文|光錐智能,作者|郝鑫,編輯|王一粟
「世界上最高的山是什麼山?」
雲知聲創始人兼CEO黃偉仍清楚地記得,十年前他用語音提出的第一個問題。答案播放出來的那一刻,黃偉第一次體會到創業的成就感。
今年2月底,山海大模型雛形初現,用同樣的問題測試,黃偉一瞬間感覺好像穿越回了十年前,那座「最高的山」正在招手呼喚他。
「去年12月第一次看到ChatGPT,正是我創業十年最灰暗的時刻。而現在站在發布會舞台上,剩下的只有緊張、興奮和自豪。」黃偉慶幸,自己再次搭上了AI下個十年的快車。
5月24日,雲知聲正式發布「山海大模型」,現場實測十大核心能力,具體包括:語言生成、語言理解、知識問答、邏輯推理、代碼能力、數學能力、安全合規等7項通用能力,以及插件擴展、領域增強、企業定製等3項行業落地能力。
值得一提的是,除了通用能力的演示,一向重視「工程化」的雲知聲也比較明確地提出了落地能力的實現路徑。這讓大模型的落地更加實際,不是空中樓閣。
而在更重要的行業應用層面,雲知聲則仍然堅持此前提出的「U+X戰略」,賦能醫療、智慧物聯、銷售、知識管理、教育等千行百業。
在雲知聲最為重要的落地場景之一——醫療領域,黃偉透露,山海大模型在臨床執業醫師醫學考試中拿到了511分,滿分600分,考生平均分為365。「在醫療領域,山海大模型已經超越了GPT-4的中文水平。」
得益於此前在Ttransformer模型方向的發力,以及從2016年對醫療領域的深耕,雲知聲從去年12月開始組建AGI團隊,「閉門修煉」6個月後,就拿出了一個在通用能力方面與國內大公司打平,在行業大模型超越GPT-4中文水平的成績。
黃偉並不滿足這樣的成績,給雲知聲定下了年內的目標,「年內通用能力比肩ChatGPT,並在醫療、物聯、教育等多個垂直領域能力超越GPT-4。」
雖然2個月近20個大模型發布中「有李逵也有李鬼」,但一流AI公司的技術水平可以靠時間接近GPT-4成為了行業共識。當技術拉齊後,大模型正在打響一場「行業」爭奪戰。
01 把通用能力用起來
在通用能力上,雲知聲山海大模型順利通過了語言理解、推理能力等一系列測試。
首先,在對中文的理解方面,山海大模型更接近「中國人的體質」,可以精準地理解中文6級水平的繞口令「行的人,干一行行行行,行行都行」中每個「行」的意思,還能給出單獨的解釋。知道八大山人是畫家的名號,孫悟空和齊天大聖是同一個人。可以說,山海大模型對中文的理解達到了百科字典的水平。
不僅如此,山海大模型還具備邏輯判斷和計算推理能力。例如,可以識破「所有貓都愛吃魚,所以愛吃魚的動物都是貓」這類偽三段論邏輯,以及「小明爸爸姓王,問小明姓什麼」這類基本常識問題。
而在計算能力中,山海大模型可以立即給出雞兔同籠這類簡單問題的答案和解題過程,也能夠根據指令當場編寫代碼。在涉及開根號等複雜的數學運算上,山海模型也沒有拉胯,過程清楚、答案正確。
總體來看,與國內各家大模型相比,山海大模型雖然沒有展現圖文生成等多模態的能力,但關鍵的NLP(自然語言處理)表現仍在頭部水平。
光錐智能盤點了已發布大模型的公司發現,隨著技術的不斷更新疊代,各家公司在文本生成、知識問答、語言理解、邏輯推理等各項通用能力上的差距正在變得越來越小,甚至有了同質化的趨勢。
所以,攻克大模型的技術難關只是第一步,如何用起來才是接下來的關鍵。
ChatGPT驚艷全球後,OpenAI隨即拋出的一顆驚雷,就是宣布向所有ChatGPT Plus用戶開放聯網功能和70多個第三方插件,插件覆蓋了衣食住行、社交、工作以及學習等方方面面。
面對千行百業,沒有一家公司能夠獨立吃下所有場景。民生證券報告稱:「OpenAI正沿著類蘋果模式的『終端+平台+生態』,邁向高於作業系統的戰略地位。」
雲知聲也有同樣的思考路徑,但不同的是,更希望利用插件,將合作夥伴的能力集成進來。用了計算器插件,山海大模型就實現了複雜計算的能力;用了搜尋引擎插件,就能幫用戶實時查天氣、查球賽結果。與ChatGPT一樣,給大模型按上了插件就裝上了「外掛」。
黃偉表示:「大模型的通用能力並不能解決所有問題,還有說胡話的風險。特別是在醫療、汽車、物聯一些容錯率低的專業場景中,通用能力就顯得不那麼夠用,所以才要引入大量的插件來推動應用落地,做大模型的黃金搭檔。」
雲知聲也給AI公司做大生態提供了借鑑思路,面對很多垂類的行業場景,AI公司一方面可以自己做一些插件去開放給行業客戶,集成到產品里。另一方面,也可以讓客戶自己做插件開發,共同深入場景。
02 成為行業專家
通用能力的提升,在行業場景的實際落地方面,還遠遠不夠。這就要求大模型們,不僅成為AI領域的「本科全才」,更要成為特定領域中的「博士生」甚至「博導」。
即使通用能力強如ChatGPT,在醫療等特定領域的專業度也遠遠未達到可用的水平。例如,對一手術過程的描述,ChatGPT給出了一個完全錯誤的答案。可以說,一旦涉及到核心的診療過程,ChatGPT目前只是一個「庸醫」。
「如果把GPT-4比作一個不偏科,每門都能考到80分的學生;我們要做的,則是一個可以在某一兩門學科,考到95分甚至更高的學生。」黃偉在採訪中說道。
而這恰恰是眾多行業大模型的機會。從實際問題和產業應用出發,沉澱垂直行業經驗,AI公司就能建立自己在特定領域的壁壘。
從這個角度而言,在AI 1.0時代積累下行業能力的AI公司,擁有更大的機會。
2016年,醫療+AI行業還猶如一片空白地帶,彼時,AI企業們還在找尋合適的降落姿勢。
以語音技術起家的雲知聲,抓住了醫生病歷記錄效率低下這個痛點,以語音電子病歷錄入打開了醫療賽道的突破口。
為了能夠做到精準識別,雲知聲為醫院做了深度定製服務,根據不同科室、不同病種整理病歷資料,運算出關鍵詞句語料,為40多個臨床和醫技科室提供分場景支持,以適應醫院不同科室實際的使用需求。
經過專業數據優化後,雲知聲在醫療領域的優勢十分明確,其語音識別準確率超95%,個別科室的語音識別率超98%。醫生減負效果明顯,可以使醫生的錄入效率提升40%,每天節省1.5-2個小時時間。
然而,僅從一個單一效率工具切入並不夠。
三年磨一劍,2019年,雲知聲公布了「醫療+AI」的戰略,從電子病歷場景出發構建起了醫療產品體系。除「醫療語音交互解決方案」外,針對診療過程的診前、診中、診後不同場景,雲知聲還推出了導醫機器人、智能病歷生成系統、智能病歷質控系統以及智能院後管理解決方案等產品。
此外,基於對場景的理解,雲知聲在醫療垂直領域建立起了知識圖譜,圖譜覆蓋了症狀、體徵、疾病、手術,檢查檢驗,藥品等七大類實體,共計132萬個,對應醫學術語334萬;包含十大類實體關係,共計757萬實體關係。2017年建立至今,該知識圖譜仍在更新疊代中,這成為雲知聲核心壁壘之一。
黃偉介紹知識圖譜在大模型訓練中發揮了重要的作用,「行業大模型訓練有三個主要的數據來源,一是雲知聲多年沉澱下來的優質醫療數據,預訓練階段可以加強大模型的知識和語言能力;二是在醫療行業積累的問題解決數據,這部分可以拿來做微調;三是知識圖譜,靠它嚴謹的知識來校驗數據和訓練結果。」
在高質量質量知識圖譜數據之上,實現了數據到場景的全鏈條打通,雲知聲旗下的醫療產品從語言電子病歷、語音助手這類效率工具,進化為了病歷文書質控、醫保支付審核一類的決策支持工具。
在大模型的加持下,雲知聲也完成了從AI助手到AI專家,再到AI導師的角色升級。對比從前,所能抵達的場景更加厚重,能觸及的核心技術更多,行業know-how的經驗再次更新沉澱下來。
如果說,雲知聲在醫療行業的扎深是一家AI公司如何深入到行業的典型,那麼其在物聯網領域的拓展,則證明了一家AI公司如何能把技術變成靠標準化的產品,從而打開行業廣度的生意經。
2015年,雲知聲啟動了AI語音晶片項目,並提出「雲-端-芯」一體戰略。一方面把在垂直行業積累的AI技能放在雲端,一方面通過晶片去賦能設備端的邊緣計算能力,進而把雲端的算法能力向設備端進行輸出。
通過自研晶片的方式將算法集成在晶片模組中,這不僅形成了相對標準化的產品,還讓雲知聲實現了產品成本的降低。「標準化+降本」,才能大規模應用到智慧家居、車聯網等場景。
同時,雲知聲這些年還搭建了厚重的中台能力。物聯中台發揮集中調配、匯總信息的功能,實時管理設備、人員、服務等各項因素,最終通過語音交互輸出指令反饋。
而到了大模型時代,面向智慧物聯場景,會有什麼樣的進階呢?
ChatGPT已經讓業界看到,人人都能擁有一個AI助手即將成為現實。「未來將全線升級智慧物聯核心產品,與山海大模型深度結合,塑造出一個真正的隨身管家:從只能進行指令交互升級為類人對話,真正聯動IoT生態和服務。」黃偉在發布會上表示。
「與全場景自然語言交互相比,搜素引擎的市場就非常小了。」一位曾在語音等AI領域深耕20年的創始人曾對光錐智能表示,萬物智聯的自然交互,才是更廣闊的市場。
「大模型發布後,無論是汽車、智能家居、酒店等各個潛在客戶,已經迫不及待地在跟我們要方案了。」黃偉透露。
十年間,雲知聲AI實現了三級跳,從第一階段的AI三駕馬車、「雲端芯」戰略,到第二階段的以超算中心、知識圖譜等構成的規模化AI技術戰略,和開放平台+智慧物聯/智慧醫療的「U+X」市場戰略,每一個階段都緊跟技術和市場的變化。
再到如今的AGI時代,雲知聲也迎來了自己的GPT時刻。在技術上,不僅擁抱基礎大模型,也在工程化上利用指令調優+反饋強化,讓大模型不斷疊代提升;另外,也在多知識/多模態,以及跨語言/模態方面積極布局,為增量需求拓展能力。在市場策略上,依然堅持「U+X」,實現AGI+Industry生態加速。
在此次發布會上,除智慧醫療、物聯場景外,雲知聲亦在教育、銷售場景、知識管理等場景上儲備下了能力,準備迎接更多行業的升級需求。
03 行業爭奪戰打響,雲知聲如何比拼?
自3月以來,國內已有20多個玩家狂奔入局。從文心大模型到山海大模型,國產大模型之戰迎來中場戰事,從比拼「通用」進階到了比拼「行業」。
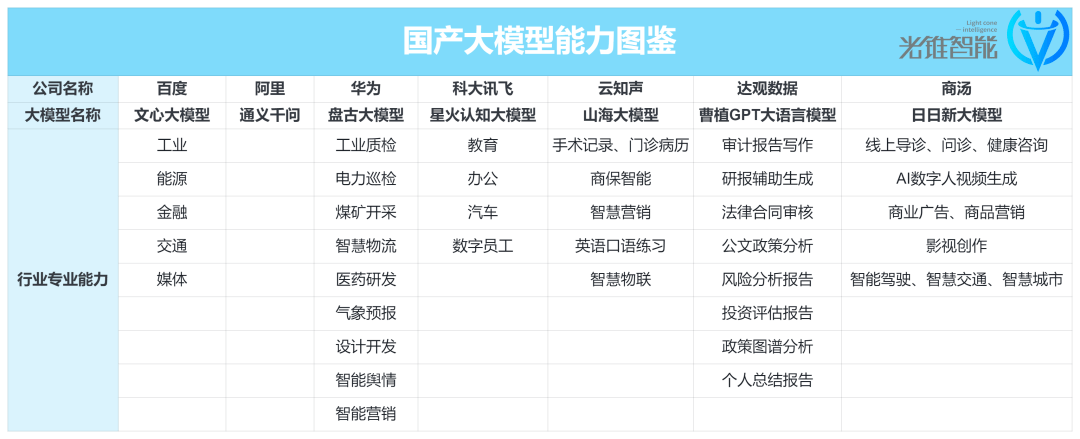
據不完全統計,在國內發布的大模型中,行業大模型占比超過60%,各家AI公司大模型已經開始向工業、金融、醫療、營銷、智慧物聯等多個領域滲透。比如,百度在發布文心一言後,在全國各地陸續舉辦了多場行業大模型的推介會,涉及工業、能源、媒體、金融等領域;而阿里雲雖然沒有發布單獨的行業大模型,但也強調維度更垂類的企業大模型。「未來每一個企業在阿里雲上既可以調用通義千問的全部能力,也可以結合企業自己的行業知識和應用場景,訓練自己的企業大模型。」
相比巨頭在技術上拼參數,在市場上拼生態,雲知聲這樣的小巨頭,也有自己從本質出發的思考。
「ChatGPT將人工智慧研究的核心帶回到語言本身,而語言其實是人類智能的一個核心載體。」雲知聲董事長梁家恩認為,這是一個從專用AI轉向通用AI(AGI)的突破口。」
但轉向通用AI,並不能盲目的擴大訓練參數。這是因為,雖然在優質數據規模足夠大情況下,模型越大效果越好,但訓練成本也越高。
基於AI 1.0時代在專用AI方面的積累,雲知聲計劃先將模型做到六七百億參數,做出湧現效果,然後以這個參數規模,提升優質數據規模和大模型效果,再做千億以上參數來提高大模型性能。
雲知聲堅信,通往AGI的路不只有一條。
「除了用大力出奇蹟去做大模型,也可以用更高質量的『數據+規模』當適當的數據參數,做行業『中模型』。」黃偉表示,雲知聲目前正在兩條腿一起走路。今年Q3雲知聲會發布對標GPT-3.5的「山海2.0」,數據參數也將達到千億級。而在Q3,雲知聲的「中模型」也即將發布。
既然要做中模型,在行業爭奪戰中,又回到了上個階段中對行業深耕的過程。
縱觀整個中國市場的行業大模型玩家,首先基於1.0階段積累的行業經驗不同,各家深扎的場景也不同。現階段,想要橫跨多個行業不太現實,無論是頭部大廠還是中小公司都可以有自己的壁壘。
其次,即使是進入同一行業,每家公司瞄準的方向也不同,細分領域競爭更具多樣化。如同樣在醫療領域,雲知聲將語義識別的優勢運用在了門診病歷撰寫、手術報告生成上,而商湯則將重點放在了線上問診、諮詢上。
而在真正的行業應用落地時,還要考慮實際成本。
在AI 1.0階段,被調侃「有多少人工就有多少智能」的數據標註情況,將被自動化標註逐步替代。相對於GPT訓練中需要的45T數據,以前的AI訓練數據量如同九牛一毛。在數據量較小的情況下,還能做到分離標註,而現在數據訓練過程完全自動化,根本無法標註。於是,需要通過人類生成反饋的技術,替代傳統數據標註。
另外,則是數據訓練成本。雲知聲認為,大模型訓練成功後,以目前的算力成本,可能需要把大模型參數量通過蒸餾技術壓縮10倍才能滿足實時性和規模化應用要求,這要視具體應用場景而定。雲知聲在做BERT模型時,就通過模型蒸餾提速近百倍,而實際性能損失很小。「就像打擊索馬利亞海盜,不能每次都開著航母過去。」梁家恩稱。
04 技術撬動行業價值
縱觀國產大模型,目前整個行業依然在非常早期,即使如馬斯克所言,中美技術的差距有12個月,但放眼到未來20年的長期競爭中,這開頭的100米或許並沒有那麼重要。
回顧1.0階段,AI公司花費了6年的時間實現了價值跨越。
科大訊飛營收從2017年的54.45億,一躍增長至2022年的188.20億,對應28.15%的復合增速;商湯的營收從2018年的18.5億,增長至2022年的38.09億,收入也實現了翻倍。
上個階段,AI技術實現了舊業務的提效、新業務的增長,最終達成AI公司營收、市值的雙增。進入2.0時代,這個邏輯依然成立,只不過2.0階段可能釋放的價值會更大,用的時間也會更短。
黃偉判斷,在新時代有兩件事目前是已經確定的。首先,AI公司具備了更強的技術能力後,就能更好地滿足客戶需求,繼而也能更容易地推動商業化落地。其次,客戶強烈的需求會拉動整個市場空間增長,但高准入門檻又會將一部分公司拒之門外,最後能在市場分蛋糕的是那些實力過硬的玩家。
回顧雲知聲11年的創業歷程,保持技術的領先性和符合時代的市場戰略都同等重要。「勤勞勇敢」的中國AI公司,面對新技術和新市場的熱忱,會趟平所有可見的困難。
正如黃偉所信仰的,「所愛隔山海,山海皆可平」。