
簡介
熟悉我的文章的讀者可能還記得我以前報道《課本就是你所需要的一切》(https://medium.com/@mgunton7/the-impact-of-better-data-on-llms-46153ba26795)時的情景,這是微軟的一篇論文,展示了高質量的數據如何對模型性能產生巨大影響。文章中的新發現直接駁斥了模型必須巨大才能發揮作用的觀點。值得慶幸的是,這篇論文的研究人員一直在繼續他們的工作,最近又發表了一些讓我覺得非常令人興奮的東西。
他們發表的最新論文《Phi-3技術報告:手機本地運行的高性能語言模型》(https://arxiv.org/pdf/2404.14219)也許正解釋了相關的最大發現。
接下來,讓我們深入了解作者從Phi-2模型中改變了什麼,他們是如何進行模型訓練的,以及該模型在iPhone上是如何工作的。
關鍵術語
在深入了解上述模型的體系結構之前,首先需要了解幾個關鍵概念。如果您已經知道這些內容,請隨時跳到下一節。
第一個關鍵概念是模型的參數(parameters),它是指模型在訓練過程中學習的權重和偏差的數量。如果你有10億個參數,那麼你就有10億的權重和偏差來決定模型的性能。參數越多,神經網絡就越複雜。第二個關鍵概念是頭(head),它是指轉換器中的自注意機制所具有的鍵、值和查詢向量的數量。第三個關鍵概念是層(layers),它是指轉換器的神經網絡中存在的神經段的數量;其中,隱藏維度是典型隱藏層中的神經元數量。
此外,分詞器(Tokenizer)是一個軟體組件,它能夠把你的輸入文本轉換成一個嵌入,然後由轉換器使用它。詞彙大小(vocabulary size)是指在其上進行訓練的模型的唯一符號的數量。轉換器的塊結構(block structure)是指為特定模型選擇的層、頭、激活函數、分詞器和層規範化的組合。
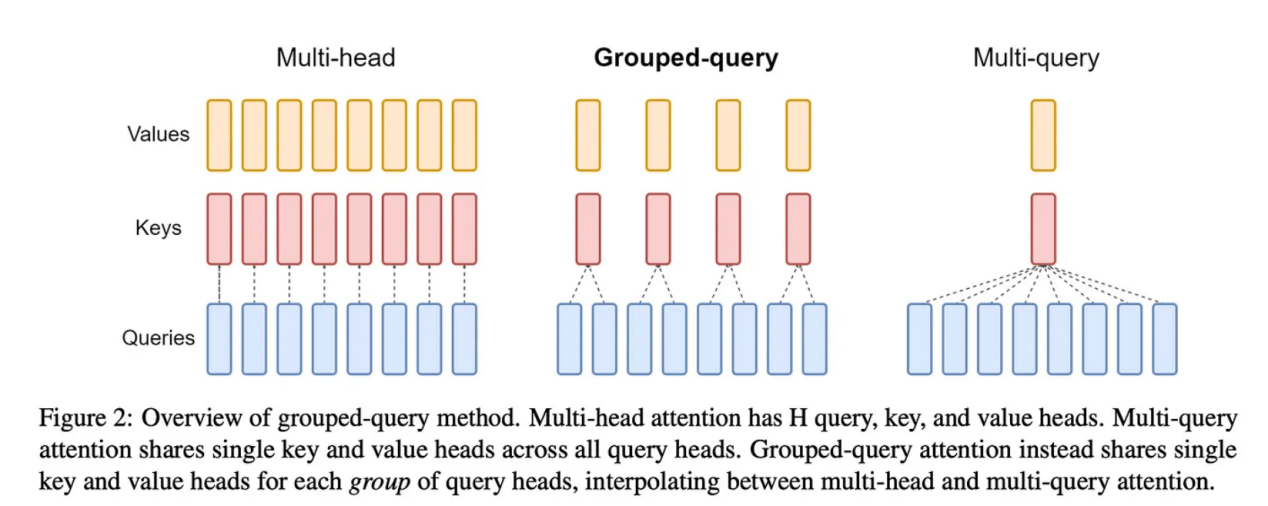
圖片來自於論文「GOA:從多頭檢查點訓練廣義的多查詢轉換器模型」(https://arxiv.org/pdf/2305.13245)
最後,還有一個重要術語是分組查詢注意力(GQA:Grouped-Query Attention),它是我們優化多頭注意力以減少訓練和推理過程中的計算開銷的一種方法。正如您從下圖中看到的,GQA採用了中間方法——我們採用了1:1:M的方法,而不是將1個值和1個鍵與1個查詢配對,其中許多比整個查詢都小。這樣做仍然可以從多查詢注意力(MQA)中獲得訓練成本效益,同時最大限度地減少我們隨後看到的性能下降。
Phi 3體系架構
讓我們從這個模型背後的體系架構開始講起。研究人員發布了3種不同的僅包含解碼器的模型,分別是phi-3-mini、phi-3-small和phi-3-medium,每種模型都使用了不同的超參數。
phi-3-mini
- 38億個參數
- 32個頭
- 32個層
- 3072個隱藏尺寸
- 4k大小的符號默認上下文長度
- 詞彙量大小為32064
- 權重以bfloat16類型存儲
- 使用3.3萬億個符號進行訓練
phi-3-small
- 70億個參數
- 32個頭
- 32個層
- 4096個隱藏維度
- 8k大小的符號默認上下文長度
- 詞彙量大小為100352
- 權重以bfloat16類型存儲
- 使用4.8萬億個符號進行訓練
phi-3-medium
- 140億個參數
- 40個頭
- 40個層
- 3072個隱藏尺寸
- 使用4.8萬億個符號進行訓練
現在,我們來比較一下它們一些差異。首先,phi-3-mini模型是使用典型的多頭注意力訓練的。雖然論文中沒有提到,但讓我懷疑的是,由於該模型的大小大約是其他兩個模型的一半,因此與多頭相關的訓練成本並不令人反感。當然,當它們擴展到phi-3-small時,使用的是分組查詢注意力,其中4個查詢連接到1個鍵。
此外,他們使phi-3-mini的嵌段結構儘可能接近LLaMa-2結構。這裡的目標是允許開源社區繼續他們對LLaMa-2和Phi-3的研究。這對於進一步理解塊結構的力量是有意義的。
然而,phi-3-small沒有使用LLaMa的塊結構,而是選擇使用Tiktoken分詞器,使用交替的密集注意力層和新的塊稀疏注意力層。此外,他們在這些模型的訓練數據集中添加了10%的多語言數據。
訓練和數據優化組合
與Phi-2類似,研究人員主要投資於高質量的數據。他們在生成數據來訓練模型時使用了類似的「教育價值」範式,選擇使用比上次多得多的數據。他們分兩個階段創建數據。
第一階段涉及尋找他們發現對用戶具有高「教育價值」的網絡數據。這裡的目標是為模型提供一般知識。然後,第二階段獲取第一階段數據的子集,並生成數據,教導模型如何進行邏輯推理或獲得特定技能。
這裡面的挑戰是,如何確保來自每個語料庫的數據組合適合正在訓練的模型的規模(即phi-3-small與phi-3-mini)。這就是「數據優化」機制背後的理念,在該機制中,您提供給LLM進行訓練的數據為其塊結構提供了最佳能力。換言之,如果你認為數據是訓練一個好的LLM的關鍵區別,那麼通過數據找到正確的技能組合來展示模型與找到好的數據同樣重要。研究人員強調,他們希望該模型具有比知識更強的推理能力,從而從第二階段語料庫中選擇的數據比從第一階段語料庫中更多。

論文(https://arxiv.org/pdf/2404.14219)中的圖2強調了數據優化的潛在關係
有趣的是,當他們用與訓練phi-3-small大致相同的數據混合物訓練phi-3-medium時,他們注意到從7B參數到14B的改進遠比從3.8B到7B的改進有限。作者懷疑這不是塊結構的限制,而是他們用來訓練phi-3-medium的數據混合。
後期訓練
該團隊使用監督微調(Supervised Fine Tuning:SFT)和直接偏好優化(DPO:Direct Preference Optimization)技術來改進訓練後的模型。有興趣深入了解DPO的讀者可以從連結https://medium.com/towards-data-science/understanding-the-implications-of-direct-preference-optimization-a4bbd2d85841處查看我的博客文章。監督微調是一種遷移學習方法,我們使用自定義數據集來提高LLM在該數據集上的能力。作者使用SFT來提高模型在數學、編碼、推理和安全等不同領域的能力。然後,他們使用DPO進行聊天優化,引導其遠離他們想要避免的回應,轉向理想的回應。
正是在這個階段,作者將phi-3-mini的上下文窗口從4k個符號大小擴展到128k個符號。他們把用來做這件事的方法命名為「長繩索(Long Rope)」。作者聲稱,這兩種上下文類型之間的性能是一致的,考慮到上下文長度的巨大增加,這是一件大事。如果有足夠的興趣,我將再單獨發表一篇關於該論文中相關研究成果的博客。
手機使用場景下的量化
儘管上述這些模型很小,但要讓這些模型在手機上跑起來,仍然需要進一步最小化。通常,LLM的權重被存儲為浮點形式;例如,Phi-3的原始權重是bfloat16,這意味著每個權重占用內存中的16位。雖然16位可能看起來微不足道,但當你考慮到10⁹數量級大小的模型中的參數時,您就會意識到每個額外的位加起來的速度是怎樣的。
為了解決這個問題,作者將權重從16位壓縮到4位。其基本思想是減少存儲每個數字所需的位數。作為一個概念性的例子,數字2.71828可以濃縮為2.72。雖然這是一種有損操作,但它仍然可以捕獲大部分信息,同時占用的存儲空間要少得多。

論文(https://arxiv.org/pdf/2404.14219)中的圖1內容
作者在安裝A16晶片的iPhone上運行了上述量化內容,發現它每秒可以產生多達12個符號。相比之下,運行LLaMa-2量化4位的M1 MacBook的運行速度約為每秒107個符號。我見過的最快的符號生成(Groq)以每秒853.35個符號的速度生成符號。鑒於這僅僅是一個開始,我們能夠以如此之快的速度看到這款模型在iPhone上生成的符號,這一點值得注意。另外,推斷速度方面似乎只會更快一些。
將Phi-3與搜尋引擎配對
小型模型的一個局限性是它在網絡中存儲信息的位置較少。因此,我們發現Phi-3在需要廣泛知識的任務方面不如LLaMa-2等模型執行得好。
論文作者建議,通過將Phi-3與搜尋引擎配對,該模型的能力將顯著提高。如果是這樣的話,我認為檢索增強生成(RAG)很可能會繼續存在,成為幫助小型模型和大型模型一樣具有性能的關鍵部分。

論文(https://arxiv.org/pdf/2404.14219)中的圖4強調如何搜索能夠提高Phi-3性能
結論
如今,我們看到了機器學習領域已經出現了高性能的小型模型。雖然訓練這些模型在很大程度上仍然依賴於高性能硬體,但對它們的推理正日益普及開來。這將引發一些有趣現象的出現。
首先,可以在本地運行的模型幾乎是完全私有的,允許用戶提供這些LLM數據;否則,他們可能會覺得在網際網路上發送不舒服。這為更多的應用場景打開了大門。
其次,這些模型將推動移動硬體的性能提升。因此,我希望在高端智慧型手機上看到更多的片上系統(SoC),尤其是CPU和GPU之間具有共享內存的SoC,以最大限度地提高推理速度。此外,與該硬體具有高質量接口也是至關重要。在消費硬體領域,任何新的硬體上市都可能需要像Apple Silicon的MLX這樣的庫。
第三,正如論文所展示的,在LLM領域,高質量數據在許多方面都可以勝過更多的網絡複雜性;因此,人們一方面要尋找高質量數據,同時生成高質量數據的競爭也會不斷加劇。
總之,當前我們正處於一個激動人心的發展時期。