的運維和決策的?
周昕毅:隨著攜程軟體系統和應用的複雜性持續增加,攜程可觀測平台的數據量也在急劇增長。
攜程當下有超過 1w 個應用,實例數量 (包括物理機、虛擬機、容器) 超過 100 萬個,它們產生的 Metrics 數據量每分鐘超過 10 億,所有應用和系統產生的日誌量日增長超過 1PB。可觀測數據包括日誌、指標、追蹤信息等,如何有效地收集、存儲、處理和分析這些數據成為一個巨大的挑戰,也是目前攜程可觀測平台最突出的問題。
這些問題對平台的運維和決策有以下影響:
InfoQ:隨著系統越來越複雜,攜程的監控和日誌數據是如何快速增長的?在管理這些數據方面,您遇到了哪些技術或管理上的挑戰?
周昕毅:監控和日誌數據增長的原因分析如下:
管理監控和日誌增長過程中,主要有如下的挑戰:
1)時間序列資料庫的基數膨脹問題
2) 1-5-10 目標需要實現秒級告警
3)業務的複雜性持續增加,對於可觀測性工具的依賴度越來越高
4)數據量持續增加後,可觀測工具自身也存在穩定性和實時性挑戰
5)高並發寫入場景下的實時查詢技術挑戰
InfoQ:在處理這些不斷增加的監控指標和日誌數據時,攜程如何平衡系統性能和資源消耗的矛盾?
周昕毅:監控指標持續增加時,最常用的降本增效技術手段:數據採樣和聚合;通過採樣可以顯著減少數據量,不同 metric 類型採用不同的採樣策略,常用的採樣策略是聚合某一個時間段內的平均值、最大值、最小值,可以大幅降低存儲和查詢的負擔。
日誌數據有效的技術手段是建立冷熱數據分層存儲、定期歸檔的機制,將頻繁訪問的數據存儲在快速存儲介質上,而將不常訪問的數據存儲在較慢但更便宜的存儲介質上。
光靠技術手段還不夠,需要建立定期 review 的機制,對於 top size 的監控指標和日誌數據進行查詢治理和存儲治理,治理過程中將基本原則落地為巡檢工具,持續巡檢避免後續可能發生的資源浪費。
可觀測性平台作為「運維之眼」,對於網站可用性保障具備非常重要的戰略意義,在可觀測性平台進行資源投入是合理的,但需要確保有限的資源使用在優先級更高的業務場景之上,目前需要通過技術手段區分指標數據和日誌數據的優先級,在容量達到瓶頸時有效啟動降級、限流、降採樣、冷存儲遷移等預案。
InfoQ:對於非關鍵性指標占用資源的問題,是否有採取措施來進行篩選和優化?如何判斷哪些指標是核心的、必須實時處理的?
對於可觀測性平台中的核心組件容量,進行容量規劃和定期壓測,包括 TSDB 的寫入並發數、TSDB 單位時間內的新增 ts 數、TSDB 的查詢並發數、TSDB 存儲容量、消息隊列並發數等,對於當前平台總體的 Metric 數量還有多少增長空間有準確的評估,避免出現核心指標持續增長時平台容量不足。
行業內普遍存在監控工具分散、數據孤立的情況。攜程是否也遇到了類似問題?如果有,您認為如何統一治理這些工具和數據更為有效?
沒有一款監控工具能夠解決所有監控需求,這也造成了工具分散和數據孤島。
產品層面:攜程的處理思路是在將 Metric、Logging、Trace 三大支柱融合在同一個產品中, 消除了多個監控領域的重複建設,統一多個工具的入口,縮短用戶的排障工具使用路徑,實現 Metric、Log、Trace 各類可觀測性數據的聯動。
底層技術:Metric 和 Logging 數據實現統一查詢、統一存儲、統一治理。不同業務可以基於底層框架進行擴展,但是查詢層和存儲層需要收口在統一產品中,便於統一治理和資源利用率提升。
InfoQ:從整個行業來看,雲原生架構引發的可觀測性挑戰是否與攜程的現狀一致?您如何看待這個領域的普遍痛點?
周昕毅:雲原生架構的引入帶來了許多優勢,典型的如彈性、可擴展性和更快的部署速度,將交付效率提升到了歷史高度,對於可觀測性基礎設施也提出了很高的要求,在行業內很多公司都在追求效率的同時遇到了可觀測性挑戰,大家的問題是一樣的。我認為這個痛點是暫時的,隨著可觀測性技術體系的持續發展,下列問題都是可以分而治之。
具體問題包括如下:
- 被觀測對象的生命周期短:容器的生命周期通常較短,可能會頻繁啟動和銷毀。這種動態性使得傳統的監控工具難以跟蹤和記錄系統的狀態,存儲到 TSDB 之後、容器 containerid、ip 等頻繁變化的維度觸發了 TSDB 的基數膨脹。
- 不同視角的監控需求:雲原生架構涉及多個層次,包括基礎設施層(如虛擬機、容器)、平台層(如 Kubernetes、OpenStack)、應用層(微服務)和網絡層。每一層都需要不同的監控和日誌記錄方法,且需要避免循環依賴,基礎設施層的監控需要和應用層的監控工具區分管理。
- 海量數據的實時處理:由於雲原生系統的分布式和動態特性,生成的日誌、指標和追蹤數據量巨大。有效地收集、存儲和分析這些數據需要強大的數據處理能力和智能化的分析工具。
AI 驅動的創新實踐:
技術與策略的升級
InfoQ:攜程是如何通過統一監控 Agent 來提升可觀測性數據治理的?這個過程中遇到了哪些困難,具體是如何解決的?
周昕毅:攜程應用和服務主要通過框架 SDK 埋點的方式記錄 Metric、Logging、Tracing 數據,除應用之外,作業系統、硬體、安全、網絡設備等的監控 Metric、日誌 Logging 數據均是通過攜程自研的 Hickwall Agent 進行統一採集上報到存儲系統和消息隊列進行後續的統一處理。
統一監控 Agent 採集的主要對象包括:系統級監控指標:CPU、內存、磁碟、網絡 IO;內核級監控指標:ebpf 採集指標、內核異常 metric;系統日誌:syslog,messages,kernel-log;安全日誌:ssh 登錄日誌,audit 日誌,進程啟動日誌等。
攜程統一監控 Agent 對於可觀測性數據治理有很多幫助,主要包括如下:
1)格式和命名規範統一:
統一格式:使用統一的監控 Agent 可以確保所有採集的數據採用一致的格式和標準,便於後續的存儲、處理和分析。
統一命名規範:統一的命名規範可以減少數據混淆,確保不同來源的數據可以正確關聯和對比。
2)集中管理和控制:
集中配置:通過統一的 Agent,可以集中管理和配置監控策略,減少了分散管理帶來的複雜性和錯誤風險。
統一策略:可以應用統一的數據採集、存儲和處理策略,確保所有數據治理措施的一致性和有效性。
3)安全性和合規性:
統一安全策略:可以實施統一的安全策略,如數據加密、訪問控制和審計日誌,確保數據的安全性和合規性。
監控 Agent 在安全審計中是一個重要的環節,可以確保安全策略的收口,自動化巡檢,策略覆蓋度的提升落地。
攜程在建設統一 Agent 過程中遇到的困難主要包括:
1)需要支持多平台: 攜程內部所有使用的 OS 都需要適配對應的 Agent 支持;
2)Agent 升級困難:Agent 版本升級需要多個運維支持團隊配合,全網升級一輪耗時很長,缺乏統一管控。後續攜程引入了 Agnet 自升級機制,通過一個 Guardian 客戶端對於監控日誌 Agent 進行健康監控和版本升級統一控制。
3)需要引入防呆機制:Agent 全網機器都有部署,需要對於一些極端異常情況進行防呆設計。監控 agent 應能夠自動發現系統中的資源和服務,並自動配置監控參數,減少人為配置錯誤。當監控 agent 檢測到自身配置或運行狀態異常時,應具備自我修復能力,如重新加載配置或重啟自身。
4) Agent 健壯性:監控 agent 應能夠優雅地處理各種錯誤情況,如網絡中斷、數據收集失敗等,並記錄詳細的錯誤日誌以便排查。agent 需要設置合理的資源使用限制(如 CPU、內存)以防止監控 agent 自身消耗過多資源影響被監控系統的性能。
5)性能持續優化:優化數據收集和傳輸機制,確保監控 agent 高效運行,不對被監控系統造成過多負擔。支持批量處理和壓縮傳輸監控數據,減少網絡帶寬消耗和系統負載。
InfoQ 在 Metrics 和 Logging 數據治理方面,攜程採取了哪些創新性措施?這些措施如何幫助優化數據質量和系統性能?
周昕毅:首先是 Logging 治理實踐:
1) 從分散到統一
日誌數據統一存儲、統一查詢,目前使用的是 Clickhouse 作為攜程日誌平台的存儲層;對於 Clickhouse 的查詢請求收口到統一查詢 API。
日誌統一查詢層架構示例:
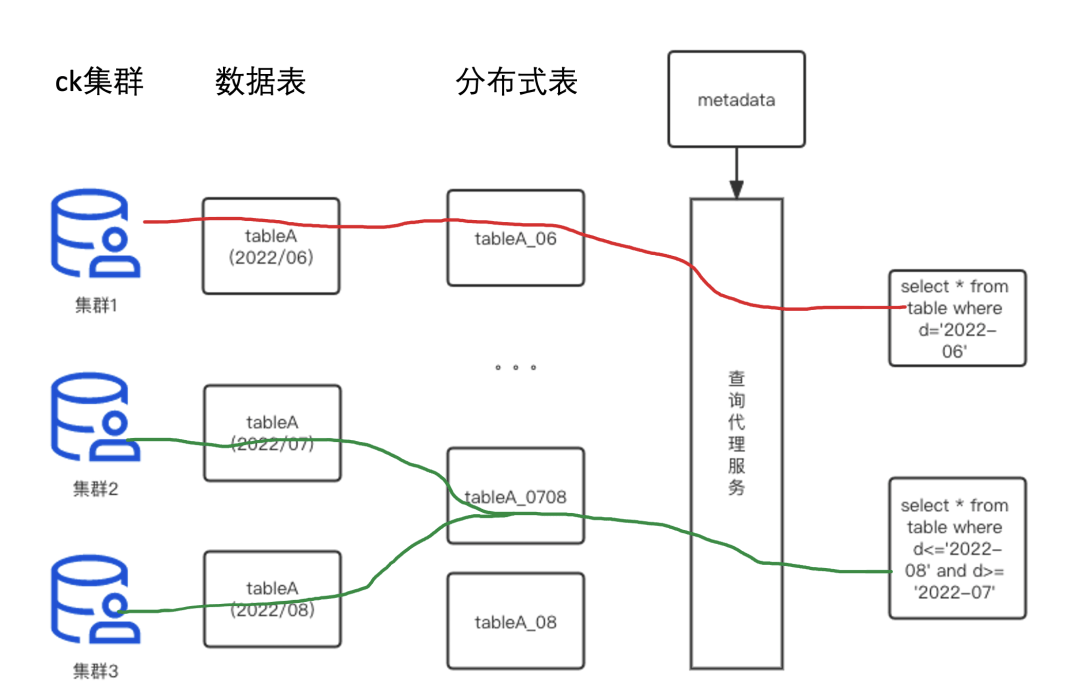
2)日誌查詢治理
基於日誌統一查詢 API 的能力,可以實施日誌查詢治理,包括用戶 SQL 的智能化改寫兼容不同版本的 Clickhouse;限制查詢 QPS,確保後端 Clickhouse 性能和響應時間在可控範圍內;限制最長查詢時間範圍,比如超過 180 天的查詢請求直接返回錯誤、避免長時間占用資源;
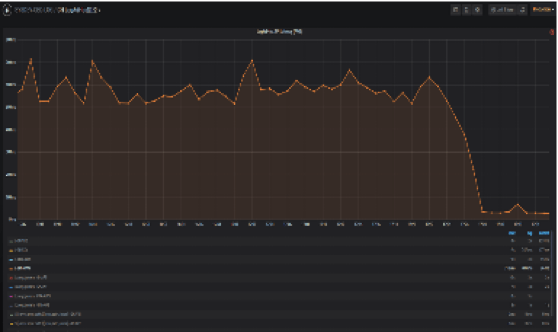
目前統一查詢層每日平均攔截 1500 次用戶不合理的查詢請求,如下圖所示,開啟自動攔截之後、集群有效 QPS 顯著下降。
3)設置 Logging 最佳實踐,在公司中推廣
最佳實踐包括: 遵循日誌統一規範;設置合理的日誌保留天數;設置合理的單位時間內發送條目數;超過閾值是有合適的採樣策略。
4)日誌存儲治理
Clickhouse 集群選擇本地磁碟 + 分布式存儲擴展的模式,落地冷熱分離技術方案,設置表級別的 Quota 和租戶級別的 Quota 值,推動租戶自助進行日誌治理。Clickhouse 選擇使用 zstd 壓縮模式,降低磁碟空間使用率;統一使用批量插入的模式、一次寫入多條日誌,降低集群 IO 壓力;
其次是 Metrics 數據治理實踐:
1)Metrics 監控工具功能升級
工具本身提供指標聚合能力,並引導用戶進行指標聚合的配置;原始數據進行針對性降維,收斂指標維度的數量;推進 Metric Federation 建設,提供指標數據聯邦查詢的能力
2)時間序列資料庫容量規劃
完善 Metrics 存儲和寫入集群自身的監控,關注 ts 數量的增長,對於 Metrics 數據尖峰流量有應對預案
3)Metric 指標智能化治理
4)提升 Metric 過濾能力
在 Logging 數據和 Metrics 數據治理過程中,有一個相同的關注點,「不要期望僅靠 logging 數據、不要期望僅靠 Metrcis 數據來解決所用問題」,Logging、Metrics、Tracing 三大支柱是互相補充、彼此備份的,需要在治理過程中從解決實際需求的角度出發、選擇最優的監控方案。
就可觀測數據治理後的主要收益來說,首先是數據準確性和完整性:減少錯誤和異常數據,提高監控數據的準確性和完整性,「誤報」是監控工具最大的敵人,通過數據治理可以降低誤報,利用有限的資源將監控價值最大化;其次是查詢和分析效率提升:減少無效查詢,優化數據存儲和處理流程;最後是系統穩定性和性能提升:減少數據採集和處理對系統性能的影響,提高系統的穩定性和性能。
InfoQ:物化視圖和分層存儲技術在攜程的可觀測平台中具體是如何應用的?這些技術如何有效地提升數據處理的時效性和可靠性?
周昕毅:ClickHouse 的物化視圖(Materialized Views)技術在攜程可觀測平台中的使用:
日誌預聚合: 常用的日誌聚合是按照每小時的請求數、錯誤數、平均響應時間,也可以按特定維度(如用戶、地理位置、服務類型等)進行分組聚合,生成預先計算的統計數據
主要收益一方面是可以加速查詢:通過預聚合減少查詢時的計算量,減少實時查詢時的 CPU 和 I/O 資源消耗從而顯著提高查詢性能,提高系統的整體響應速度;另外一方面是支持更長的查詢範圍:寫入量較高的日誌表,一般只能支持天級別、小時級別的查詢,通過物化視圖技術,可以為重要的日誌表增加更長的保留天數。
攜程在該技術落地過程中,整理了如下的注意事項:
1)性價比考量:物化視圖會占用額外的存儲空間,需要根據實際需求權衡存儲成本和查詢性能,優先處理高 QPS 查詢的表,不能用於全部的日誌表。
2)准實時更新:物化視圖的更新是異步的,需根據業務需求調整更新策略。
3)數據準確性比對:需要定期維護和管理物化視圖,保障其數據準確性。
分層存儲技術的概念是指將數據分為多個層次,每個層次使用不同的存儲介質和策略。例如,在熱數據層,存儲最近和頻繁訪問的數據,通常使用高性能的存儲介質(如本地 SSD 磁碟);在冷數據層,存儲較少訪問的歷史數據,通常使用成本較低的存儲介質(如本地 HDD 磁碟);在歸檔層:存儲很少訪問但需要長期保存的數據,可能使用更低成本的存儲介質(比如磁帶)或雲存儲。
Clickhouse 日誌表天然適用於基於 timestamp 做冷熱存儲分離的邏輯,如下列建表語句所示:
超過一個月的日誌由於業務需求不能刪除,但可以定期遷移到冷數據存儲層做歸檔。
分層存儲技術落地的收益主要在於降低日誌存儲單價,延長日誌存儲時間,極大增加了可觀測平台中日誌存儲的可擴展性。
InfoQ:可觀測性數據質量是 AIOps 成功的關鍵,攜程如何通過度量工具來保證數據的準確性?在提升數據質量的過程中,有哪些具體的實踐經驗可以分享?
周昕毅:高質量的可觀測性數據(包括 Metrics、Logging、Tracing 數據)是 AIOps 成功的關鍵因素之一。攜程通過如下方式來保證數據的準確性:
1)數據採集準確性度量
- Agent 覆蓋率和存活率統計
- 多個數據源交叉驗證監控,從系統維度和應用維度的 metrics 數據做交叉校驗
- 基於歷史數據寫入量的預測和智能告警
- Agent 覆蓋率和存活率統計
- 多個數據源交叉驗證監控,從系統維度和應用維度的 metrics 數據做交叉校驗
- 基於歷史數據寫入量的預測和智能告警
2)數據傳輸準確性度量
- 應用 SDK 埋點發送量監控
- Kafka 消費量監控
- 應用 SDK 埋點發送量監控
- Kafka 消費量監控
3) 數據存儲準確性度量
- 年、月、日 維度聚合數據量監控
- 機房、地域、集群等多維度聚合監控
- 年、月、日 維度聚合數據量監控
- 機房、地域、集群等多維度聚合監控
為了提升可觀測性數據質量,主要要如下幾個方面出發:
1)提升數據實時性
- 提升數據收集端的實時性,持續優化統一監控 Agent 性能
- 減少數據傳輸鏈路,部分場景採用 writer 直寫 TSDB 的模式
- 核心傳輸鏈路依賴的 Kafka 性能保障
- 存儲引擎持續優化,根據場景選擇合適的存儲引擎 (如 TSDB 選擇 VictoriaMetrics, 日誌場景使用 Clickhouse)
- 提升數據收集端的實時性,持續優化統一監控 Agent 性能
- 減少數據傳輸鏈路,部分場景採用 writer 直寫 TSDB 的模式
- 核心傳輸鏈路依賴的 Kafka 性能保障
- 存儲引擎持續優化,根據場景選擇合適的存儲引擎 (如 TSDB 選擇 VictoriaMetrics, 日誌場景使用 Clickhouse)
2)提升數據完整性
- 推進數據治理,制定和實施數據治理策略,確保存量數據的高質量
- 建設採集層、傳輸層、存儲層的度量工具,確保數據的完整性
- 推進數據治理,制定和實施數據治理策略,確保存量數據的高質量
- 建設採集層、傳輸層、存儲層的度量工具,確保數據的完整性
3) 建設統一查詢層
- Metric 數據統一查詢,建設 Metric Federation 聯邦查詢層
- Logging 數據統一查詢,推動日誌查詢治理,確保可觀測性資源消耗在核心監控鏈路
- Metric 數據統一查詢,建設 Metric Federation 聯邦查詢層
- Logging 數據統一查詢,推動日誌查詢治理,確保可觀測性資源消耗在核心監控鏈路
InfoQ:對於其他企業在進行可觀測平台架構升級時,您會建議他們優先從哪些方面著手改進?有無哪些具體的技術路徑可以參考?
周昕毅:建議簡化技術棧,同質化工具儘量合併,Logging、Metric、Tracing 不同場景明確分類不要混用;監控和日誌進行中優先級劃分,優先保障高優先級日誌和監控數據的完整性和實時性。具體技術路徑可以從可觀測平台的各個不同組件的定位和技術架構角度出發,供大家參考:
- 數據採集層:使用統一的監控 Agent 用於系統層 Metric 和日誌收集;使用統一的 SDK 用於應用埋點。
- 數據存儲層:選擇合適的 TSDB 存儲引擎和日誌存儲資料庫,可以有多套存儲應對不同的業務場景,但是需要統一寫入、統一查詢、統一治理。
- 數據分析和可視化:使用統一的用戶側產品,將 Logging、Metric、Tracing 數據進行統一展示、實現數據聯動,構建直觀的可視化儀錶盤,展示關鍵指標和日誌信息,並持續運營維護。
- 自動化運維和智能化運維:實現監控和告警的自動化處理,減少人為干預和操作失誤,同時進行 AIOPS 技術落地與探索,使用機器學習等 AI 技術,自動檢測異常和預測系統問題。在持續優化可觀測性數據質量的前提下,AIOPS 落地將會更加便捷,收益更高。
可觀測性與智能化運營的演進方向
InfoQ:您認為未來 AIOps 在運維中的發展趨勢是什麼?智能化的運維工具將如何改變傳統 SRE 團隊的工作模式?
周昕毅:隨著 AI 技術的不斷進步和企業對高效運維需求的增加,AIOps 的發展趨勢會從幾個方面持續推進:
- 自動化運維
AIOps 持續發展的能力包括故障檢測、根因分析到自動修復,會不斷減少人為干預和操作失誤。AIOps 會和現有的自動化運維工具和平台融合,運維工具變得更加智能化。
- 異常檢測
AIOps 利用機器學習和深度學習技術,自動檢測系統中的異常行為和性能瓶頸,及時發現和定位問題。預測性防護能力提升,AIOps 通過分析歷史數據和實時數據,預測系統可能出現的問題和故障,提前採取預防措施。
- 容量預測
AIOps 目前已經廣泛用於容量預測的場景,未來可能發揮更大的作用,用於全棧容量預測,不局限於應用和業務場景,也包括基礎設施的容量管理。
- 可觀測性數據整合
AIOps 可以整合來自不同數據源的數據(如日誌、指標、追蹤數據),進行綜合分析和關聯性分析,提供更深入的洞察。
- 協作和知識共享
通過 AIOps 平台,實現運維團隊之間的高效協作和知識共享,提高問題解決的效率。同時,運維知識圖譜也將持續疊代更新。
傳統 SRE 團隊的工作內容包括業務系統的監控配置和告警處理、業務故障排除和根因分析、系統性能優化和容量規劃、自動化運維和配置管理、業務系統災備和高可用性建設等,基於上述展望,AIOps 將成為 SRE 工程師的左膀右臂,在各個領域都能提升工程師的工作效率,成為穩定性工程建設的重要助力。正是基於上述展望,可觀測性平台的架構持續升級應對更多的數據增長需求和挑戰顯得很有必要性,一旦出現數據問題導致 AI 誤判,未來可能將產生災難性的後果。
InfoQ:為了進一步支持 AIOps 的落地,可觀測平台未來還需要在哪些方面進行升級?是否會考慮加入更多智能分析和自動化決策的功能?
周昕毅:本次分享中攜程可觀測性平台架構升級主要包含了如下幾個方面:
1)統一產品入口,提升用戶體驗
2)統一查詢層,查詢治理,查詢效率提升
3)統一日誌存儲,統一 Metric 存儲,存儲治理
上述幾個方面為 AIOps 建設提供了數據支撐,未來還需要為智能分析和自動化決策提供更多助力。
為了進一步支持 AIOps 的落地,未來的可觀測性平台架構升級會關注如下幾個方面:
1)異常檢測和預測組件
建設統一的異常預測系統,並持續優化。
2)運維自愈系統建設
建設統一的自愈系統,「眼手合一」,將「運維之眼」可觀測性平台產生的告警和「運維之手」自動化運維工作流平台整合在一起,在統一的平台中執行故障自愈。
InfoQ:隨著企業系統複雜性和數據規模的進一步擴大,您認為未來的可觀測性平台應該具備哪些核心能力?這些能力是否會影響 AIOps 的進一步發展?
周昕毅:個人觀點,未來的可觀測性平台的核心能力包括:
- 全棧視圖
目前 Logging、Tracing、Metrics 數據雖然能通過應用、機器、服務等維度進行關聯查詢和一站式展示,但是缺乏全棧視角,需要人工進行數據關聯和轉換。未來基於 AI 能力可以整合日誌、指標、追蹤數據等多種數據源,進行綜合分析和自動的關聯性分析。
- 智能化數據關聯
由於系統越來越複雜,每天都產生大量的 Logging、Metrics、Tracing 數據。運維工作中比較消耗時間的一個環境是故障定位、根因分析。常用的 AIOps 技術是利用機器學習和深度學習模型,自動檢測系統中的異常行為和性能瓶頸,進行智能告警和預測,這個技術方向後續還會持續升級,在智能化根因分析中發揮更大的作用。
- 實時數據處理
隨著 AIOps 技術持續發展,對於可觀測性平台數據的實時性、告警的實時性、查詢的時效性要求也會越來越高,可觀測性平台中實時化數據處理本來就是一個技術難點,後續實時數據處理能力將會成為可觀測性平台的核心能力之一,需要持續進行架構升級疊代。

嘉賓介紹
周昕毅,攜程雲原生研發總監。畢業於同濟大學軟體學院,15 年以上雲平台研發和運維管理相關工作經驗。目前負責攜程雲 IAAS 基礎設施的研發和運維管理、大數據基礎平台和可觀測性平台建設。主要研究方向是虛擬化、分布式存儲、可觀測性體系。
活動推薦