焦點分析|理想的「端到端」:比行業進了一步,比特斯拉還少一步
文丨李安琪
編輯丨李勤
儘管特斯拉從來沒有公開過FSD v12版本的技術魔法,但國內確實已經掀起了「端到端」自動駕駛的學習熱潮。
作為智駕追趕者的理想汽車,也不例外。7月5日,理想就首次公開了其端到端自動駕駛技術架構。
該架構主要由端到端模型、VLM視覺語言模型、世界模型三部分共同構成。同時,理想還開啟了新架構方案的早鳥測試計劃。
有行業人士指出,跟華為、小鵬的分段式端到端方案相比,理想方案的方案更為激進,可視為分段式端到端的下一站。「從傳感器輸入到行駛軌跡輸出只經過一個模型。」理想智能駕駛技術研發負責人賈鵬在發布會上介紹道。
此外,在新技術架構方案中,理想還融合了視覺語言模型、世界模型,分別幫助智駕解決複雜的城市道路挑戰,以及端到端方案測試、驗證問題。
理想智能駕駛負責人郎咸朋在社交媒體上表示,端到端方案從去年下半年就在內部孵化並啟動預研,目前已經完成了模型的原型驗證和實車的部署。
據36氪了解,目前理想針對端到端搭建了一個超300人的研發團隊,在北京進行封閉式開發,預計年內拿出階段性成果。
不少業內人士都表示,智駕行業技術路徑切換得太快了,去年行業的主流方案還是輕高精地圖的城區智駕,今年就要追擊端到端。這也是車企智駕團隊的研發難題,上一代方案還沒完全落地,下一代方案又將到來。
但在技術切換的空隙,也讓過去智駕晚投入的玩家如理想等,有了趕上的機會。至少在端到端方案上,理想與同行站在了相近起跑線上。
比特斯拉後退一步,比「分段式端到端」更進一步
端到端自動駕駛方案,最先由特斯拉引領。在喂給AI神經網絡足夠多、足夠高質量的數據前提下,智駕系統能夠自主學習人類的駕駛方式。用特斯拉的話來說,「端到端」就是「輸入圖像,輸出駕駛指令」。
比起傳統智駕方案,端到端有更高的技術天花板。過往智駕方案以工程師制定的規則為基礎,依靠感知、決策、規劃等模塊配合來實現智駕。
但每個模塊相互獨立,模塊間的信息傳遞接口由工程師來定義,這就造成了信息流轉的缺失與誤差。一方面是影響整體方案的效果,二是依賴人力應對無盡的corner case,並非長久之計。
端到端看起來是一劑良藥。特斯拉FSD v12也憑藉端到端方案,大殺四方。華為、小鵬、蔚來、Momenta、商湯、元戎啟行等,都試圖跟上特斯拉的端到端步伐。
而作為國內首個公開端到端技術方案的車企,理想的方案也有值得分析與借鑑之處。
理想提出的「One Model」結構,輸入端是傳感器信息,輸出端是行駛軌跡。不過這個思路並非理想獨有。此前,商湯絕影提出的端到端自動駕駛方案UniAD也是類似思路,該模型還拿到了2023年全球頂級計算機視覺會議CVPR的最佳論文獎。
理想認為,由於中間沒有規則介入,其端到端模型在信息傳遞、推理計算、模型疊代上更有優勢,可以擁有更強大的通用障礙物理解能力、超視距導航能力、道路結構理解能力,以及更擬人的路徑規劃能力。
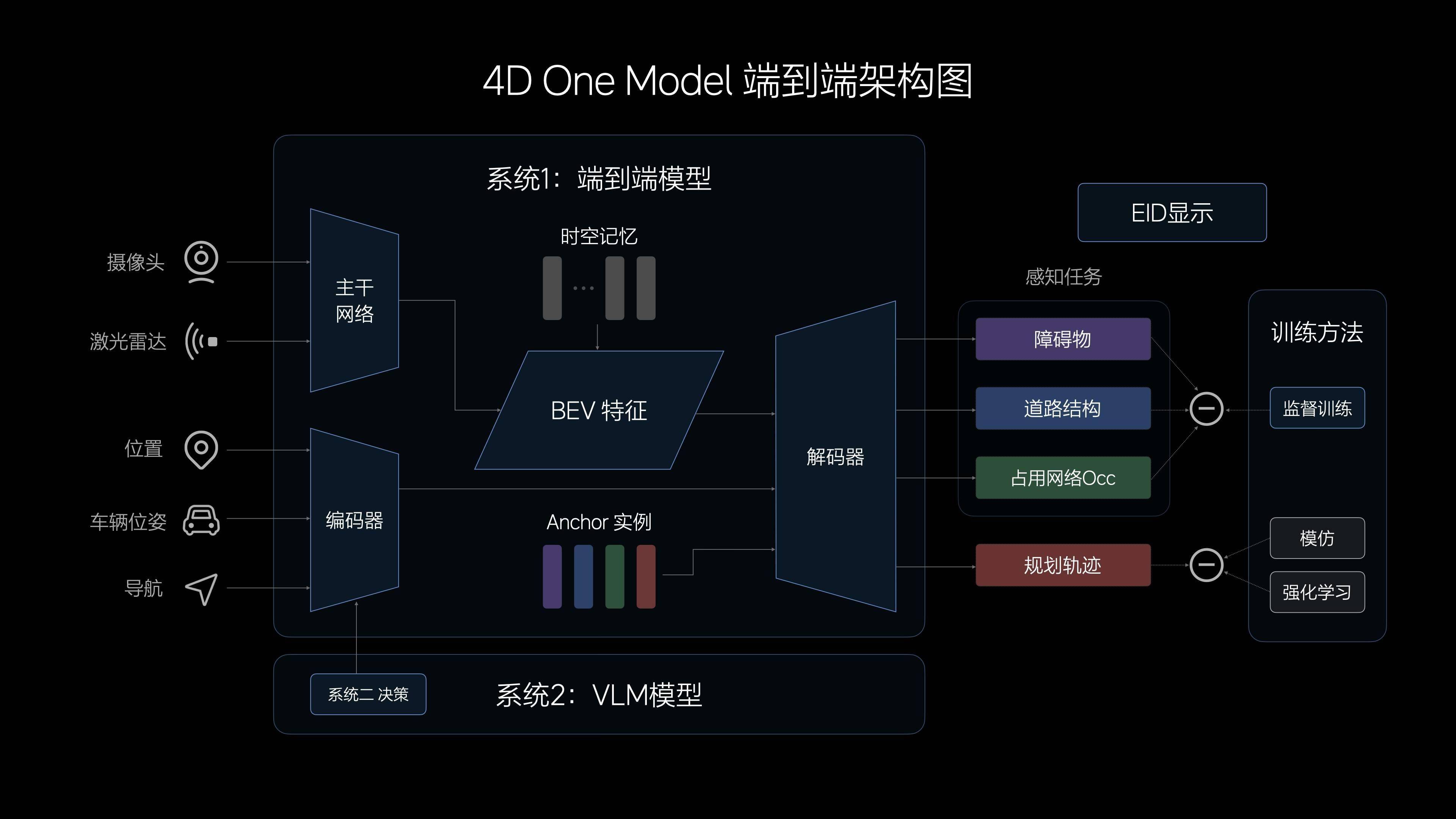
圖源:理想汽車
從技術架構上看,理想比華為、小鵬的分段式端到端更近一步。此前華為的提出的端到端方案,仍有感知大網和預決策規劃大網。小鵬的端到端方案則分為神經網絡感知XNet、規控大模型XPlanner+大語言模型XBrain三段。
不過有行業技術人士告訴36氪,One Model方案的訓練也有很大挑戰。「以前訓練規控,會假定感知模塊是完美的,兩者獨立訓練,出了問題也比較容易定位,但端到端方案是感知和規劃一起訓練,訓完容易出現負優化的情況。」
而跟特斯拉號稱「輸入圖像、輸出控制」的端到端方案相比,理想的方案顯然還少了一步。
目前,在國內,各家的端到端思路,最多也就從感知端到預測決策端,最終的控制執行模塊,依然由工程師的手寫規則來兜底。
視覺語言模型,幫助智駕理解世界
理想端到端方案,更有意思的地方還在於,提出了快思考與慢思考。這點主要是受諾貝爾獎得主丹尼爾·卡尼曼的「快慢系統理論」啟發。
在理想看來,快系統,即系統1,善於處理簡單任務,更像人類基於經驗和習慣形成的直覺,足以應對駕駛車輛時95%的常規場景。
慢系統,即系統2,則是人類通過更深入的理解與學習,形成的邏輯推理、複雜分析和計算能力,在駕駛車輛時用於解決複雜甚至未知的交通場景,占日常駕駛的約5%。兩個系統的,可以分別確保大部分場景下的高效率和少數場景下的高上限。

圖源:理想汽車
借鑑這套理論,理想汽車打造了自動駕駛技術架構。系統1由端到端模型實現,實現快速響應,端到端模型接收傳感器輸入,並直接輸出行駛軌跡用於控制車輛。
而系統2由VLM視覺語言模型實現,其接收傳感器輸入後,經過邏輯思考,輸出決策信息給到系統1。雙系統構成的自動駕駛能力還將在雲端利用世界模型進行訓練和驗證。
用理想的話來說,VLM模型對物理世界的複雜交通環境具有強大的理解能力。不僅可以識別路面平整度、光線等環境信息;還具備更強的導航地圖理解能力,可以配合車機系統修正導航;還能理解公交車道、潮汐車道和分時段限行等複雜的交通規則,在駕駛中作出合理決策。
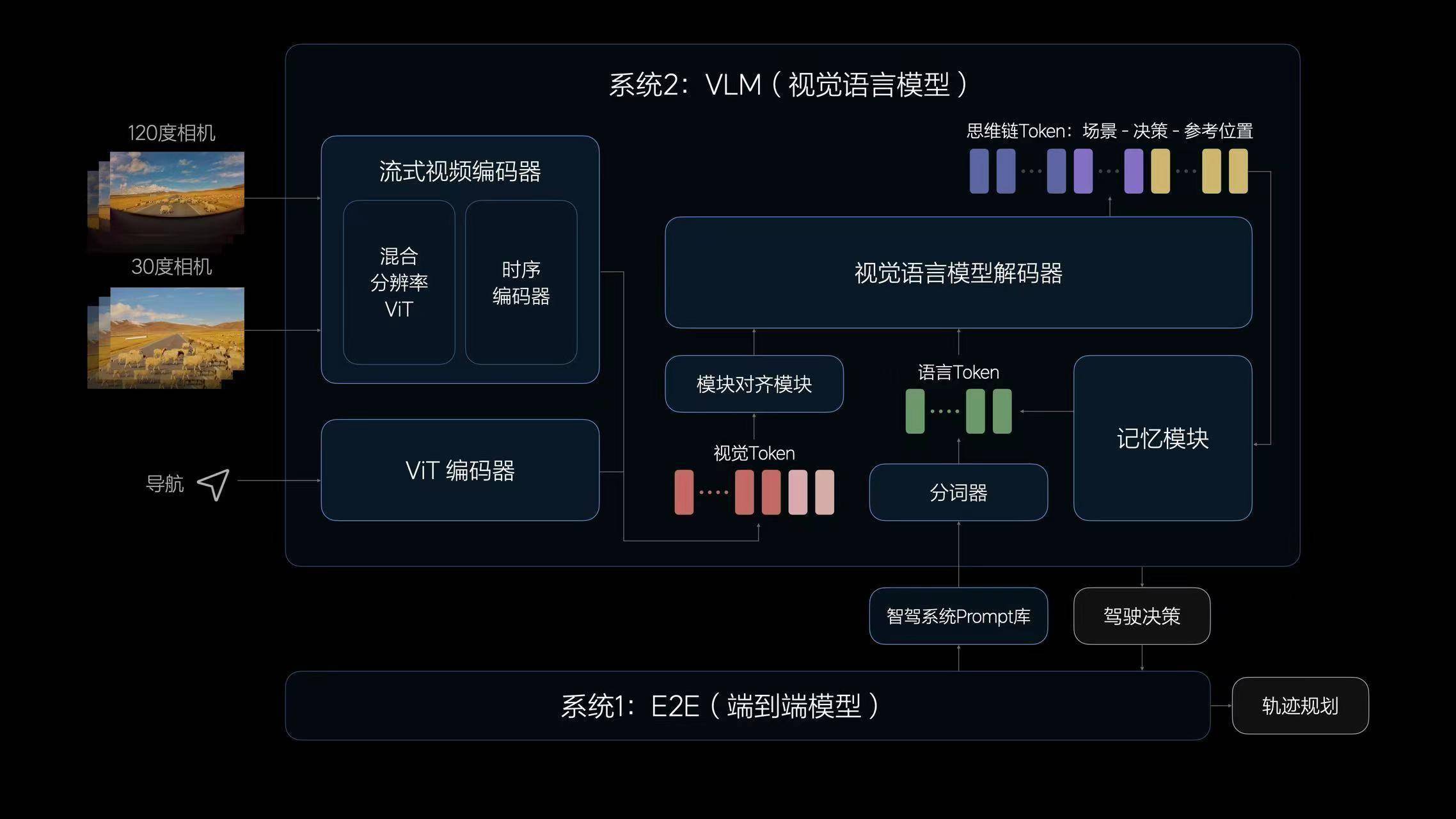
圖源:理想汽車
舉個例子,比如車輛前方遇到坑窪路面的時候,系統2就會給出具體駕駛建議,將車速從40公里/小時降到32公里/小時。小鵬的大語言模型XBrain也有類似能力,可以識別待轉區、潮汐車道、特殊車道、路牌文字等指令。
作為視覺語言模型,理想的VLM模型參數量達到22億。當然,這跟ChatGPT等大語言模型的數百上千億參數無法相提並論。
但理想希望將端到端+VLM雙系統同時部署在車端晶片上。為了將雙系統部署到車上,理想智駕高級算法專家詹錕也介紹,最早VLM模型在車端的推理時間長達4.1秒,經過不斷優化後,目前整體推理性能已經優化了13倍,推理只需0.3秒。
目前,行業主流、已經量產、能夠支持端到端方案的智駕晶片只有特斯拉的HW3.0晶片與英偉達的Orin,理想搭載的正是英偉達Orin。不過有行業人士告訴36氪:「像理想這種延時,20億級的模型參數量算是比較極限了。後續如果要上更大模型,可能就需要Thor(英偉達下一代晶片,算力超1000Tops)了。」
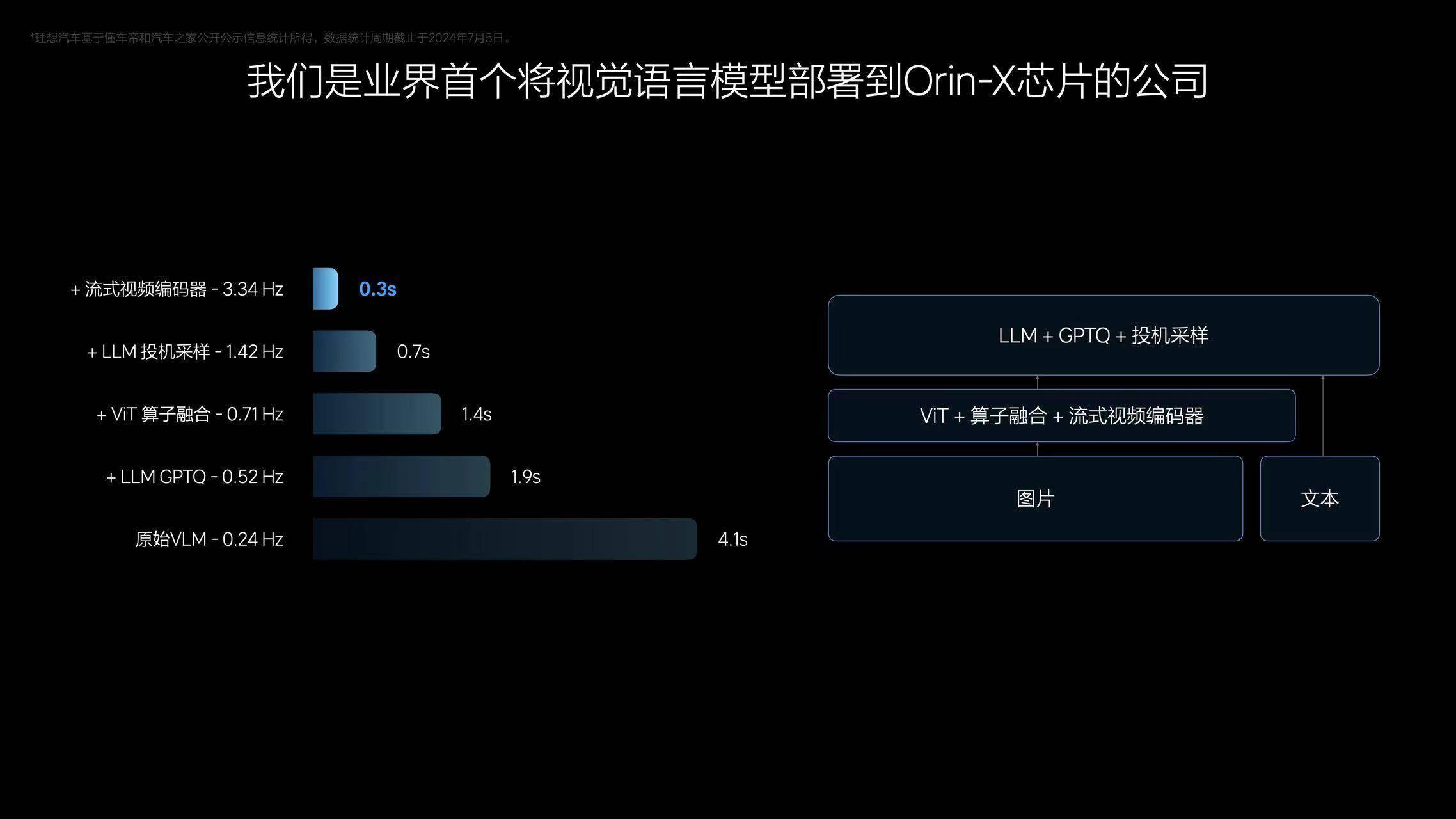
圖源:理想汽車
此外,理想還介紹了端到端方案的測試和驗證方法。理想介紹,行業過往主要通過虛擬仿真、重建仿真等方式來對智駕做仿真測試。而隨著生成式AI的出現,生成式仿真也正成為智駕行業的一大趨勢。
理想結合了重建仿真和生成仿真兩種技術路徑,為端到端的測試驗證搭建了一個世界模型。理想稱,重建和生成兩者結合所構建的場景,可以為自動駕駛系統能力的學習和測試創造了更優的虛擬環境。

圖源:理想汽車
不過,理想的端到端+VLM方案還難以真正立刻交付給用戶。7月,理想將推送給用戶仍然是基於分段式端到端的無圖NOA方案,能在全國道路開啟。
當下,國內高階智駕面臨商業與技術的雙重挑戰。一方面是穩步推進的大規模智駕體驗,保證用戶口碑;另一方面則是跟上端到端等技術浪潮。
這需要車企智駕團隊同時具備極強的工程落地、技術判斷能力,保證用戶體驗的同時,持續追趕前沿技術。這對理想是挑戰,對華為、對小鵬、蔚來,以及一眾智駕供應商而言,同樣如此。