作為中國大規模私立醫院集團之一,和睦家醫療在香港、北京、上海、廣州、深圳等地已經布局了11家醫院和24家診所,提供包含從家庭醫學、婦產兒、心腦血管、腫瘤、泌尿、消化、骨科,重症醫學等完整醫療體系鏈。年服務患者量超百萬人次,其中外籍患者近十萬人次,構建了規模可觀的國際診療服務網絡。
作為進入中國的首批外資醫院,和睦家醫療擁有深厚的國際化醫療發展歷史和規模化外籍醫療團隊,為全球各地患者提供多語言溝通及診療服務。據統計,醫院內部英文醫療數據占比超過50%,西班牙語、法語等其他語言均有涉及。此外,醫療機構的英文病歷還需要定期翻譯為中文病歷,提交給衛健部門進行定期審查,通過醫療文書準確傳達病情、治療方案和護理指導至關重要。
不同於常規用語翻譯,醫療場景中的英文病歷翻譯有其獨特的複雜之處:醫療專業術語繁多,準確的術語翻譯是難點之一;醫學術語有大量縮寫,且在不同場景下的含義差異較大;病歷文本格式和書寫規範的專業性很強。在醫療場景下,通用翻譯軟體準確率較低,容易出現理解偏差。在翻譯模型投入使用之前,專業的醫療翻譯專家與雙語臨床醫生投入大量時間進行病案翻譯和校準工作,以保證醫療病案翻譯的質量。
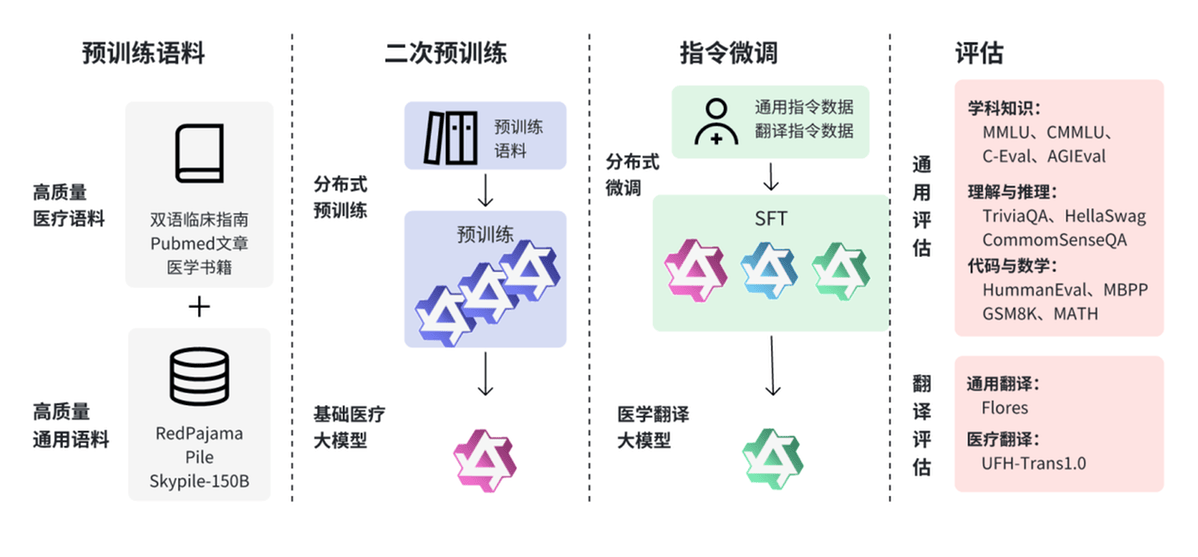
圖1:UFH醫療翻譯大模型技術路線圖
如上圖所示,為了解決醫療數據的私密性和安全性問題,和睦家醫療數智化AI團隊基於開源大模型研發了UFH醫學翻譯大模型,具體如下:
基座模型篩選:從學科知識、理解與推理、代碼與數學及通用翻譯四個方面,系統評估了Llama3.1、Qwen2.5、Deepseek2等開源大模型,最終選擇了基礎能力較強且中英雙語能力平衡的Qwen2.5作為基座模型。
二次預訓練:解析臨床指南、Pubmed文章及醫學書籍,結合和睦家醫療積累的醫學術語詞彙、醫學縮寫的場景詞義表及醫療翻譯專家的數據,對基座模型進行二次預訓練,注入醫療行業知識,獲得基礎醫療大模型。
指令微調:通過醫生構建的符合醫療場景的書寫規範和臨床語言習慣的翻譯數據集,結合Infinity等通用指令數據,對基礎醫療大模型進行微調,確保大模型能夠準確翻譯複雜的病歷和報告,保證翻譯的準確性和一致性。
自研翻譯大模型可以部署在本地,通過內網使用,無需調用外部服務,從而極大地保證了醫療數據的隱私性和安全性。優化後的醫療翻譯大模型還具備一定的指令遵循能力,可以通過調整系統提示詞進行多種語言的定向翻譯,並按特定格式要求適應不同醫療學科和場景的描述習慣。隨著大模型技術的持續優化,翻譯質量也不斷提升,能夠適應不斷變化的醫療需求。
和睦家自研的AI大模型在臨床投入使用後,受到了廣泛好評。通過與醫療翻譯專家共同制定評價標準,並使用不同類別、場景的測試數據對模型進行評估,結果顯示,AI大模型在醫療中英文定向翻譯中的準確率顯著提升,且相比通用翻譯軟體提高了2.5倍。醫生們對新系統的滿意度顯著提升,主動使用翻譯功能的次數增加了3倍。在個別案例中,複雜的手術記錄和多變格式的醫療報告均能被AI大模型準確翻譯,減少了因語言誤差導致的醫療風險,大幅度提高了醫務人員的工作效率。
和睦家醫療AI大模型在院內醫療翻譯領域的成功推出,使得臨床醫療翻譯進入了一個全新的階段。憑藉其精準、高效且智能的翻譯能力,有效消除了國際化診療場景下的語言障礙。和睦家醫療的AI團隊稱,其將繼續深化、疊代和拓展大模型的應用,探索醫療病歷摘要、醫療知識查詢、臨床輔助決策等更廣泛的醫療場景應用,進一步提升醫院的醫療服務效率和質量,助力醫生實現精準診斷和決策,為患者提供更加優質的醫療服務和個性化的診療方案。(中國日報北京記者站 杜娟)
來源:中國日報網
文章來源: https://twgreatdaily.com/zh-cn/8f36a50f9c5094ab3c7356b76f4f4de7.html