「作為一名基礎科研人員,當我第一次看到我們研發的蛋白質工程通用人工智慧技術,實現面向功能的蛋白序列設計,並被濕實驗驗證成功之時,心中湧起的激動是無與倫比的。」上海交通大學自然科學研究院&物理與天文學院&藥學院特聘教授洪亮表示。
 圖 | 洪亮(來源:洪亮)
圖 | 洪亮(來源:洪亮)
他進一步解釋道,這意味著以前需要靠專家經驗和大量實驗試錯的蛋白質工程,現在可以通過通用人工智慧進行定向設計,從而數倍乃至數十倍地減少時間和經濟成本。
此外,由於該模型具有通用性,對各領域都適用,決定了它將大大加速我國生物製造業、合成生物學、生物醫藥等領域的發展,幫助我國企業與國際頭部公司進行良性互動與競爭。
相關論文以《蛋白質工程與輕量級圖去噪神經網絡》(Protein Engineering with Lightweight Graph Denoising Neural Networks)為題發表在 Journal of Chemical Information and Modeling 上[1]。
上海交通大學自然科學研究院助理研究員周冰心博士為第一作者,洪亮教授擔任通訊作者。
 圖 | 相關論文(來源:Journal of Chemical Information and Modeling)
圖 | 相關論文(來源:Journal of Chemical Information and Modeling)
現如今,洪亮和團隊開發的蛋白質設計通用人工智慧 AccelProtein,通過 AI+ 計算的「干實驗」與高效的「濕實驗」協同閉環疊代,解決了傳統蛋白質工程中研發時間長、成本高、上位組合差等核心問題,為體外檢測、合成生物學等領域提供了數十款性能優異的蛋白質產品。

利用通用人工智慧設計蛋白質,已成為蛋白質工程領域的大勢所趨
眾所周知,蛋白質是生命系統的基礎,在細胞、組織和器官中扮演著重要角色。除了它所擁有的生物學意義,蛋白質對於眾多行業應用來說也至關重要,具有廣泛的市場價值。
例如,在生物醫學領域,可以作為藥物靶點和治療劑;在化學工程領域,能充當各種反應的關鍵催化劑。
不過,自然界的蛋白質,通常需要經過工程改造,提高它的活性、熱穩定性、對極端 PH 環境和惡劣溶劑的耐受性等多種指標之後,才能在各類工業應用中獲得應用。
而利用傳統蛋白質設計需要經歷長達數年的實驗研究,不僅耗時耗力、成本較大,也愈發不能滿足許多工業應用中重要蛋白質的改造要求。
近年來,深度學習技術的發展,在一定程度上打破了傳統方法面臨的瓶頸,利用 AI 來設計和改造蛋白質,逐漸成為該領域的大勢所趨。

自主研發蛋白質設計通用人工智慧,實現從序列到功能的精準蛋白預測
據介紹,在 AI 蛋白質設計領域,洪亮已有多年研究經驗。他本科和碩士分別畢業於中國科學技術大學和香港中文大學的物理系,博士時期在美國阿克倫大學高分子科學系從事蛋白質生物物理方面的機制研究。
在美國橡樹嶺國家實驗室完成博士後研究後,他來到上海交通大學,通過將實驗和計算生物學方法進行結合的方式,繼續對蛋白質的性能進行研究。
「其實這些研究都屬於『後解釋』的範疇。換言之就是,對蛋白質的一些物理機制進行解釋,比如它的運動形態和各種熱力學參數如何影響其功能的發揮。」洪亮解釋說。
2020 年,AlphaFold 的問世為洪亮開啟 AI 蛋白質設計研究打造了一個契機。
「用戶只需向 AlphaFold 輸入蛋白質序列,就能得到準確的結構預測,這對於整個分子生物學領域來說非常震撼。
但 AlphaFold 只解決了從序列到結構的問題,沒有解決結構到功能的問題,我們想做一套打通結構到功能的通用人工智慧,徹底打破傳統蛋白質工程方法的禁錮。」他說。
因此,他開始帶領團隊做 AI 蛋白質設計方面的研究,並在 2021 年開發了一套基於預訓練的蛋白質設計的通用人工智慧 AccelProtein ——與 AlphaFold 預測結構不同,AccelProtein 開創性地實現了從序列直達功能的精準蛋白質設計。
具體來說,該課題組通過預訓練方法,讓 AccelProtein 學習自然界已知的所有蛋白質序列和結構特徵,並探索與理解自然界中蛋白質序列與功能的映射規律,從而開發出一套能夠高效地設計出穩定性好、活性高、功能性強的 AI 蛋白質設計通用大模型。
那麼,該模型如何實現精準的蛋白質設計?
據洪亮介紹,自然界已知的具有完整胺基酸序列的蛋白質有幾億條,這些蛋白質的胺基酸序列以存在即合理的方式排列著。
在掌握這些序列以後,該團隊採用雙重任務學習方法:一方面,幫助大模型在經過預訓練學習以後,掌握滿足蛋白質序列排布的語言規則,另一方面,通過所構建的億量級蛋白質標籤資料庫,為蛋白質打上標籤,進一步提升模型精度,從而提供精準、高效地蛋白質設計,大大降低試錯成本。
和同類通用人工智慧模型相比,AccelProtein 主要具備如下優勢。
其一,架構優勢。採用幾何深度學習方法對模型架構進行簡化,能在保證模型精度的同時降低模型參數,便於進行大規模預訓練和推理。
其二,策略優勢。利用小樣本乃至零樣本學習方法,提高大模型的工程泛化能力,幫助它在僅有少數濕實驗數據的情況下實現蛋白質性能優化,極大地提高了蛋白質設計的效率——以往需要 2~5 年才能完成的項目,在 AccelProtein 的支持下只需要 2~6 個月即可完成。
其三,數據優勢。通過與國內多家科研院所和企業的合作,獲得了豐富全面的高精度蛋白質序列數據,尤其是一些高熱、低溫或強酸強鹼環境下的數據。
此外,該課題組還開發了其他幾種 AI 蛋白質通用大模型,並取得了可與 Google、Meta 等國際團隊推出的同類成果相媲美的成績。
根據美國哈佛大學醫學院創立的蛋白質突變性質預測榜單 ProteinGym,洪亮團隊提出的大模型奪得非檢索方法排名第一的桂冠,並在總榜前十名的排名中占據一半席位。
其中,預測真核蛋白的大模型排名第一,預測原核蛋白的大模型排名第二,預測人類蛋白的大模型排名第三[2]。
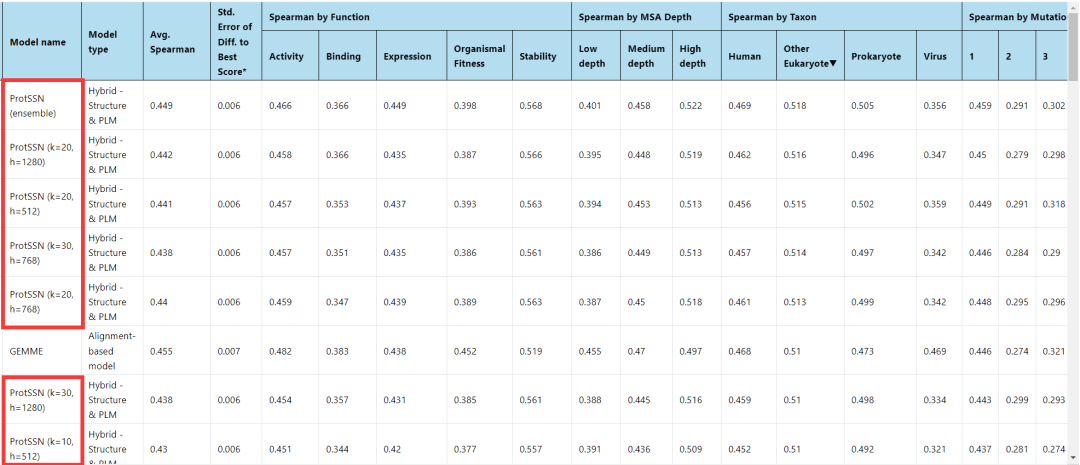 (來源:ProteinGym 榜單)
(來源:ProteinGym 榜單)
如上所說,在整個蛋白質設計過程中,通用人工智慧可在不需要或僅有少數濕實驗數據的條件下,完成對蛋白質改造的賦能。這是否意味著,生物實驗在其中已經沒有發揮作用的空間?
對此,洪亮持否定看法。
他認為,首先,AI 在優化特定蛋白時,還需要濕實驗來指導和調整方向。
其次,生物學家也能夠通過濕實驗提出更多典型的科學問題,便於大模型團隊基於這些問題開發定製化的大模型,從而實現批量的蛋白質設計。

創辦 AI 蛋白質設計公司,已完成十餘項蛋白質產品交付
正是基於在 AI 蛋白質設計領域取得的成果,洪亮於 2021 年創辦了上海天鶩科技有限公司。
後者已經在不到三年時間裡,完成了十餘款蛋白質設計項目的成果交付,並已獲得數千萬元 Pre-A 輪融資,投資機構包括耀途資本、金沙江資本等。
據了解,目前該公司的服務範圍已拓展至創新藥、體外診斷、合成生物學等多個行業領域。
當下及未來,該課題組也在嘗試拓展與更多科研院所和企業之間的合作,希望能在蛋白質工程這一賽道,打出全國最好、世界最優的標誌。
在洪亮看來,雖然中國的生物製藥行業目前已然具備強大的實力,但在全球整個產品鏈條中的利潤比仍然較低。
原因在於,缺乏良好的設計上游產品的能力,以至於在短時間內無法實現「破局」。
「畢竟國際企業所擁有的設計能力,是在過去一百年來經過大量的科研探索和實驗數據積累,以及數不清的人才積澱的基礎上才產生的。
但如今有了蛋白質通用人工智慧,我們就可以不走國際企業的這條發展道路,直接利用 AI 來實現『換道超車』。」洪亮表示。
可以想見,一旦這條橫穿跑道的道路被走通,我國就能在合成生物學和生物醫藥領域,和國際企業展開一場全新的競爭。
參考資料:
1.Zhou, B., Zheng, L., Wu, B., Tan, Y., Lv, O., Yi, K., ... & Hong, L. (2023). Protein engineering with lightweight graph denoising neural networks.Journal of Chemical Information and Modeling.
2.https://proteingym.org/benchmarks
運營/排版:何晨龍