嘉賓 | 郭憶
編輯 | 李忠良
在當今數據驅動的時代,企業面臨著越來越多的數據管理和治理挑戰。為了有效地利用數據,許多企業開始採用 DataOps 方法論,以實現數據開發流程、數據消費流程和數據運營流程的整合。
在 ArchSummit 全球架構師峰會上海站,我們邀請了網易數帆大數據產品技術負責人郭憶分享了網易基於 DataOps 的敏捷、高質量數據開發實踐,本文為演講整理,期待對你有所啟發。
我來自網易數帆大數據團隊,隸屬網易杭州研究院,我們研究院主要為整個網易集團提供雲計算、大數據和人工智慧相關的平台建設。我們的服務覆蓋了網易雲音樂、網易嚴選、網易有道等業務,這些業務都在我們提供的平台上,通過不同租戶形式進行業務層面的隔離。此外,我們還負責網易集團的公共數據層的建設,包括用戶畫像數據等,我們利用這些數據為網易嚴選和網易有道新聞導流。
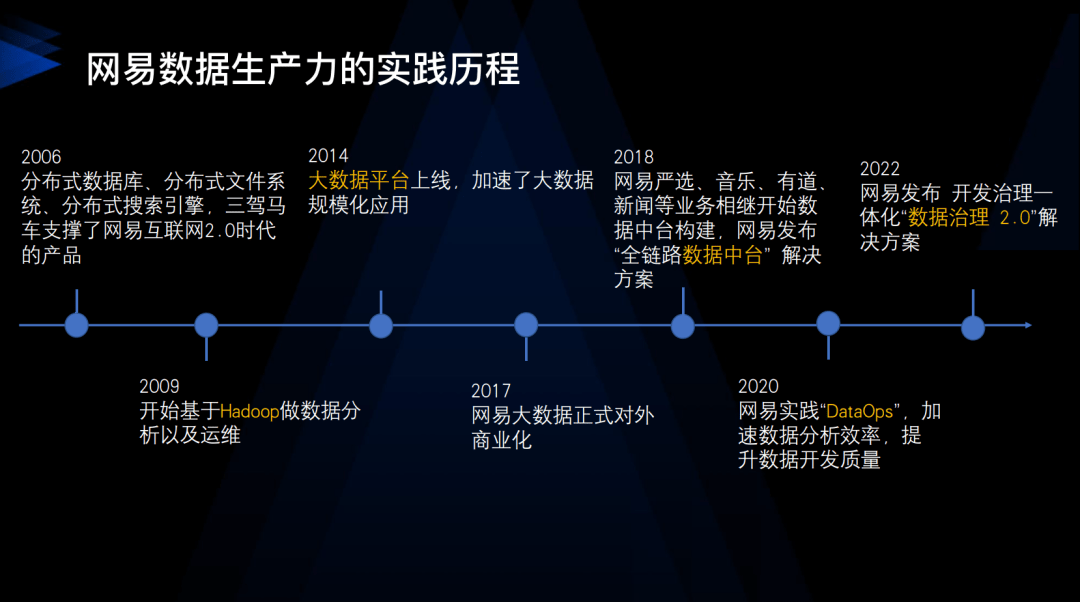
我們的數據技術部門成立於 2006 年,初期主要做資料庫、分布式文件系統和分布式搜尋引擎,這三大技術也支撐了網易在網際網路 2.0 時代的產品,如網易博客、網易相冊以及後來的網易雲音樂等。2014 年,我們上線了大數據平台,以及有數 BI 工具,大大推動了網易在數據分析領域的應用。現在,我們的平台有超過 3000 人的日活,他們利用我們的平台完成日常的數據分析工作。
2018 年,我們開始建設數據中台,網易嚴選、考拉、雲音樂業務也相繼通過數據中台進行數據體系的重構。2020 年,我們開始實踐 DataOps,以提高我們的數據分析效率,提供端到端的數據提速。2022 年,我們開始實踐開發、治理一體化的 DataOps。我們的最終目標是構建一個人人用數據和時時用數據的企業數據文化。
在構建這樣的數據文化上,我們有一套完整的方法論,其中 DataOps 是一個核心的方法論。我們要提供端到端的 DataOps,這需要我們首先構建數據技術,比如數據中台的技術、開發治理一體化的技術等。然後在這個平台上,我們需要沉澱豐富的企業數據資產,比如企業的公共模型、指標體系、標籤體系、數據標準、數據質量稽核規則等。有了這些數據資產,我們就可以開始輸出,讓更多的企業人員使用這個平台。
在這個過程中,數據產品化是一個非常重要的環節,我們需要開發大量的數據產品,讓數據觸及到一線的業務人員。同時,我們還需要有數據運營的過程,能夠把整個流程串聯起來。為了推動這個過程,我們每年舉辦數據分析領域的三大賽事,包括數據治理大賽、數據分析大賽和數據可視化大賽,以此來挖掘並推廣一些優秀的數據使用案例。
我們的技術架構總體上包括四層。
最底下一層是 大數據的計算和存儲引擎,包括湖倉一體技術、存算分離技術和在線離線混合調度技術等。上一層是 基於 DataOps 的全生命周期開發平台,其中包括數據測試環節,通過自動化的數據測試和任務發布技術提升整個數據開發流程的效率。再上一層是 數據治理和數據中台體系,以指標系統模型設計中心和數據服務為核心的數據中台體系和以數據標準為核心的數據治理體系。最上一層是 數據應用層,包括 BI 應用、標籤畫像和數據產品等應用。
總的來說,我們的所有工作都圍繞著如何發揮數據的生產力,構建一個人人用數據,時時用數據的企業數據文化。
DataOps 1.0:敏捷、高質量開發實踐
整個網易 DataOps 主要分為 兩個階段。
第一個階段,我們專注於數據中台內部的 DataOps 實踐,以實現敏捷且高質量的開發。以下我將分享一些我們選擇實行 DataOps 的案例,這些都是從一些痛苦的教訓中獲得的。
例如,我們有一個電商業務,在這個業務中,消費者購買三次後會得到一個優惠券。因為上游任務的改變,其中一個任務在我們的網易嚴選平台上有 17 層的任務嵌套關係。當上游任務變更後,下遊資損表的計算邏輯受到了影響,結果消費者即使沒有購買三次,也收到了優惠券,這些優惠券被核銷了 30 萬,這些直接計入當年數據部門的成本。另一個例子是,任務依賴配置丟失,導致上游任務數據未完成,下游任務提前調度,導致數據空跑,造成了 20 萬的資損。
在網易,這類涉及到資損的事故都是 P1 級別的,對我們數據團隊的打擊非常大。我們做過一次統計,因為數據開發任務變更導致的數據質量問題占比達到了 65%。而且我們非常關注一個指標,這個指標就是需求的按期交付率。所有的需求,都會在我們平台上開發的數據分析任務,在建立任務時候必須會關聯一個 JIRA 的連結,所有的任務都必須進入 JIRA 進行統一項目管理。
在 JIRA 中,我們會設定任務的交付時間。當任務上線時,JIRA 會自動關閉。我們發現只有 70% 的需求能按時交付,大量的任務會延期交付。
此外,任務依賴關係極其複雜,我們曾經有一個煙囪式的架構,但在 2018 年,我們改變了,開始構建數據中台。在這裡我們構建了整個企業的公共模型層,所有的上下游任務都在依賴這個公共模型層,這使得依賴關係異常複雜。再加上缺少整個發布管控環節,我們可能隨意上線修改,沒有任何的卡點,沒有任何的 Check。缺少自動化的測試,數據質量就難以保證。
因此,我們的目標是提高整個數據開發的敏捷性和效率、提高整個數據的質量。對於一個數據中台團隊來說,其核心目標是提升效率並降低成本。在提升效率的過程中,質量的保證尤為關鍵。我們開始思考有沒有一種工程化的方法,能夠幫助我們更高效地做任務的發布,減少在多套環境之間的發布時大量的手動操作和改配置,甚至需要改代碼。
因此,我們採用了 DataOps,希望通過軟體工程的方法,來改進整個數據開發流程。基於自動化的數據測試和任務的發布技術,來提高我們整個數據交付的效率,確保我們的需求交付更有保障。
我們構建了一個數據發布流水線,包括 可持續集成、可持續交付和可持續部署三個階段,按照編碼、編排、測試、代碼審查、發布審核和部署上線六個流程。
每一個流程都會有工具平台的支持和流程規範的制定。在這個過程中,我們會使用一些關鍵的技術,比如數據沙箱技術,進行不同環境之間的數據隔離,進行數據比對。我們還會進行代碼審查,發布審核,通過發布包的形式,實現多環境的高效發布。
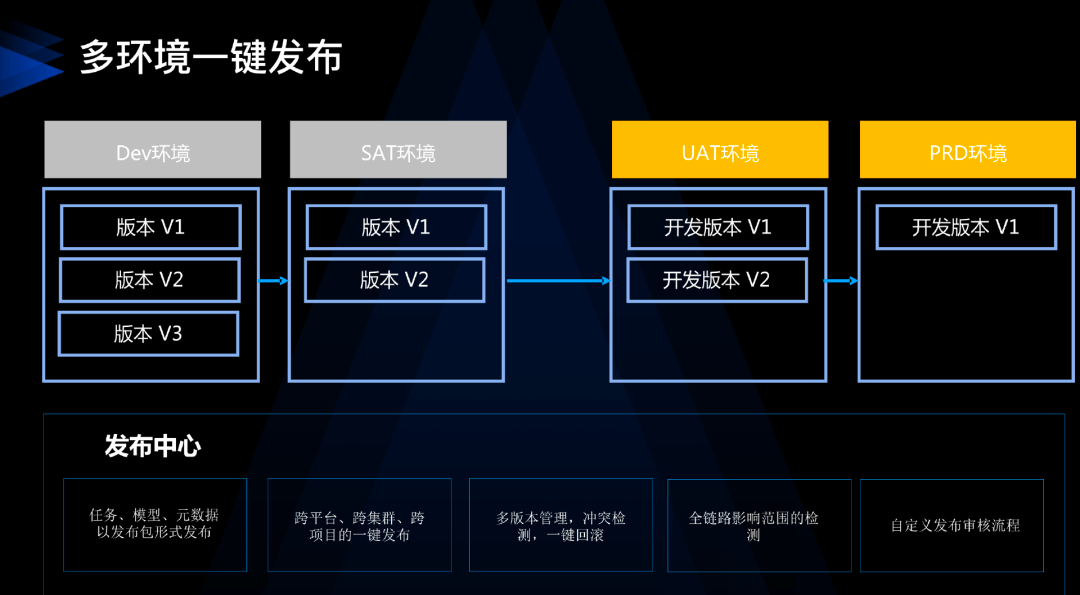
舉個例子,我們去年為多家券商做了金融行業的數據運營。在這個行業,常規的操作流程一般會有四個環節,即 DEV 環境(開發環境)、SAT 環境(系統集成環境)、UAT 環境(用戶可用性驗證環境)、和 PRD 環境(生產環境)。DEV 和 SAT 環境通常是由開發團隊或外包團隊負責,而 PRD 環境則是由運維團隊負責。
在這個過程中,我們需要考慮到任務的 依賴關係,比如,如果一個任務依賴於上游的另一個任務,那麼上游任務未上線可能會導致下游任務出問題。因此,我們期望能夠自動打包,根據任務之間的依賴關係生成發布包,以便在不同環境之間打包和部署。另外,我們還經常遇到一些協同問題,比如任務已上線,但相關的模型表卻未上線,或者模型表已上線,但任務未上線。為解決這些問題,我們需要進行多資源整合打包。
另外,所有的任務發布上線都需要進行嚴格的管理,包括審批、SQL Scan 以及 Code Review,這個過程可能會讓團隊不堪重負。因此,我們需要進行分類分級管理,對關鍵任務進行強管控。如何確定哪個任務是關鍵任務?我們需要進行任務影響檢測,如果一個任務的下游涉及到 S 級報表或數據產品,那麼這個任務就需要走強制審核流程。
所以我們需要建立全鏈路的血緣關係,要能夠去做全鏈路的影響分析,並且基於這種分析結果,去制定分類分級的管理策略。
另外,數據沙箱功能也很重要,它需要在多個集群上運行,能夠在開發模式下讀取生產模式下的數據,同時又不能污染生產環境的數據,只能寫入其自己的環境。在實現這個功能時,需要解決在兩個環境隔離的情況下,如何讀取生產環境的數據,同時又不讓它寫回到生產環境的問題。這需要在兩個集群之間實現元數據的通信,網易是通過權限隔離等方式來實現。
第三個是做數據的測試和數據的驗證。我們在進行數據開發時,通常會從接收需求開始,然後驗證數據、編碼,最後發布上線。然而,這樣的流程往往帶來大量的後期問題和 bug,
因此,在開始編碼前,我們需要對上游業務系統進行數據探查。以我們的經驗來說,我們在進行數據探查時,發現了十幾個業務系統的 bug。因此,接到需求後,我們並不急於開始編程,而是對業務系統的數據進行深入探查。如果系統中的大量數據都是空值,那麼我們得出的統計結果將無實質意義。
當然,開發完成後,我們也需要對結果表進行檢查,看看結果是否符合我們對數據的預期。我們需要關注各種細節,例如枚舉值的分布、範圍、最大值和最小值等,以確保它們符合我們對數據的定義。
我們還需要對代碼進行審查。我們經常聽到同事們抱怨代碼寫得不規範或者質量差。特別是業務部門,他們可能會無視技術規範,提交一些複雜的 SQL 查詢,給系統帶來壓力。然而,簡單的抱怨並不能解決問題,我們需要採取有效的措施。我們採取的方法是提前掃描並攔截代碼。
我們可以設定一些規範,例如禁止全表掃描,必須指定分區。然而,我們不能僅僅告訴他們這些規則,我們還要強制執行這些規則,通過掃描他們的代碼,如果代碼不符合規範,我們就採取相應的策略。
如果他們的代碼觸發了我們設定的 S 級或 P0 級策略,我們可以直接攔截 SQL,而不是讓任何代碼都可以執行,從而避免對系統產生影響。這是我們在第一階段的主要工作,目標是提高數據開發團隊的效率和數據質量。
DataOps 2.0:開發治理一體化實踐
我們的工作有了明顯的成果,數據質量提高了不少。但是,業務團隊對此是否滿意呢?
數據應該是端到端的,一端是消費者,一端是供應者,我們的數據中台就是中間環節。我們還需要確保數據的消費能夠順暢無阻。
例如,如何幫助業務人員在大量的表中找到需要的數據,如何解釋缺失的數據,如何處理業務部門頻繁提出的數據質量問題,如何管理和控制大量的無用數據等。總的來說,我們每天都在處理大量的需求,但我們需要反思這些需求是否真正有用,是否真正被使用,而不是盲目地增加系統的計算和存儲負擔。
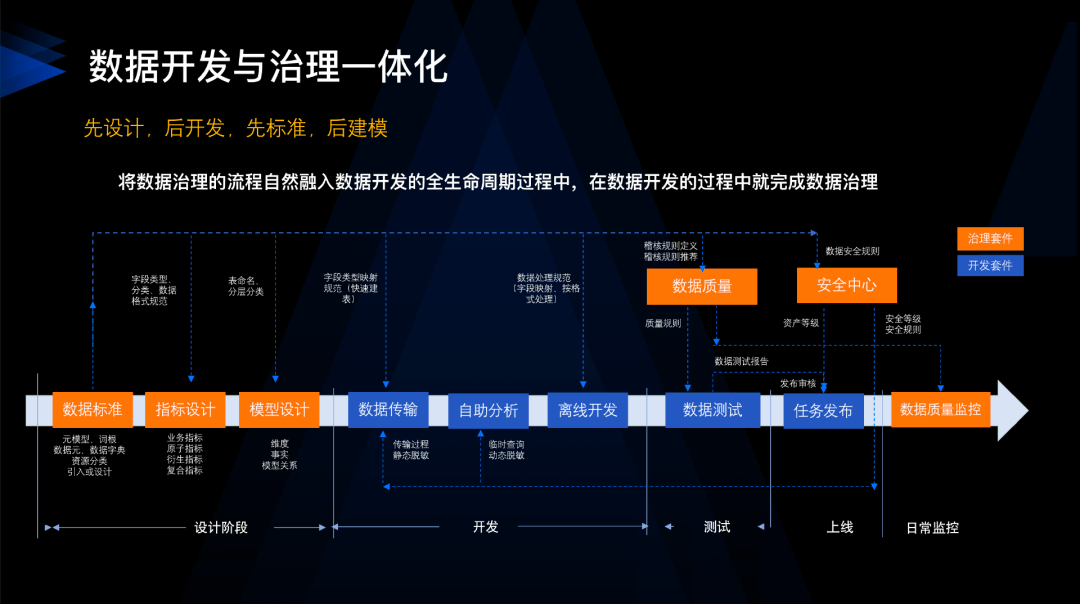
開發與治理一體化核心原則是「先設計後開發,先標準後建模」。許多人問我如何確保數據質量稽核規則的完備性。以我們原先在網易嚴選的數據質量稽核規則為例,這非常依賴於數據開發者對需求和業務的理解。如果開發者對業務理解深入,就能夠添加更多的稽核規則。然而,如果他們不了解業務,可能就不會添加規則。這就導致了核心表的數據質量稽核覆蓋率很低,完整性差,同一欄位在不同表中的稽核規則也不一致。因此,我們需要建立企業數據標準。
在編碼階段,我們希望儘可能減少對業務的理解,所以在設計階段就將業務相關的內容沉澱到數據標準中。以數據標準為核心,我們可以自動生成數據質量稽核規則,制定分類分級管理策略、數據脫敏策略、數據安全管理策略。只要設計階段做得好,後面的步驟就會更簡單。
我們的核心思想是 將數據治理前置,融入到數據開發的全生命周期中,希望能將數據治理的成本儘量前置到開發階段。
在設計階段,我們需要規範數據的命名、格式、值域質量和安全規範。參與制定數據標準的包括業務人員、需求方、數據架構師和數據產品。到了編碼階段,甚至可以將其外包給第三方公司,因為整個設計已經完成了一個閉環。
我們可以基於標準進行數據質量探查,生成事後的數據質量稽核規則,生成數據安全規則。數據標準實際上是企業最核心的元數據。這樣,我們才能實現從設計、開發到消費,再到運營的端到端運轉流程。
總而言之,有兩種模式:一種是先污染後治理,即不管三七二十一先上線,然後不斷修復問題;另一種是我們推崇的一體化模式,即在開發階段就建立數據標準體系。
在我們的實踐中,基於標準建模可以 提高規範性、效率和質量。原來我們需要做很多模型的評審、改造和重構,現在我們都是基於標準去做建模。另外,我們的數據質量問題也得到了大幅改進,尤其是數據質量稽核規則的完整度、覆蓋率,因為集合規則是由系統自動生成的,不需要開發者自己編寫。所以,一旦你的標準制定好,並與數據模型關聯,數據模型上的數據質量稽核規則就會自動生成。
從管理者的角度來看,我們更關心的是 數據的消費。簡單來說,我們需要有量化的數據來作為衡量標準。我們會從計算價值、規範、質量、安全和存儲的角度對各個業務線進行評分,以推動各個業務線更重視數據治理。我們需要這樣一個衡量標準,來評估各個業務線在數據治理中的工作,包括其在價值、規範和質量等方面的表現。比如,如果他的數據質量稽核規則覆蓋率很低,或者數據質量稽核規則經常出錯,都會扣除他的分數。
當我們說數據是端到端的,這個"端"包括四個環節,設計、開發、消費和運營。運營是非常重要的環節。但是在企業內部,數據人員可能是一個相對弱勢的群體。有時候,我們希望業務部門能使用數據,但業務部門可能會說他們沒有需求或不需要數據。因此,我們需要舉辦一系列賽事,讓企業內的每個人都能感受到數據的力量。比如,中國南方電網也採用了這樣的模式,通過比賽來提高員工的數據意識,這對推廣數據和平台非常有幫助。
DataOps 2.0:開發治理一體化實踐
最後,我想給大家介紹幾個外部客戶案例。
第一個是浙江電信。雖然他們已經做了很多年的數據治理,有數據標準和數據質量的稽核規則,但是這些標準和規則並沒有很好地打通。原因在於各個平台和工具之間完全不通。因此,他們重要的一步就是構建了開發、治理一體化的流程,從設計、開發、測試、上線到整個數據治理的標準化管控體系。
第二個案例是東北證券,他們做這個項目是為了推廣和使用數據。他們的數據質量存在很大的問題,甚至整個企業都沒有一個統一的數據資產門戶。所以,他們開始進行全平台的打通和改革。全面展開了規範化建設。
第三個案例是中國人壽海外業務,一家位於深圳的國有企業。他們面臨的問題包括效率極低,規範性差,平台割裂不統一,技術棧繁多,缺乏開發流程的管控,以及整體安全性管控的不足。為了解決這些問題,他們也採用了我們剛剛介紹的開發治理一體化流程。從業務探查、設計,到開發、測試、部署以及上線,他們成功地構建了完整的數據資產體系。
這樣的實踐不僅出現在網際網路行業,也在金融行業、製造行業,甚至許多國有企業積極探索和落實。深層次的背景在於,每個企業都需要充分使用數據,需要高頻度地使用數據,將數據作為生產過程中不可或缺的環節。有時候,如果數據的產出有所延遲,會有很多人在群里抱怨,這說明數據的重要性已經提高了,說明真的有很多人在用,很依賴它。最怕的情況是,當數據出問題時,卻沒人知道。
今天我分享的內容就到這裡。我希望大家在自己的企業或工作中能夠更好地實踐 DataOps 方法論,然後將它與企業中的數據開發流程、數據消費流程和數據運營流程良好地結合起來。
活動推薦
在 7 月 21 日即將開幕的深圳 ArchSummit 架構師峰會上,我們策劃了「DataOps、Data Fabric 等高效數據開發與服務模式」專題,邀請了大數據平台、數據治理方面的一線技術專家來分享他們的實踐經驗。