
英偉達 (NVIDIA) 發布了其Blackwell架構AI晶片B200首個在Llama 2 70B大模型上的MLPerf Inference 4.1測試結果,顯示B200的性能相較上一代的Hopper H100有4倍的提升,即性能提升了300%。在此同時,AMD也公布了8個MI300X GPU在相同測試中的成績,達到了集成8個H100與英偉達DGX H100相當的成績,這也顯示了AI晶片市場的競爭激烈。
具體來說,單個英偉達Blackwell B200 GPU在AI推理測試中,可以每秒生成10,755個Token。另外,在脫機參考測試中,則可以每秒生成11,264個Token。作為比較,雖然採用4個Hopper H100 GPU的伺服器提供了接近的結果,但是單個H00 GPU每秒生成的Token數則僅有B200 GPU的約1/4。這也證明了英偉達的說法,即單個Blackwell B200 GPU的速度,達到了單個Hopper H100 GPU的約3.7至4倍。
而針對這樣的測試數字、市場進行了相關分析。首先,英偉達的Blackwell B200處理器使用的是FP4精度,因為其第五代Tensor Core支持該格式,而採用Hopper的H100則僅支持和使用FP8。雖然MLPerf指南允許這些不同的格式,但Blackwell B200中的FP4性能使其相比FP8傳輸量增加了一倍,因此這是需要注意的重要事項。
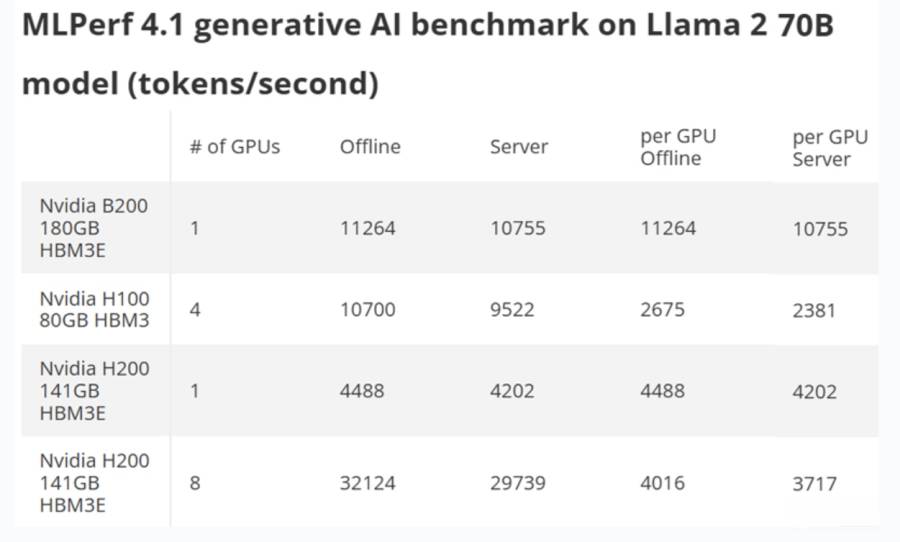
接下來,英偉達在使用單個B200與四個H100 GPU對比方面似乎有些差異。因為,擴展從來都不是完美的,因此單個GPU往往是GPU性能的最佳情況。而MLPerf 4.1並沒有列出單個GPU H100結果,只有一個B200結果,這使得它們之間的比較並不公平。然而,單個H200的性能達到了每秒4,488個Token,這代表著B200在該特定測試中,速度達到了H100的2.5倍,即快了150%。
再者,雙方之間HBM容量和帶寬差異也是影響因素,並且存在很大的跨代差異。測試的B200 GPU配備180GB HBM3E內存,而H100 SXM配備80GB HBM,H200則是配備96GB HBM3和高達144GB的HBM3E。其中,具有96GB HBM3的單個H200在脫機模式下僅達到了3,114個Token。因此,數字格式、GPU數量、內存容量和配置都存在差異,這些差異就會影響其測試出來的結果。而且,許多差異僅僅是因為Blackwell B200是一款具有更新架構的新晶片,所以進一步都影響了其最終測試性能表現。
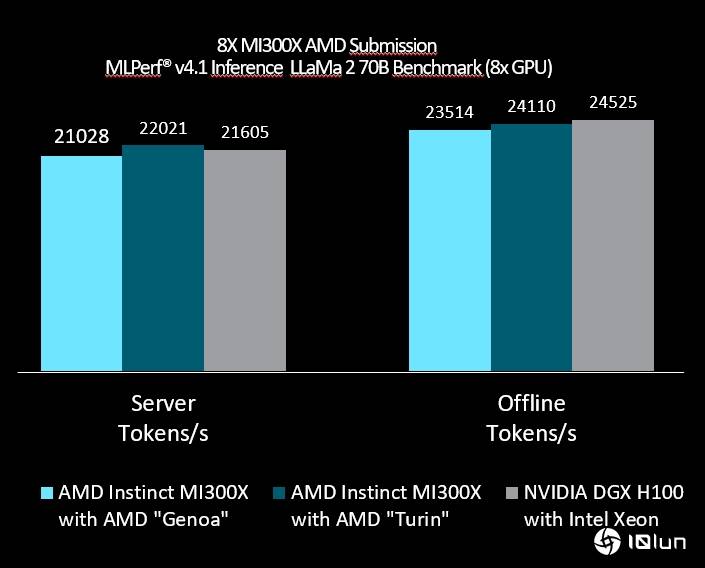
回到配備141GB HBM3E內存的英偉達H200上,它不僅在以Llama 2 70B大型語言模型為特色的生成式AI基準測試中也表現出色,而且在數據中心類別的每一項測試中都表現出色。再來看,AMD公布同樣的MLPerf Inference 4.1測試,其MI300X的成績。使用搭配AMD Genoa CPU及8個MI300X的伺服器,在測試中性能達到了每秒21,028個Token,而在脫機參考測試中,性能達到了每秒223,514個Token。至於,使用AMD Turin CPU及8個MI300X的伺服器,測試中性能達到了每秒22,021個Token,在脫機參考測試中,性能達到了24,110個Token。
這樣的結果,代表使用8個MI300X的系統達到了接近英偉達DGX H100系統的成績,差異大概在2-3%以內,也代表在測試中,單個MI300X GPU的性能達到了與英偉達H100 GPU相當的水準。而綜合比較單個AMD MI300X與英偉達H200和B200的MLPerf Inference 4.1測試成績來看,英偉達B200的成績也是遙遙領先於MI300X和H200,其性能平均達到了MI300X的4倍左右,也達到了H200的約2.5倍左右。這也進一步凸顯了英偉達B200性能的領先性。
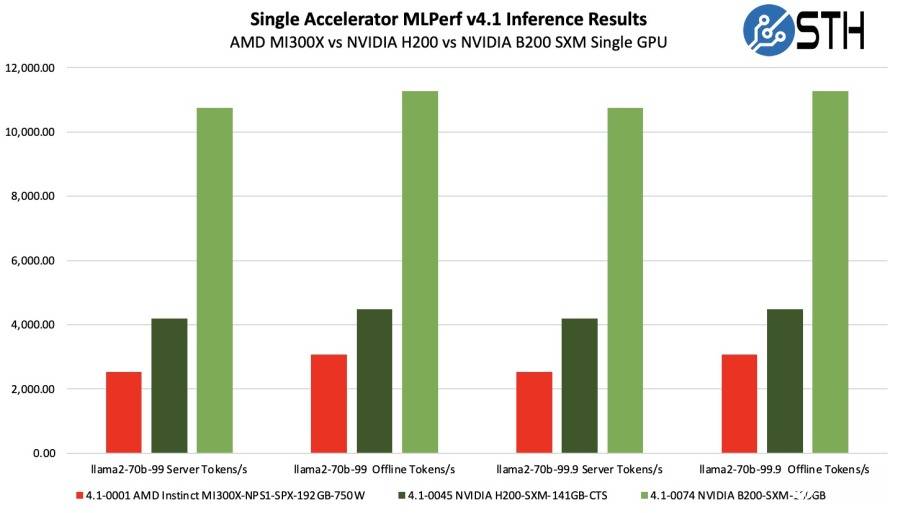
同樣需要指出的是,AMD MI300X配備了更大的192GB HBM,而B200則是180GB HBM。不過,MI300X的TDP功耗為750W,但英偉達H200和B200的TDP功耗則高達1,000W。
(首圖來源:科技新報攝)