文|夢飛
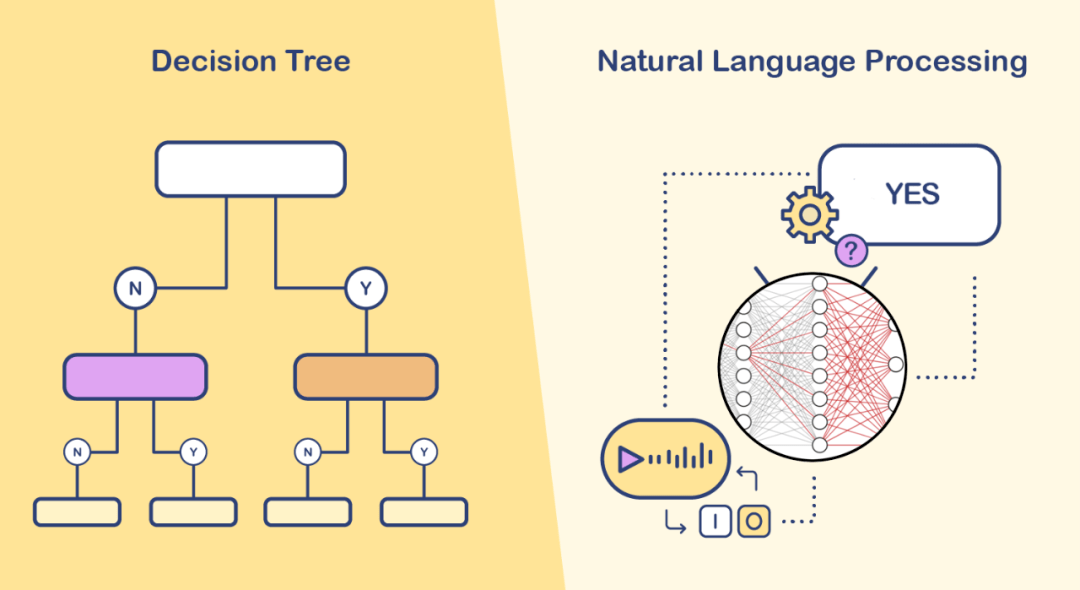
圖1 基於規則的聊天機器人通常使用「if-else」語句或其他類似技術對預設的問題和回答進行匹配,而類似ChatGPT的聊天機器人則通過預訓練的大型語言模型實時生成自然的答案
生成式AI發展簡史
隨著大數據和計算機處理能力的不斷增強,人們開始期望計算機能夠像人一樣創造內容和產生創新想法。這導致了生成式AI技術的興起,使計算機可以模仿人類的創造力,為我們帶來更多的創新和發展。
生成式AI的歷史可以追溯到20世紀50年代和60年代,當時人們開始使用機率論和資訊理論來建立語言模型。這些模型可以將輸入的文本數據轉換成機率分布,然後基於這些機率分布生成新的文本(圖2)。
圖2 早在人工智慧出現以前人們就已經開始語言模型的相關研究,比如1906年馬爾可夫提出的馬爾可夫鏈可以應用於多個不同的領域,而它也算得上是一種簡單的語言模型
20世紀90年代,隨著神經網絡技術的發展,生成式AI進入一個新的階段。神經網絡可以通過訓練來自動學習文本數據的潛在結構和模式,並且可以用這些模式來生成新的文本。其中一個著名的生成式模型是基於循環神經網絡(RNN)的語言模型,它可以預測一個句子中的下一個單詞,並將其作為輸入來預測後面的單詞,從而生成連續的文本。
近年來,隨著深度學習技術的進一步發展,生成式AI取得了重大進展。其中出現了不少著名的模型,包括生成對抗網絡(GAN)、變分自編碼器(VAE)、擴散模型(Diffusion Models)和轉換器模型(Transformer)等。這些模型可以生成高質量的圖像、視頻、音頻和自然語言文本,並在許多應用領域產生了巨大的影響,例如自然語言處理、計算機視覺和音頻處理等。
生成式AI的工作流程
生成式AI的基本原理是使用機率模型或神經網絡模型,將已有數據的結構和規律學習到模型中,並基於這些結構和規律生成新的數據。
1、模型訓練
首先,需要通過大量的訓練數據來訓練生成式AI模型。在訓練過程中,生成式AI模型會學習輸入數據的機率分布和結構,這些數據可以是文本、圖像、音頻或視頻等。
2、模型選擇
模型訓練完成後,需要選擇合適的模型來生成新的數據。不同類型的數據需要選擇不同的模型來生成,比如自然語言文本可以使用RNN或LSTM模型來生成,圖像可以使用GAN、VAE或擴散模型來生成(圖3)。
圖3 不同類型的生成式模型比較
3、生成數據
一旦選擇好合適的模型,就可以使用該模型來生成新的數據。生成新數據的方式通常是隨機採樣或條件採樣。隨機採樣是指從模型學習到的數據分布中隨機抽樣生成新的數據,而條件採樣是指在輸入一些條件的情況下,從模型學習到的條件分布中採樣生成新的數據。
4、評估生成結果
生成的新數據需要經過評估來判斷其是否符合預期。評估生成結果的質量是一個開放性的問題,它可以基於客觀指標進行,也可以依賴人類主觀感受進行,比如自然語言文本可以基於語法正確性、連貫性、意義合理性等指標進行評估,圖像可以基於視覺質量、真實感等指標進行評估。
5、調整模型
根據生成結果的評估,可以對模型進行調整和優化,從而提高生成結果的質量。調整模型的方式通常包括增加訓練數據、調整模型參數、優化模型結構等方法。
總的來說,生成式AI的工作過程是一個疊代的過程,需要不斷地調整模型和評估生成結果,從而得到更好的生成效果。以上是從生成的角度來說的,如果換成客戶端使用的角度,其操作過程就簡單得多了(圖4)。
第1步:用戶輸入條件設置,比如希望生成的內容的關鍵詞、主題或上下文等信息。現在流行的說法稱之為:Prompt(提示)。
第2步:等待服務端模型的處理。
第3步:獲取服務端模型返回的生成內容。
圖4 用戶的輸入通過受訓的語言模型處理最終輸出全新的文本
生成對抗網絡(GAN)
上面我們對生成式AI有了初步了解,接下來就對其發展過程中的幾個關鍵技術分別加以介紹。首先是生成對抗網絡(Generative Adversarial Networks,簡稱GAN),這是一種深度學習模型,由加拿大蒙特婁大學Ian Goodfellow等人於2014年提出。隨後幾年,GAN模型迅速發展,成為AI繪畫的主流模型。2018年,NVIDIA公司發布基於GAN模型的StyleGAN,用戶只需隨便塗抹幾筆,StyleGAN即可將其所「畫」的不規則色塊轉化為優美的風景、人物圖片,吸引了不少人注意。2019年,一個名為「不存在的人」英語網站更是將AI繪畫推向一個高潮,用戶每次刷新該網站,都會自動生成一幅真假難辨的人臉畫像,其逼真程度令人驚嘆,在圖像生成領域產生巨大影響。
如今在網上可以找到不少GAN的有趣應用。以GANpaint為例,打開它的網頁即可看到AI生成的多幅精美圖片(圖5,http://gandissect.res.ibm.com/ganpaint.html)。
圖5 基於GAN模型的AI繪畫工具GANpaint
圖片左側提供了tree(樹)、grass(草地)、door(門)、sky(天空)、cloud(雲)、brick(磚塊)、dome(屋頂)等繪畫元素,這些元素每一個都對應於一組20個神經元。下方則有draw(繪畫)、remove(移除)等操作模式。選擇某個繪畫元素,再設置draw模式,然後在畫面中隨意塗抹即可將該元素添加到當前畫面中。不用擔心會「塗壞」畫面,因為它會智能計算,自動確保畫面的完整。反之,如果設置的是remove模式,則會消除畫面中的相關元素。這一工具的實現原理,在https://gandissect.csail.mit.edu中有詳細介紹。
GAN由兩個神經網絡組成:生成器(Generator)和判別器(Discriminator)。生成器用於生成與真實數據(比如真人照片)類似的虛假數據(比如AI繪製的虛擬人照片),判別器則用於區分真實數據和虛假數據。這兩個神經網絡通過博弈的方式進行訓練,即生成器試圖欺騙判別器,而判別器則努力區分真實數據和虛假數據。訓練過程中,生成器逐漸學習生成更加逼真的虛假數據,而判別器逐漸學習如何更好地區分真實數據和虛假數據。當生成器生成的虛假數據能夠「騙」過判別器時,就說明生成器已經學會了生成與真實數據相似的數據了(圖6)。
圖6 生成對抗網絡GAN中生成器和判別器互相博弈
如上圖所示,GAN生成器的工作流程大致如下:
1、隨機噪聲輸入:生成器將隨機的噪聲向量作為輸入,通常是基於某種機率分布的高維向量。
2、通過神經網絡生成圖片:生成器使用深度神經網絡將噪聲向量映射到生成的圖像空間,輸出生成的圖片。這個過程可以看作是將抽象的高維噪聲向量轉換成具體的圖像表示。
3、評估生成圖片:生成器生成的圖片經過判別器的評估。
4、優化生成器:如果生成器生成的圖片被判別器認為是真實的,那麼生成器就被認為是生成了高質量的圖像。生成器的目標就是通過不斷地疊代,使自己生成的圖片更加接近真實的數據分布。
5、訓練結束:通過不斷訓練疊代,生成器會逐漸提高自己的生成能力,最終生成高質量的圖像。
GAN判別器是一個二分類器,它的目標是將生成器生成的數據與真實數據分開,評估生成器生成的圖像是否與真實數據相似。它的工作流程大致如下:
1、接收輸入數據:判別器將生成器生成的圖像或真實數據輸入到神經網絡中。
2、提取特徵:判別器通過一系列卷積層、池化層、激活函數等,將輸入數據映射到一組特徵向量。
3、二分類:判別器使用一個Sigmoid函數(一種激活函數)將特徵向量映射到一個0到1之間的值,表示輸入數據屬於真實數據的機率。如果判別器判斷輸入數據屬於真實數據,則輸出接近1的機率值;如果判斷輸入數據屬於生成器生成的數據,則輸出接近0的機率值。
4、優化判別器:判別器通過不斷訓練疊代,優化自己的判別能力,使其可以更準確地將生成器生成的圖像與真實數據分開,從而推動生成器的生成能力不斷提升。
GAN不只應用於圖像生成領域,它也可以處理其他類型的數據(如文本),在自然語言處理、金融、醫學、遊戲開發等多個領域都有出色的表現。當然GAN的藝術表現可能是最為出名的。2018年,法國藝術團體Obvious使用名為Eerie AI的生成對抗網絡創建了《愛德蒙·貝拉米肖像》(Edmond de Belamy,圖7),這個根本不存在的虛擬人肖像畫被以40多萬美元的高價成功拍賣,在當時社會引發了廣泛的討論。與《愛德蒙·貝拉米肖像》同批創作的肖像作品共有11幅,被稱之為《貝拉米家族》(圖8)。
圖7 基於GAN創作的《愛德蒙·貝拉米肖像》,其訓練數據採集了14~20世紀的15000幅肖像畫作品
圖8 《貝拉米家族》系列肖像畫
擴散模型(Diffusion Models)
GAN之前,AI繪畫效果基本上都是些似是而非的「抽象畫」,沒有得到太多的關注。GAN出現之後,其逼真的繪畫效果讓人眼前一亮,但即使如此AI繪畫依然只是在小眾的圈子裡流行。直到2021年OpenAI的DALL-E出世,及其後推出的升級版DALL-E 2,才真正讓AI繪畫進入大眾視野,一時風靡網絡。之所以如此,一方面是DALL-E 2的繪畫效果幾乎可以與專業畫師相媲美,一方面是它在用戶端的操作極其簡單:用戶只需輸入自然語言文本對繪畫內容進行描述,即可得到相應的精美繪畫作品。OpenAI網站的博客上給出了生動的例子,輸入文本提示(Prompt):「an illustration of baby daikon radish in a tutu walking a dog(穿著芭蕾舞裙的小白蘿蔔在遛狗)」,即可得到一系列創意的插畫作品(圖9)。
圖9 將小白蘿蔔、狗、芭蕾舞裙這些元素組合到一起,構成超現實主義的插畫
在DALL-E之後,類似的AI繪畫大模型紛紛湧現,比如Stable Diffusion、Midjourney、Disco Diffusion。這裡,我們可以在線體驗一下Stable Diffusion的魅力。首先打開網頁https://replicate.com/stability-ai/stable-diffusion,然後在Input下的Prompt框中輸入繪畫提示語,比如「山外青山樓外樓,國畫」。不過國外的AI模型對中文的支持較弱,所以我們可以將提示語翻譯成英語:「Hill outside Castle peak building outside building, traditional Chinese painting」,提交後就可以得到一幅不錯的畫作了(圖10)。
圖10 為「山外青山樓外樓」古詩配畫
我們還可以試試另外一個網站(https://huggingface.co/spaces/stabilityai/stable-diffusion),同樣也是基於Stable Diffusion的應用。輸入上文一樣的提示語,提交後即可得4幅畫作樣品,看起來有模有樣(圖11)。
圖11國畫風格的AI繪畫
上述DALL-E/DALL-E 2、Stable Diffusion、Midjourney、Disco Diffusion,它們的共同點都是基於擴散模型(Diffusion Models)。擴散模型的靈感來自非平衡熱力學,它定義了一個馬爾可夫擴散步驟鏈,以緩慢地向數據添加隨機噪聲,然後學習逆轉擴散過程以從噪聲中構建所需的數據樣本(圖12)。
圖12 通過緩慢添加(去除)噪聲生成樣品的正向(反向)擴散過程的馬爾可夫鏈(DDPM,Ho et al. 2020)
擴散模型有多個變體,比較知名的有去噪擴散機率模型(Denoising Diffusion Probabilistic Models,DDPM),另外還有擴散機率模型(Diffusion Probabilistic Models,DPM)、噪聲條件評分網絡(Noise-Conditioned Score Networks,NCSN)等,它們都是基於連續擴散的過程來生成樣本,但是在取樣方式、噪聲參數調節以及去噪過程等方面則有所不同。每個模型都有其局限性和假設,這可能會影響它們在某些任務上的表現。
如今的AI繪畫應用中擴散模型風頭正勁,遠遠壓過了GAN。但實際上在圖像生成領域,這兩個模型各有優缺點。擴散模型要比GAN慢,疊代更多,但是可以產生高質量的、更加逼真的視覺效果。GAN比擴散模型更快、更高效,但生成的圖像質量要偏弱。
文生圖技術(Text to Image)
近來這一波AI繪畫的浪潮,文生圖技術(Text to Image)是重要的推手之一。之前再智能的AI繪畫工具也都需要用戶親自操作畫筆(哪怕是畫幾個最簡陋的圖形)。但自DALL-E起,普通用戶只需輸入文本描述,AI就可以自動繪畫,其方便程度超乎想像,也因此AI繪畫得以在大眾中廣泛流行。
圖13 虛線上方是CLIP模型的訓練過程,建立了文本和圖像的聯合表示空間。虛線下方是文本到圖像的生成過程,通過CLIP文本嵌入,調節產生最終圖像的擴散解碼器。注意:CLIP模型在圖像生成的訓練過程中被凍結(Ramesh et al. 2022)
任何技術都不會是一蹴而就的,文生圖技術同樣是多年發展的結果,它大概經歷了以下過程:
二十世紀九十年代末期,一些早期的文本生成模型,如n-gram模型、循環神經網絡(Recurrent Neural Network,RNN)等開始應用於自然語言處理領域,但是這些模型還不能直接生成圖像。
2005年,Hinton等人提出了深度信念網絡(Deep Belief Network,DBN)模型,可以學習到輸入文本和圖像之間的複雜關係,從而實現文本到圖像的轉換。
2014年,Reed等人提出一種基於GAN(Generative Adversarial Networks)的文本到圖像生成方法,該方法首次將GAN應用於圖像生成領域,並在一定程度上實現了文本到圖像的轉換。
2015年,基於條件GAN的文本到圖像生成方法出現,該方法能夠根據輸入的文本描述生成與之匹配的圖像,並且具有更好的生成效果和多樣性。
2016年,Reed等人提出一種基於卷積神經網絡(Convolutional Neural Network,CNN)和RNN的文本到圖像生成方法,可以生成高解析度的逼真圖像。
2018年,Google提出基於Transformer模型的文本到圖像生成方法,能夠根據輸入的文本生成高質量的圖像,這一方法在多個任務上取得了較好的結果。
近年來,隨著深度學習技術的不斷發展和優化,基於GAN、VAE、Transformer等模型的文本到圖像生成方法不斷被改進和拓展,具有更高的生成質量和多樣性,同時也被廣泛應用於電商、廣告、藝術創作等領域。
生成式AI的未來發展趨勢
生成式AI是一項高度複雜的技術,它涉及到深度學習、自然語言處理、計算機視覺、強化學習和機率論等多個領域,因此它面臨著許多挑戰和限制。下面是生成式AI面臨的主要挑戰以及未來的發展趨勢。
1、數據質量問題
生成式AI需要大量的高質量數據來進行訓練,而現實中的數據往往存在噪聲、偏差和錯誤,這使得生成式AI面臨著許多挑戰。為了解決這個問題,未來需要進一步開發和改進數據清洗和預處理技術,以提高數據質量和可用性。
2、計算資源限制
生成式AI需要大量的計算資源來進行訓練和推理,這使得它在實際應用中面臨著計算資源限制的問題。為了解決這個問題,未來需要進一步發展高效的計算和算法優化技術,以提高生成式AI的效率和性能。
3、可解釋性問題
生成式AI的黑盒性質使得它們的工作原理難以理解和解釋,這限制了它們在實際應用中的可用性和可靠性。為了解決這個問題,未來需要進一步發展可解釋性的生成式AI技術,以提高它們的透明度和可理解性。
4、多模態和跨模態生成問題
未來的生成式AI需要進一步開發多模態和跨模態生成技術,以支持多種數據類型的生成,包括文本、圖像、音頻和視頻等。
5、法律和道德問題
生成式AI可能存在版權、隱私和道德等方面的問題,這需要在應用生成式AI時加強法律和道德方面的考慮和約束,以確保其合法和道德的使用。
總之,生成式AI仍然是一個快速發展和不斷創新的領域,未來將會面臨許多挑戰和機遇。通過不斷的研究和發展,我們可以期待生成式AI在更多領域的應用,為人類帶來更多的價值和改變。另外,生成式AI涉及的領域廣泛,內容豐富,一篇短文不足以窺其全貌,最後我們放幾張較為全面的生成式AI分類圖,希望給那些想要深入深究的朋友一點參考。 CF
圖14 根據輸入和生成格式劃分的生成式AI模型分類(圖源:arXiv:2301.04655v1)
圖15 生產式AI的代表產品時間線,其中除2021年發布的LaMDA和2023年發布的Muse之外,其他皆為2022年發布(圖源:arXiv:2301.04655v1)
原文刊登於2022 年 12月15 日出版《電腦愛好者》第 24 期
END
更多精彩,敬請期待……